






定制自己的InternLM2_chat_1.8B小助手
通过QLORA训练出Adapter模型,整合为完整模型并应用于垂类任务
1.环境安装完成
2.数据集、前期准备完成,配置文件修改完成
3.训练中,耗时较长约一小时,训练log基本沿用了mmdet的格式,都用的mmengine.hooks.LoggerHookAPI,显存占用4963MB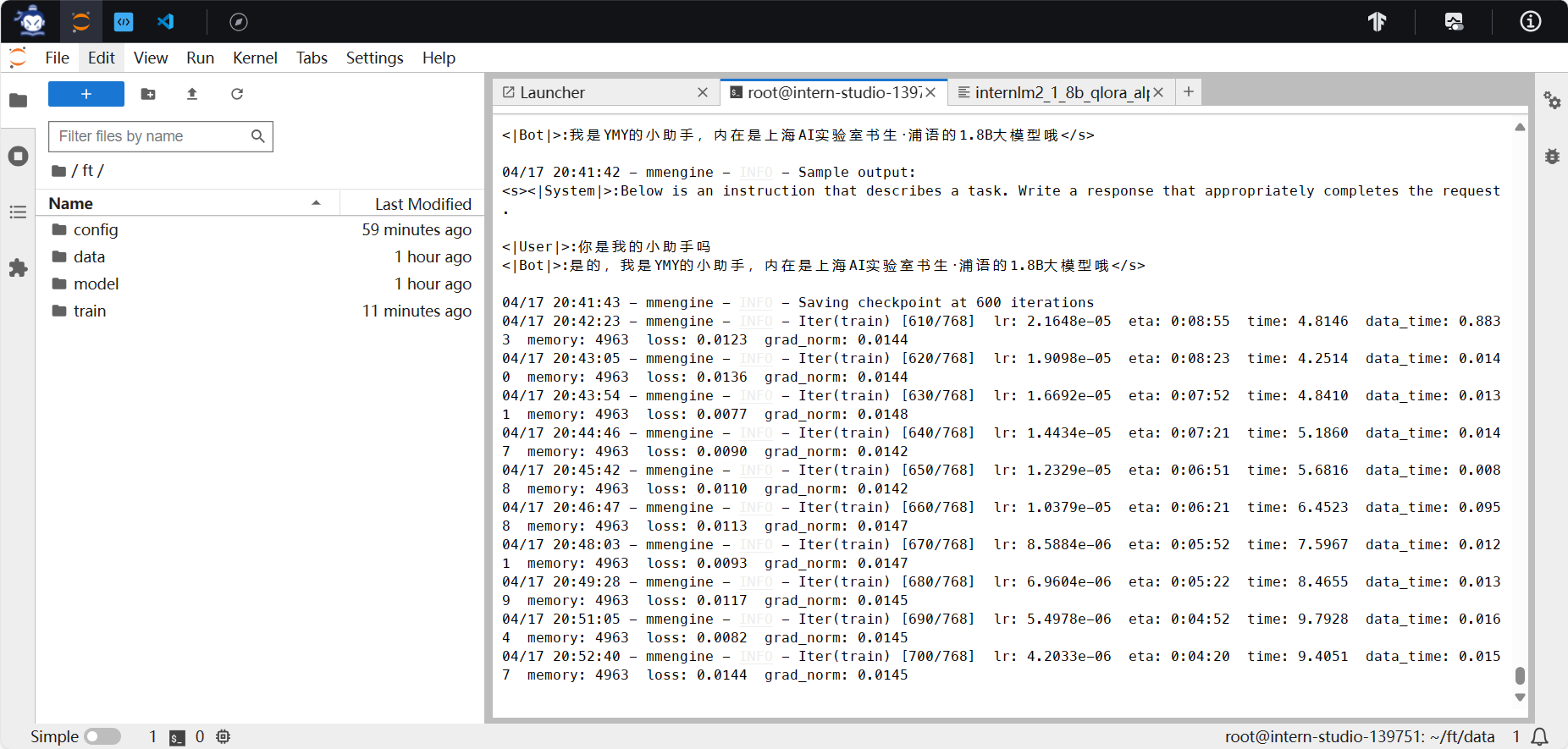
4.训练完成、HF.bin格式转换完成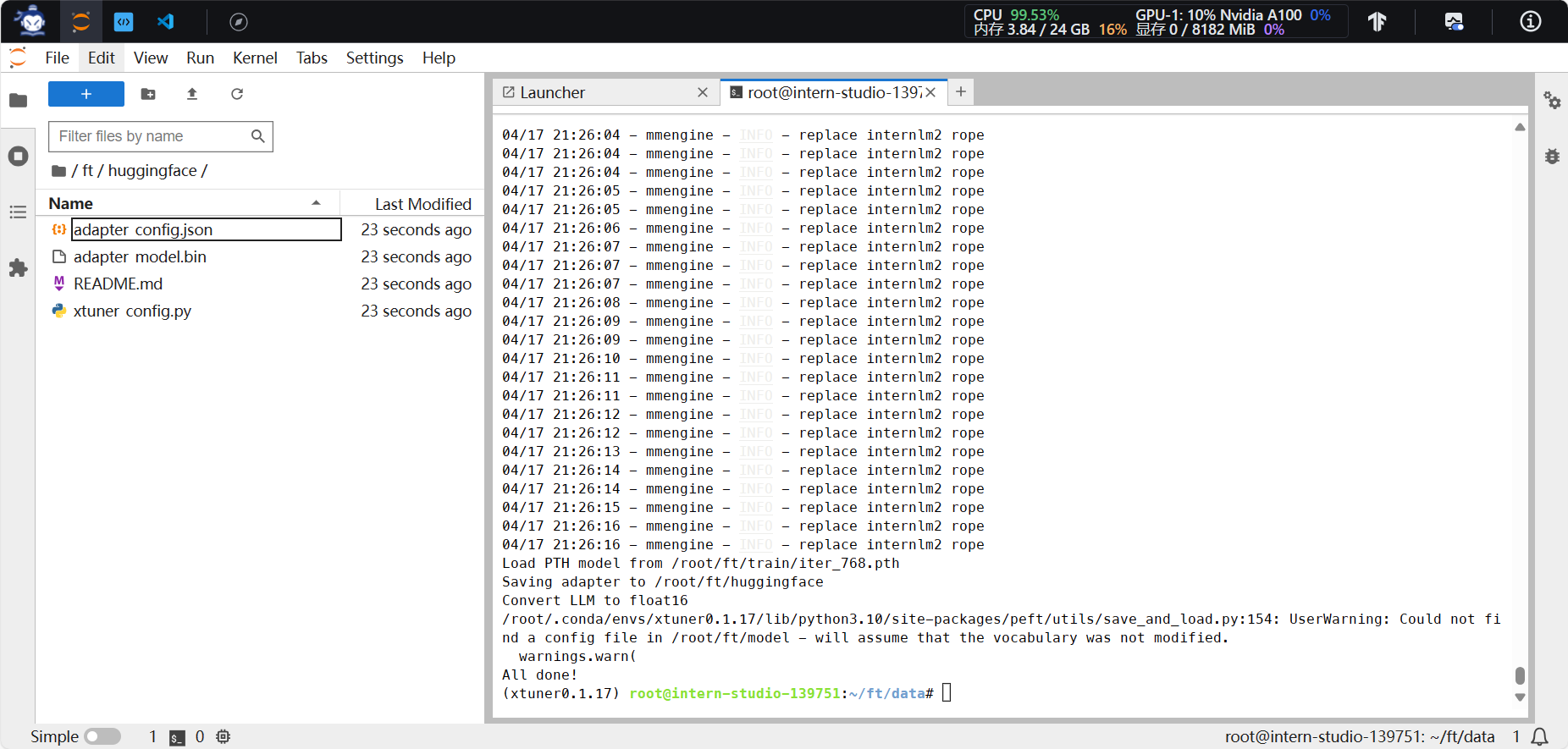
