







链接:
- https://blog.csdn.net/laozaoxiaowanzi/article/details/107531638
- https://blog.csdn.net/u010420283/article/details/114483073
可以说这篇博客是对Google量化白皮书的完整解读,篇幅较长,可以收藏慢慢阅读。笔者在翻译的基础上,又补充了帮助理解的内容,但量化的技术点很多,并不限于此篇,且文中有个别点笔者不能完全吃透,故写得不是很详细,望看此文的你可以帮忙指出文中错误且与我一起交流讨论。
一、什么是量化?为什么要量化?
在深度神经网络模型应用中,量化是削减模型大小的一种常用方法。实际上就是把高位宽表示的权值和激活值用更低位宽来表示。为什么要削减模型,是因为硬件平台的自身性能不理想,如计算力低,内存、电量消耗等限制,导致模型推断速度慢、功耗高。 而定点运算指令比浮点运算指令在单位时间内能处理更多数据,同时,量化后的模型可以减少存储空间。当然,也可以将量化后的模型部署在高效的定制化计算平台上以达到更快的推断速度。
二、有哪些量化方法?怎样量化?
具体的量化方案有以下几种:
1.Uniform Affine Quantizer(均匀映射量化)
也叫非对称量化
下图是一个uint8非对称量化的映射过程:

首先,量化前要计算量化因子,包括步长和零点两个量化参数。量化因子就是用来保证浮点区间内的变量都能无一缺漏的映射到要量化bit数的取值区间内。其中,步长和零点的计算公式如下:

这里要重点说下零点z,也叫做偏移,为何这里需要零点?
实际上,浮点型的0会映射到零点,这个零点是一个整型数,用来确保0没有量化误差。具体就是,0有特殊意义,比如padding时,0值也是参与计算的,浮点型的0进行8bit量化后还是0就不对了,所以加上这个零点后,浮点型0就会被映射到0-255这个区间内的一个数,这样的量化就更精确。就相当于让映射后区间整体偏移,浮点最小值对应0。
计算完量化因子,再从浮点区间任取一值的量化过程:

即浮点值除以步长,就近取整,加上零点。再做clamp使量化的区间为(0,Nlevels-1),对于8bit量化,其中Nlevels就是2^8 =256。
注:对于单边分布,范围(Xmin,Xmax)需要进一步放宽去包含0点。例如,范围为(2.1, 3.5)的浮点型变量将会放宽为(0, 3.5),然后再量化。故,这种方式对于极端的单边分布会产生精度损失。
逆量化:

2.Uniform symmetric quantizer(对称量化)
对称量化是映射量化的简化版本。
下图是一个int8对称量化的映射过程:


首先,根据浮点区间的最大最小值计算量化因子(量化步长),然后在该范围内任选一个浮点型变量,利用给出的公式把它映射到8bit区间,即除以量化因子,就近取整,再根据有符号或无符号做一个clamp(截断),确定量化后的区间,当量化为8bit时,Nlevels就是2^8 =256,如果是4bit量化就是2 ^4=16。最后所有的浮点数都被映射在(-127,128)这个区间内,浮点数的最大最小值分别对应128、-127,将零点约束到0的位置。
文中提到:
若想更快的实现SIMD(SingleInstruction Multiple Data 单指令流多数据流),可以进一步约束权重的范围。这时,截断运算可以简化为:

对称量化的逆量化为:

更多对称量化内容查看这篇论文:Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
以上两个量化方案是比较常用的。
3.Stochastic quantizer(随机量化)
随机量化方法加了一个噪声:

期望情况下,随机量化方法通过对范围外的值进行饱和(既clamp),可以降低浮点型权重的通量。因此,这种方法比较适用于计算梯度。【这个量化不是很懂,后面再补充】
4. 在后向传播中的训练模拟量化建模
还是先放一张非对称量化的图以及模拟量化过程公式:


该模拟量化操作是在训练时就进行量化的(训练时量化后面会说),操作实际包括一个量化再紧跟一个逆量化。具体的,就是在前向传播的时候(forward)模拟了量化的这个过程,在forward时首先会把权值和激活值量化到8bit再反量化回有误差的32bit,整体训练还是浮点,反向传播(backward)的时候求得的梯度是模拟量化之后权值的梯度,用这个梯度去更新量化前的权值。
如上图,选择从左到右数第4个点进行量化,量化后的值为253,然后再进行反量化,就得到它正对着的第5个点,即误差点,实际上用的这个点做的前向推理的,用误差点求梯度去更新原始点,SimQuant就是量化+反量化。
所以对于SGD(随机梯度下降),更新方式如下:

由于模拟量化方程的导数几乎在各个位置均为0(我的理解就是连续的浮点数量化映射成了离散的点),故在反向传播求梯度时无法求得,所以需要在反向传播中构建一个近似量化。在实际工程中一种效果比较好的近似方法是将量化指定为下面公式的形式,这样可以方便定义导数。


上图是: 模拟量化器(顶部),显示量化输出值。 用于导数计算的近似(底部)。
而反向传播可以建模为“直通估计器”,即:

其中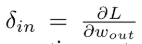
是关于模拟的量化输出的loss的反向传播误差。
具体内容查看这篇论文:Binaryconnect: Training deep neural
networks with binary weights during propagations
5.量化参数如何求得
量化参数可以利用一些标准来决定。前文中的量化参数是根据浮点值的最大最小计算出,这种计算量化因子实际是有问题的,这种属于不饱和的线性量化,会导致精度损失较大。于是就有了一种TensorRT的后量化算法,它通过最小化原始数据分布和量化后数据分布之间的KL散度来决定步长尺度。
具体的:
该算法对激活值进行饱和量化,即选择合适的阈值;对权值还是非饱和量化。
什么是饱和?非饱和?
看下面这张图:

首先左边的图,上面是未量化的浮点区间,下面是要映射的int8区间。可以看到负值取值更大一点,就假设取这个值作为阈值,而正数最大值这边可能只有负值这边大小的一半,所以这个点量化后可能只映射到0-127的一半处,假设是64,所以量化后64-127这个区间显然就被浪费了;再假如负数最大值处是一个噪声点,只占激活值的一小部分甚至一个,而正值这边的值占比大的话,那么量化之后这些有效值就会压缩到一个很小的区间,然后精度损失就会比较大。
而TensorRT的后量化算法是找到一个合适的阈值,如右图,把超出范围的噪声点的值都设为[T],然后量化之后,值会非常均匀的分布在(-127-127)这个区间。故左图代表非饱和,右图为饱和。
接下来用一段代码直观感受一下:
import numpy as np
def quant(x,s):
return[int(e) for e in np.clip(np.round(x*s),-128,127)]
arr=np.array([-0.75,-0.5,-0.1,0.1,0.2,0.5,1])
scale=127/np.max(np.abs(arr))
print("量化前:[%s]"%",".join([str(e) for e in arr]))
print("量化后:[%s]"%",".join([str(e) for e in quant(arr,scale)]))
人为给定一组数,假设是激活输出统计的值,按照量化的步骤,首先求得量化因子(根据区间最大值),可以看到该组数据的最大值是1,然后打印量化前后的值。
输出:

可以看到,量化前后一一对应的,这种量化精度几乎没有损失。
-------------------------------------------美丽分割线-----------------------------------------
然后这段代码,是把区间最大值换成了100,同样是用区间最大值来计算量化因子,打印量化前后的值。
arr=np.array([-0.75,-0.5,-0.1,0.1,0.2,0.5,100])
scale=127/np.max(np.abs(arr))
print("量化前:[%s]"%",".join([str(e) for e in arr]))
print("量化后:[%s]"%",".join([str(e) for e in quant(arr,scale)]))
输出:

而选取100作为量化因子的计算,可以很明显的看到,100的确映射到了127,但是整个量化后的区间都更偏向右,最左边的值的映射与-127相差很远,并且中间的值被压缩映射成了相同的0,因此这种选择精度损失非常大。
-------------------------------------------美丽分割线-----------------------------------------
最后一段代码是TensorRT算法思想,虽然数据里有一个超大值100的噪声点,但是不用它作为量化因子,而是选择一个较为合适的值如0.75,打印量化前后的值。
scale=127/0.75
print("量化前:[%s]"%",".join([str(e) for e in arr]))
print("量化后:[%s]"%",".join([str(e) for e in quant(arr,scale)]))
输出:

而基于TensorRT思想的结果,就更加合理,精度损失很小。
-------------------------------------------美丽分割线-----------------------------------------
在本文中,对于量化参数的计算采用一些更简单的方法。
权重:使用实际的最大和最小值来决定量化参数。
激活输出:使用跨批(batches)的最大和最小值的滑动平均值来决定量化参数。
先训练后量化的方法:可以通过仔细地选择量化参数来提高量化模型的精度。
6.量化的粒度
逐层量化:指定一个量化器(由尺度∆和零点z定义)对张量进行量化。如果想让精度进一步提升,可以采用对张量的每个卷积核都使用对应的量化器。
逐通道量化:对每个卷积核有不同的量化器。
对于激活输出我们不考虑逐通道量化,因为这会使卷积操作和矩阵乘操作中的内积计算变得复杂。“逐层量化”和“逐通道量化”都支持高效的点乘操作和卷积实现,因为这两种量化方式中量化参数在每个卷积核中都是固定的常量。
三、 量化推断:性能和准确性
这一部分介绍了工业部署中常用的两个模型量化方法,训练后量化和训练时量化
1.Post Training Quantization (训练后量化)
字面意思,整个模型(浮点型的)训练完成后再单独把权值和激活值拿出来量化。前面已经简单介绍了英伟达的TensorRT后量化算法,该文直接展示了在两个粒度(“逐层量化”、“逐通道量化”)不同量化方法(“对称量化”、“非对称量化”)分别对常用模型进行权重和激活量化的实验结果对比。
1.1只对权重量化
特点:如果只是想为了方便传输和存储而减小模型大小,而不考虑在预测时浮点型计算的性能开销的话,这个量化很有用。
1.2量化权重和激活输出
激活值不像权值那样有固定数量,所以这时就得需要标定数据了,即计算激活输出的动态范围,求得量化参数,然后再量化。一般使用100个小批量数据就足够估算出激活输出的动态范围了。
1.3实验
首先是各个网络量化前的模型参数大小以及在top-1分类精度值。

只对权值量化的结果:

可以看到,几乎对于所有模型来说逐通道量化方法可以提供很好的精度,且非对称逐通道的量化方案更接近浮点型精度。
量化权重和激活输出:
(激活输出是逐层量化的方式)

可以看到,当加上激活输出的逐层量化时,int8量化后的精度值更加接近浮点型精度值了。
下面用一个更直观的图来看下在Mobilenet-V1网络中几种量化方案的效果:

可以看到随着量化程度的增加以及图片大小的增大,精度是越来越高的,很明显逐层的激活量化和非对称逐通道的权重量化都与浮点精度很接近,而对权重的逐层量化即使增加量化程度增大图片尺寸任然表现不佳。因为这是因为bn操作在特征层的各个通道间的动态范围差异非常大,而逐通道量化可以通过通道粒度来避免这个问题,它可以逐通道地量化而不依赖与bn的缩放。但是,激活输出仍然需要采用逐层对称量化方式来量化。
下图是对各个网络8bit量化的柱状图:

从图中发现,好像只有Mobilenet系列对逐层量化不是很友好,其他有更多参数的网络结构(像Resnets 和 Inception-v3 )在对称/非对称的逐通道量化方案表现不错,即使是逐层量化精度损失也不大,即这些模型对量化的鲁棒性会更高。
总结:
1.激活输出做8bit量化后,精度几乎没有损失。由于以下原因,激活输出的动态范围一般很小:
(a) 无缩放的批归一化:它可以确保所有特征的激活输出服从均值为0,方差为1的分布。
(b) ReLU6: 它可以将所有的特征输出都固定到(0, 6)范围内,从而消除大动态范围的可能。
2. 几乎所有的量化精度损失都是源于权重量化而导致的。
2.Quantization Aware Training (训练时量化)
训练时量化方法相比于训练后量化,能够得到更高的精度,即使是逐层量化甚至是4bit 量化也能取得很高的精度。因此量化过程也会相对复杂一点。该文还简单介绍了利用Tensorflow的自动量化工具进行量化。
训练时量化对于权重和激活输出采用模拟量化操作来衡量量化效果。对于反向传播,使用前面说到的“直通估计器”去建模量化。其实,模拟量化那里已经比较清晰的描述了训练时量化的过程。再看下原文是怎么说的:
注意,在前向和反向传播计算中,我们使用的都是模拟量化的权重和激活输出。我们也保留浮点型权重,并且在梯度更新的过程中更新它们。这样可以确保使用较小的梯度更新逐步更新权重,而不会造成梯度满溢。更新的权重被量化,然后用于后续的前向和反向传播计算。
对比理解下就会更清晰了。
训练时量化方案可以利用Tensorflow的量化库,在训练和预测时在模型图中自动插入模拟量化操作来实现。
对于训练代码如下:
tf.contrib.quantize.create_training_graph(quant_delay=2000000)
- 1
调用训练重写,用假量化节点重写图,并折叠批处理规范进行训练。 可以微调现有的浮点模型,也可以从头开始训练。 quant_delay控制量化训练的开始。
对于测试代码:
tf.contrib.quantize.create_eval_graph()
- 1
调用eval重写,用假量化节点重写图,并为eval折叠批处理规范。
高层转换过程如图所示:

图中从左到右分别是训练后量化(只量化权重/量化权重和激活)和训练时量化。
在训练中,量化一个模型的步骤为:
1.条件允许的情况下,在保存好的浮点型模型的基础上精调,即在预训练好的模型基础上继续训练或者重新训练。
2.修改估计器,添加量化运算,即利用量化库中的tf.contrib.quantize Rewriter向模型中添加假的量化运算。
3.训练模型:这个过程结束后,我们就拥有了一个对于权重和激活输出都带有各自量化信息(尺度、零点)的保存好的模型。
4.转换模型:利用Tensorflow的在 tf.contrib.lite.toco 中定义的转换器(TOCO),将带有量化参数的模型被转化成一个flatbuffer文件,这个文件会将权重转换成int整型,同时包含了激活输出用于量化计算的信息。
5.执行模型: 转换后的带有整型权重的模型可以使用TFLite解释器执行,该解释器可以选择使用NN-API在自定义加速器中执行模型,也可以在CPU上运行模型。
一个简单的卷积层的转图例子:

该图为未量化的卷积操作。

这张图就是在卷积操作前对权值量化然后再计算,计算的结果即激活输出,接着对激活量化。
训练时量化有很多要注意的点,首先:
2.1量化的操作变换
下图为加法操作:

文中这里对图的介绍没有,于是恬着脸去问师兄,这个过程大致是这样的,可能我的理解会有偏差,最左边的图是未量化直接进行加的操作,右边的是分别对两个操作数量化然后相加,结果再进行量化。下面的图是,把两个已量化为8bit的操作数继续量化为32bit(重新调整定点值使乘加操作正确执行)进行相加,然后再将结果反量化回8bit,这样做的目的是提高精度,为什么在做加法运算时要量化成更低位宽,我认为应该是低位宽的乘加操作更快,所占内存更少,单位时间里能处理更多的数据(前文已提到)。
下图是连接操作:

同样的,连接操作,是把8bit量化为32bit再反量化为8bit(前面的加操作)进行两个操作数的连接,该操作不涉及复杂运算,所以不需要更低的位宽。
2.2Batch Normalization(批量归一化)
训练时量化有个特殊处理,就是对BN进行量化。它的量化可能会复杂一点,因为BN本身就较为难理解。
首先,BN简单来说就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。我们知道若想通过训练数据获得的模型能够在测试集上也表现良好,那么训练数据和测试数据应该是满足相同分布的(IID独立同分布假设)。
而对于深度学习这种包含很多隐层的网络结构,在训练过程中,各层参数老在变,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”。
于是就提出了BatchNorm的基本思想:让每个隐层节点的激活输入分布固定下来。即对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。总的来说,在工程实践中,对于加快模型收敛速度,它是一个非常好用的技术。(BN的介绍就到这,具体的可以参考这篇文章:
https://blog.csdn.net/laozaoxiaowanzi/article/details/107693176
现在回到BN量化,在训练和测试阶段BN的定义是不一样的。
训练:

测试:

其中 μ B 和 σ B分别为batch的均值和标准差。μ 和 σ 是整个训练集的均值和标准差,在训练阶段,这两个值可以通过batch的滑动平均方式计算得到。
对于预测,可以将bn按照以下公式所定义的那样折叠进权重中。因此,在预测时没有显式的bn操作。bn按如下方式拆分整合为权值和偏置:

其中γ和β是训练时习得的参数(具体看BN)。
下图是折叠BN量化推理的基线方法:

从图中可以看到,在训练阶段BN会使用批统计信息(既batch均值和方差),而在预测阶段使用的是整个训练集的均值和标准差。由于批统计量在每个batch批之间变化很大,这会在量化的权重中引入不希望的跳变,也会使量化模型的精度降低。一个简单的解决方法是,在训练时也使用整个训练集的均值和标准差,但是这样会使“!批!”归一化失去意义(既均值和标准差和批统计量完全没有了关系),并且会导致训练不稳定。图重构也是一种解决方法,它可以消除训练和预测时bn的差异,如下图所示:

- 首先量化之前要在完整训练集统计量上乘以一个带修正因子的权重。这会确保即使存在批统计量波动,量化权重也不会出现跳变。

2.在训练的初始阶段,不做权重的缩放(1步骤提到的),这样输出就是常规bn的输出。偏置bias同理。

3.在经过充分训练后,将批统计量(均值、标准差)替换为此时计算得到的训练集统计量(均值、标准差)。注意这时需要将训练集统计量(均值、标准差)冻结,从而避免训练不稳定。这相当于预测时使用的归一化参数,可以保证相对稳定的性能。

2.3实验
对于训练时量化还是做了和之前相同的实验,因为是在训练过程中量化,实验是从浮点型继续训练,且先将BN冻结,即不对BN做量化。文中采用随机梯度下降法训练,学习率1e-5。
首先还是看Mobilenet-v1训练时量化的结果:

同样,随着量化程度和图片尺寸的增加,精度越来越高,而且对于该网络结构来说,无论是非对称还是对称,甚至逐层量化精度损失都不是很多。
下图是对比了常用网络结构在训练后和训练时量化的结果:


结果非常明显了!逐层量化的精度和浮点型精度很接近。
2.4更低精度的网络(4bit)
在8bit精度上,训练后量化的精度和浮点型精度模型相差很小。为了能够更好地理解训练时量化所带来的好处,文中对权重和激活输出做了4bit量化的3个实验,结果如下:(注意,在这些实验中,激活输出仍采用8bit量化方式。)

实验1:在4bit精度上,逐通道量化明显要比逐层量化精度要高,甚至对于训练后量化也是如此。在8bit精度上,差距就没那么明显了,因为模型有足够的bit位容量,可以以高保真度去表征权重。(参见表5的第2、3列)
实验2:低的bit位宽情况下,在已有模型基础上继续训练会大幅提升模型精度。对于大多数网络来讲,采用4bit位宽精调得到的精度结果也只是比8bit量化的精度小5%以内(参见表的第4列)。

实验3:更低精度的激活输出量化:分别在精调(训练时)和不精调(训练后)的条件下,对所有层的激活输出采用4bit量化的精度进行了研究,这里激活输出采用逐层量化,而权重采用8bit逐通道量化。我们发现在这些实验中精调也会提升模型精度(第2列和第3列)。
由于激活量化而造成的损失比权重量化更严重(见表6)[这里我也不知道是怎么根据表中数据看出来的,我自己的理解是对比了第3、4列,第3列是8bit权重量化4bit激活量化,第4列是4bit权重量化8bit激活量化,本身4bit量化精度损失会比8bit的大,且权重量化带来的损失会更多一点,但是看表中数据低bit权值量化的精度反而比第3列高,所以这里激活量化造成了精度损失]。
注意权重和激活输出的量化粒度是不同的,所以对于量化影响来讲其实这不是一个公平的比较。所以我们只能猜测表6结果的原因是,量化激活输出会引入随机误差,因为不同图片之间的激活输出是有较大差异的,而权重量化是确定的,这就使网络能够更好地学习权重,从而补偿权重量化所带来的计算偏差。
四、Training best practices(训练效果最好的实践)
文中还做了一些不同配置的量化实验,得出一些结论。
1.他们做了随机量化和确定性量化(随机量化以外的方案),发现随机量化不会提升精度。随机量化方案会确定浮点型权重,这种浮点型权重在随机量化中提供鲁棒的性能,但这样会导致量化的权重在小批量之间波动变化。在预测时,量化值是确定的,却和训练时的不一致。正是因为这种不一致,会导致随机量化方案和确定量化方案相比表现不佳,而确定量化方案在训练过程中能够更好地补偿这种不一致。如图所示(训练时随机和确定量化对比):