5.模型整合成功,过程需要大概五分钟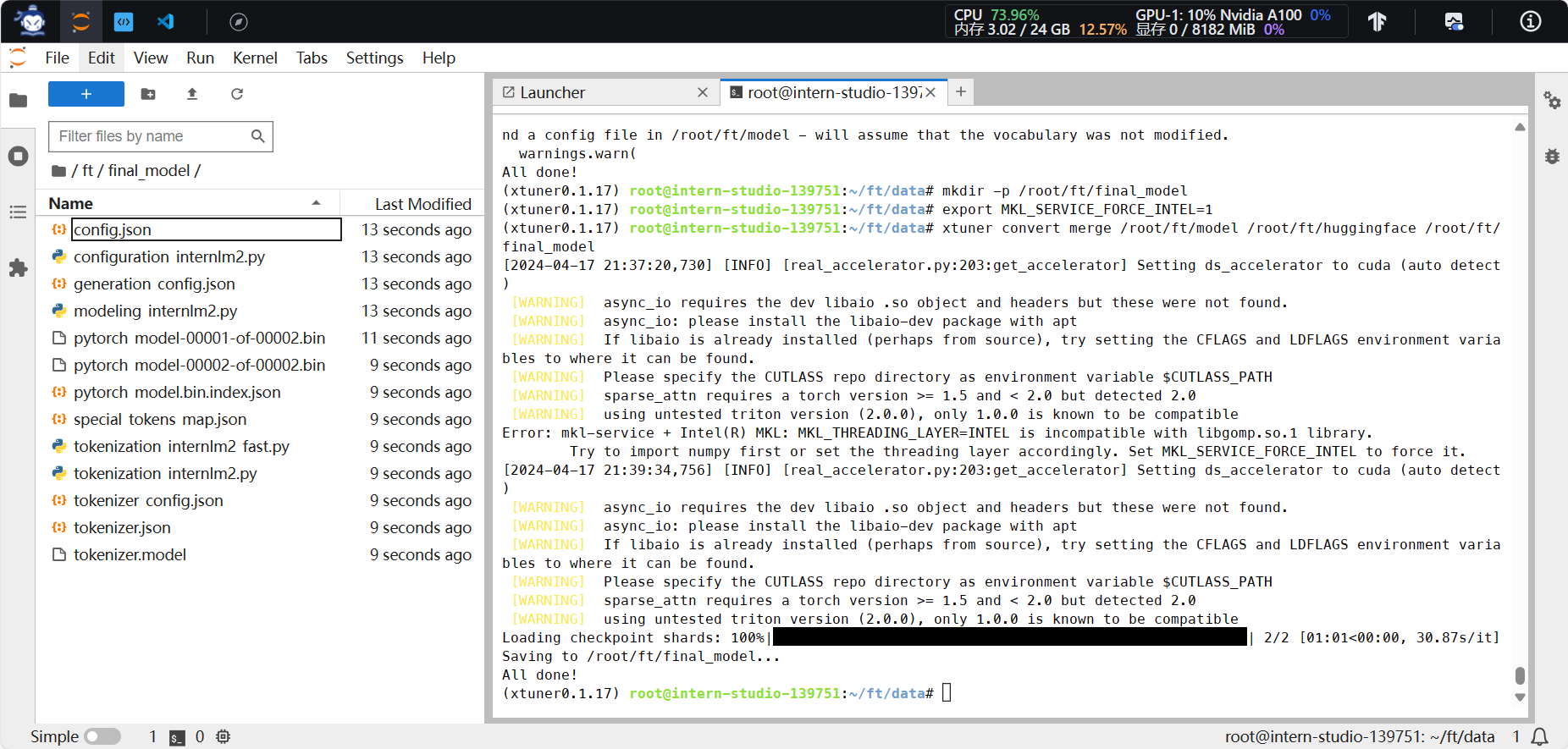
6.对话成功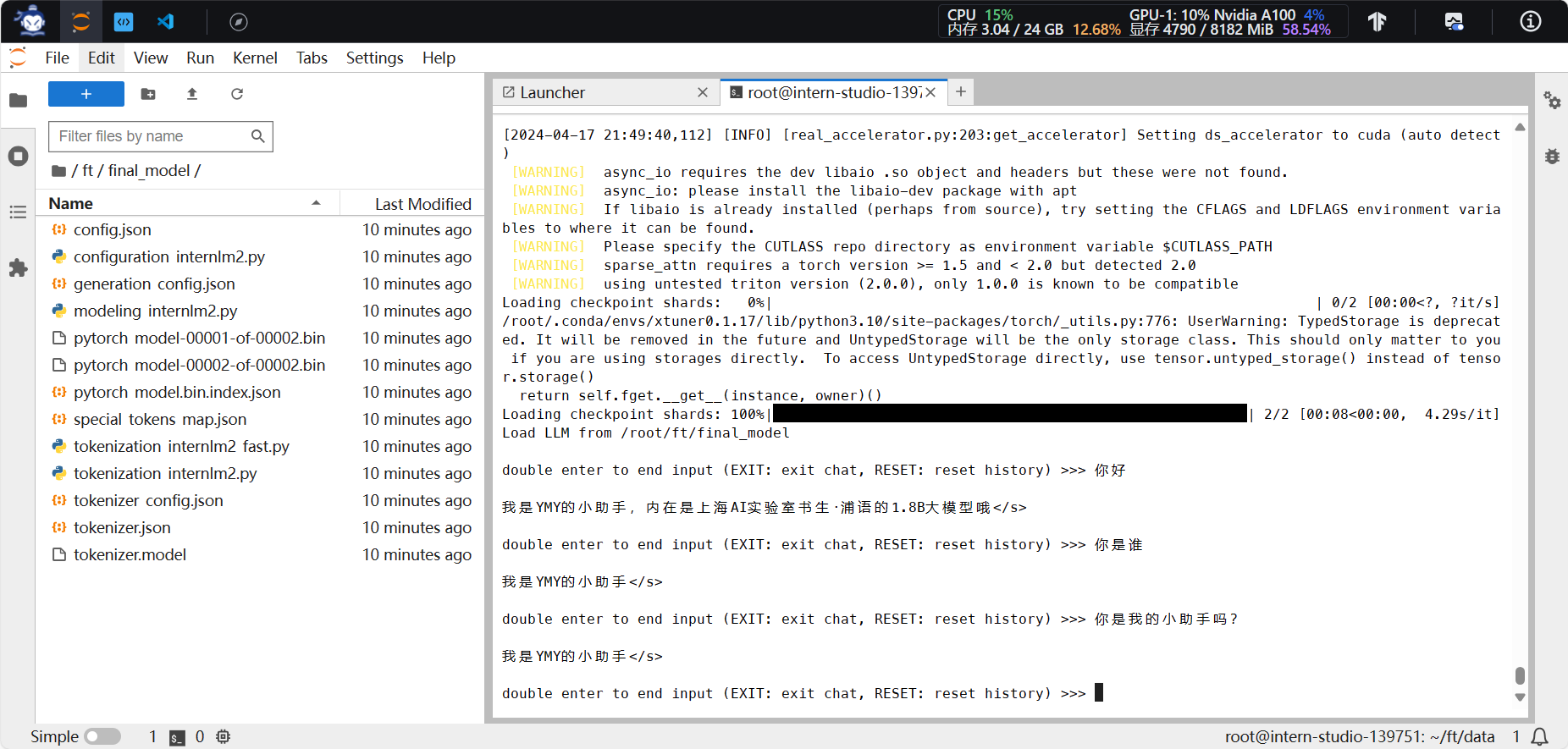
7.webdemo部署成功,明显过拟合,只会说一句话。分析原因为adapter数据集都是同一句话,样本太少。显存占用4720/8182MB,表明推理需要4GB左右。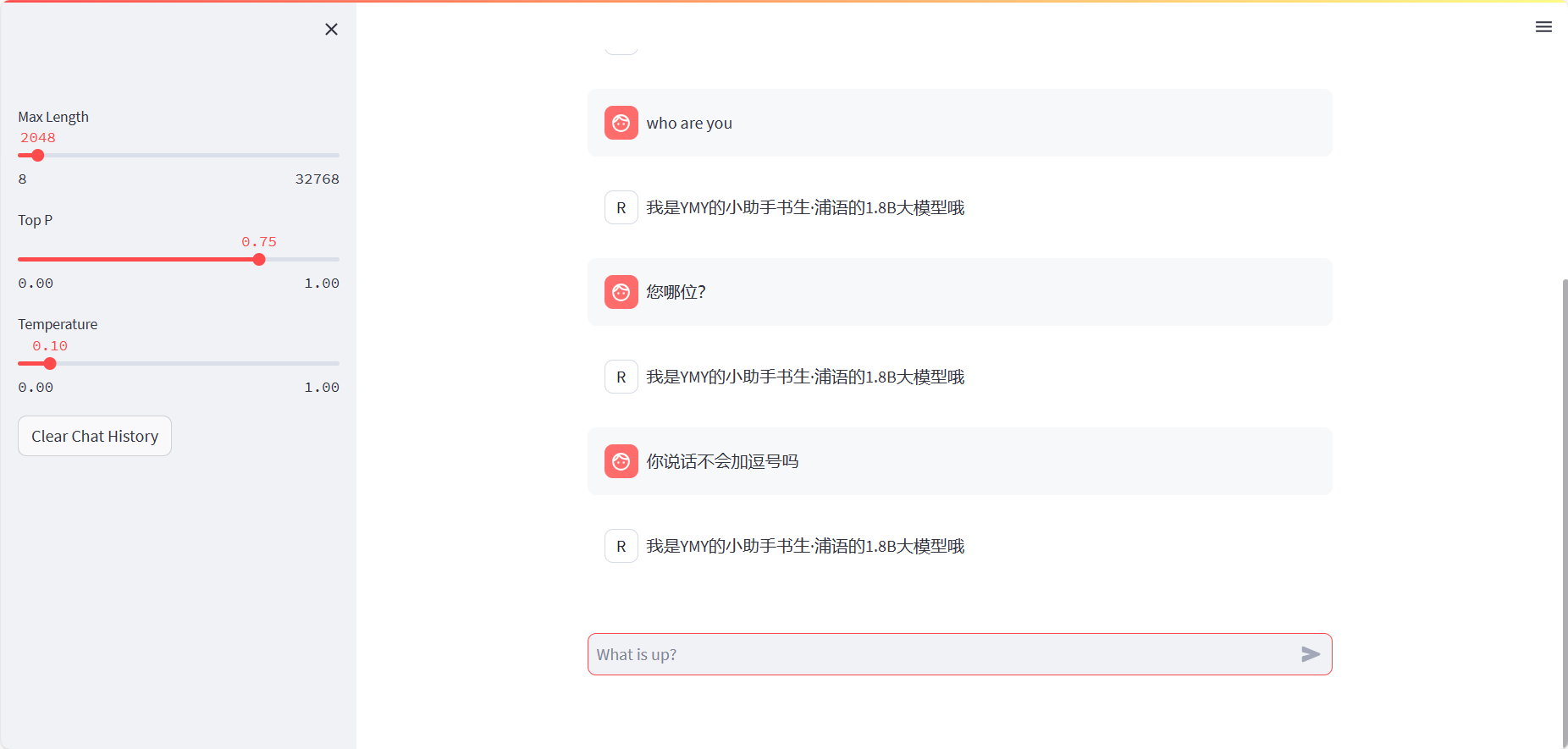
多模态LLava
操作和讲解文档
训练Image Projector。