可以看到,在训练次数不足250000步时,随机量化的精度低且不稳定,之后的精度虽然平稳但也不如确定量化高。
2.他们研究了从头开始训练一个量化模型所得到的模型精度和从浮点型checkpoint基础上训练得到的模型精度,发现后者会得到更好的精度。这也和一般的发现规律——最好先以尽可能多的自由度去训练一个模型,然后用这个模型作为引导老师去训练更小的模型——相一致。如图所示:

3.接着对量化bn的不同方法进行了的评测,结果显示带有修正的bn会产生最好的精度,即将bn与预测进行匹配会降低数据抖动,提高模型精度。他们展示了两个网络的结果。
在第一个实验中, 他们进行了各种量化方案的比较:利用Mobilenet-V1_1_224比较了原始实现的bn和采用纠正—冻结方式的bn,发现采用后者能得到更稳定、更高的精度(蓝色)。如图所示:

从图中可以看出,没有修正过得BN量化(绿色)数据抖动很明显,原因是 batch间的缩放变化。重新BN(红色),虽然提升了数据的抖动,但并没有消除。 使用移动平均统计对权重进行量化(橙色)可以减少抖动,但仍然不会消除。 200000步后冻结移动均值和方差更新(蓝色)允许量化权重以适应BN诱导的缩放, 并以最小的抖动提供最佳的精度。
在第二个实验中, 展示了BN校正—冻结对准确性的影响。他们利用Mobilenet-V2_1_224比较了原始实现的bn和采用纠正—冻结方式的bn,发现后者可以使精度进一步提升,如图中400000步后。

同样, 没有校正的量化显示很高的数据抖动(绿色); 用冷冻校正显示出良好的精度(蓝色红色); 移动平均线被冻结后,eval精度中的抖动显著下降(400000步后);红色曲线是在EMA权值经过充分的训练后的性能。
4.最后他们还比较了在训练中对权重进行平均和不进行平均这两种方案,得出的结论是:慎用指数滑动平均。在浮点型模型训练中,为了提高精度,通常会对权重进行滑动平均操作。由于在反向传播时使用的是量化后的权重和激活输出,浮点型权重可能会收敛于量化决策边界的位置上。即使是瞬时的和滑动平均的浮点型权重之间的微小差异,也会导致量化的权重产生非常明显的不同,影响性能,如上图中EMA(Exponential moving averaging)指数滑动平均对应曲线的精度下降(3500000步后,红色曲线下降)。
五、Model Architecture Recommendations (模型架构建议)
在这部分他们探讨了激活函数的选择,以及模型精度和模型宽度(模型尺寸)之间的取舍问题,并得出以下结论:
- 不要约束激活范围,即将ReLU6替换为ReLU(模型在训练中自己确定激活范围)会有微小的精度提升,如图所示:

该图表示Mobilenet-v1网络训练时用ReLU代替ReLU6进行浮点和量化的精确度的提高。
(其实这张图着实看不懂在对比个啥,我猜可能左边两列是Relu,右边两列是Relu6,但不知道为什么精度出现负值,精度负了也不奇怪,奇怪的是一正一负,往好心大佬指点。)
2.在前面的实验中可以得出,冗余度较高的模型更适合量化。他们对于像mobilenet这种更加精简的模型架构在精度和模型尺寸之间做了量化对比。首先,他们拿4bit权重逐通道量化模型 和 8bit不同深度乘子的量化模型(也就是8bit不同容量的量化模型),针对精度进行了比较,如图所示:

从图中可以发现,将权重进行4bit量化后的模型精度(横轴1对应的蓝色点,大概0.59)和 直接将模型容量缩减25%的模型精度(横轴0.75对应的红色点,和黄色重合了,大概0.61)相差无几,且都与float型精度接近。
六、Run-time measurements (运行时间测量)
这部分他们Google Pixel 2手机上利用单个大核,分别测量了浮点型模型和量化模型的运行时间,同时也在骁龙DSP上使用Android NN-API测量了运行时间,实验结果如下图所示:

在Google Pixel 2上(第2、3列),量化模型的预测速度比浮点型模型的预测速度快2到3倍;在骁龙DSP上(第2、4列),会快大概10倍。
七、Neural network accelerator recommendations (神经网络加速器建议)
为了让量化模型充分发挥其能力,他们提出了几个神经网络加速器增强的建议(直接用翻译的内容):
-
极致的运算符融合:在一次计算中,尽可能多地执行运算符,这样可以降低内存使用量、缩减运行时间以及减少耗电量。
-
压缩内存使用: 通过利用权重和激活输出的快速解压缩,我们可以优化内存带宽。实现这个操作的一个简单的方法就是去支持权重和激活输出的低精度存储。
-
低精度计算: 通过支持一系列精度的计算,可以进一步加速。我们的建议是支持4bit、8bit和16bit权重和激活输出。4bit和8bit精度对于分类任务来讲足够了,回归任务需要更高精度的支持,比如超分辨率和高动态范围图像处理。
-
位宽逐层选择:我们期望网络的许多层可以在更低位宽精度下处理。这样做可以进一步减少模型尺寸和运行时间。
-
逐通道量化:支持逐通道量化对于以下几点的实现是至关重要的:
(a) 为了使模型在硬件上更容易部署,不需要特定硬件的精调
(b) 更低精度计算
八、结论
- 如果选择训练后量化策略,请使用权重的对称逐通道量化作为开始。如果精度有下降的话,可以考虑精调(在浮点型checkpoint基础上继续训练)。
- 训练时量化可以进一步减小和浮点型模型的精度差距,采用8bit量化时可以将精度差距缩减到5%以内,甚至当4bit量化所有层时也是如此。
- 在CPU上,8bit量化预测可以提速2到3倍。在特定的专门为低精度向量计算优化过的处理器上,例如支持HVX的骁龙DSP,和浮点型模型预测速度相比可以提速近10倍。
- 我们利用均匀量化可以在精度不变的情况下将模型尺寸缩小4倍。更高的压缩可以通过非均匀量化技术实现,比如K-means。
- 在模型尺寸和压缩比之间存在比较清晰的折中关系。容量越大的模型对量化误差的容忍度越高。
- 对于某一个模型结构,我们可以在特征数量和量化之间进行折中,要是用更多的特征数量就可以相应更低位宽的卷积核。
- 在训练中不约束激活函数的输出范围,然后直接对输出进行量化,这样会得到更高的精度。从我们的实验结果看出,对于激活输出最好使用ReLU,而不建议ReLu6
参考:
https://blog.csdn.net/wc996789331/article/details/90601123
https://www.bilibili.com/video/BV1cZ4y1u7T5/
模型量化的目的
本文的模型量化是优化深度学习模型推理过程的内存容量和内存带宽问题的概念,通过将模型参数的浮点数类型转换称整型存储的一种模型压缩技术。以可以接受的精度损失换取更少的存储开销和带宽需求,更快的计算速度,更低的能耗与占用面积。
比如int8量化,就是让原来32bit存储的数字映射到8bit存储。int8范围是[-128,127], uint8范围是[0,255]。
模型量化优点:
- 减小模型尺寸,如8位整型量化可减少75%的模型大小
- 减少存储空间,在边缘侧存储空间不足时更具有意义
- 易于在线升级,模型更小意味着更加容易传输
- 减少内存耗用,更小的模型大小意味着不需要更多的内存
- 加快推理速度,访问一次32位浮点型可以访问四次int8整型,整型运算比浮点型运算更快
- 减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗
- 支持微处理器,有些微处理器属于8位的,低功耗运行浮点运算速度慢,需要进行8bit量化
模型量化缺点:
- 模型量化增加了操作复杂度,在量化时需要做一些特殊的处理,否则精度损失更严重
- 模型量化会损失一定的精度,虽然在微调后可以减少精度损失,但推理精度确实下降
量化数据映射的实现

比如进行int8的量化,数据范围是[-128,127],最大值最小值分别是Xmax, Xmin,X_q表示量化后的数据,X_f表示浮点数据。
X_q=X_f/scale +zero
scale=(Xmax-Xmin)/(127-(-128))=(Xmax-Xmin)/255
zero=0-round(Xmin/scale)或者zero=255-round(Xmax/scale)
量化方式分为对称量化和非对称量化,其中上面是非对称量化的方式,如果是对称量化,则是将原浮点数的范围由[Xmin, Xmax]扩充为[-Xmax, Xmax],这里假定 |Xmax|>|Xmin|。然后按照上面公式转换量化值。对称量化对于正负数不均匀分布的情况不够友好,比如如果浮点数全部是正数,量化后的数据范围是[128,255], [0,127]的范围就浪费了,减弱了int8数据的表示范围。
对称量化的图示

非对称量化的图示















 906
906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