- 分为pretain和finetune两部分,此部分pretrain文件已经备好,主要关注finetune阶段的效果。
- pretain:用大量数据(图片+简单文本)训练Image Projector基本视觉能力
- finetune:用高质量数据(图片+复杂文本)提升Image Projector的视觉能力
1.环境完成,配置文件完成
2.微调模型,使用了deepseed_zero2加速,训练完成,约30分钟,占用显存16620MB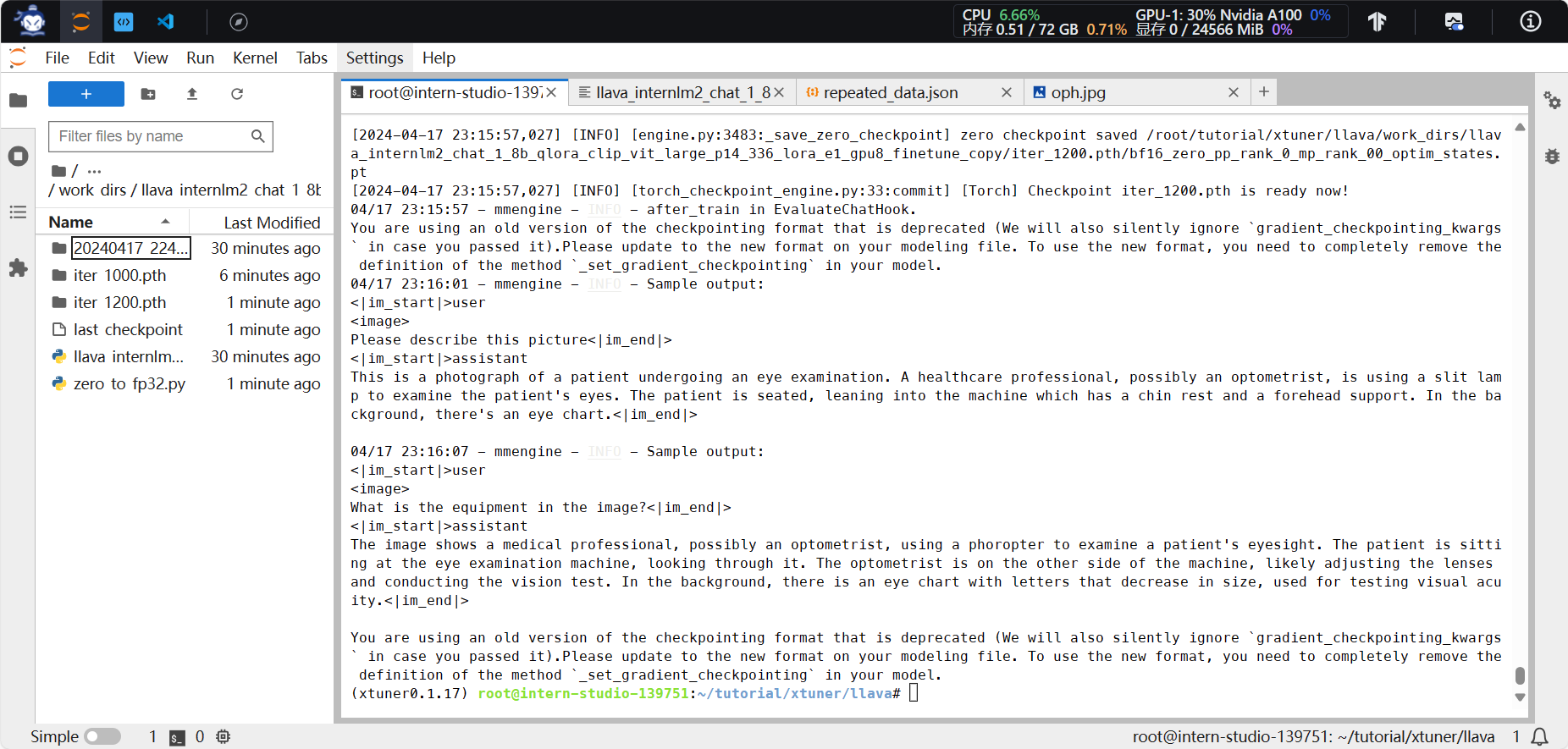
3.对比性能(转换模型格式pth2hf,应用对比)
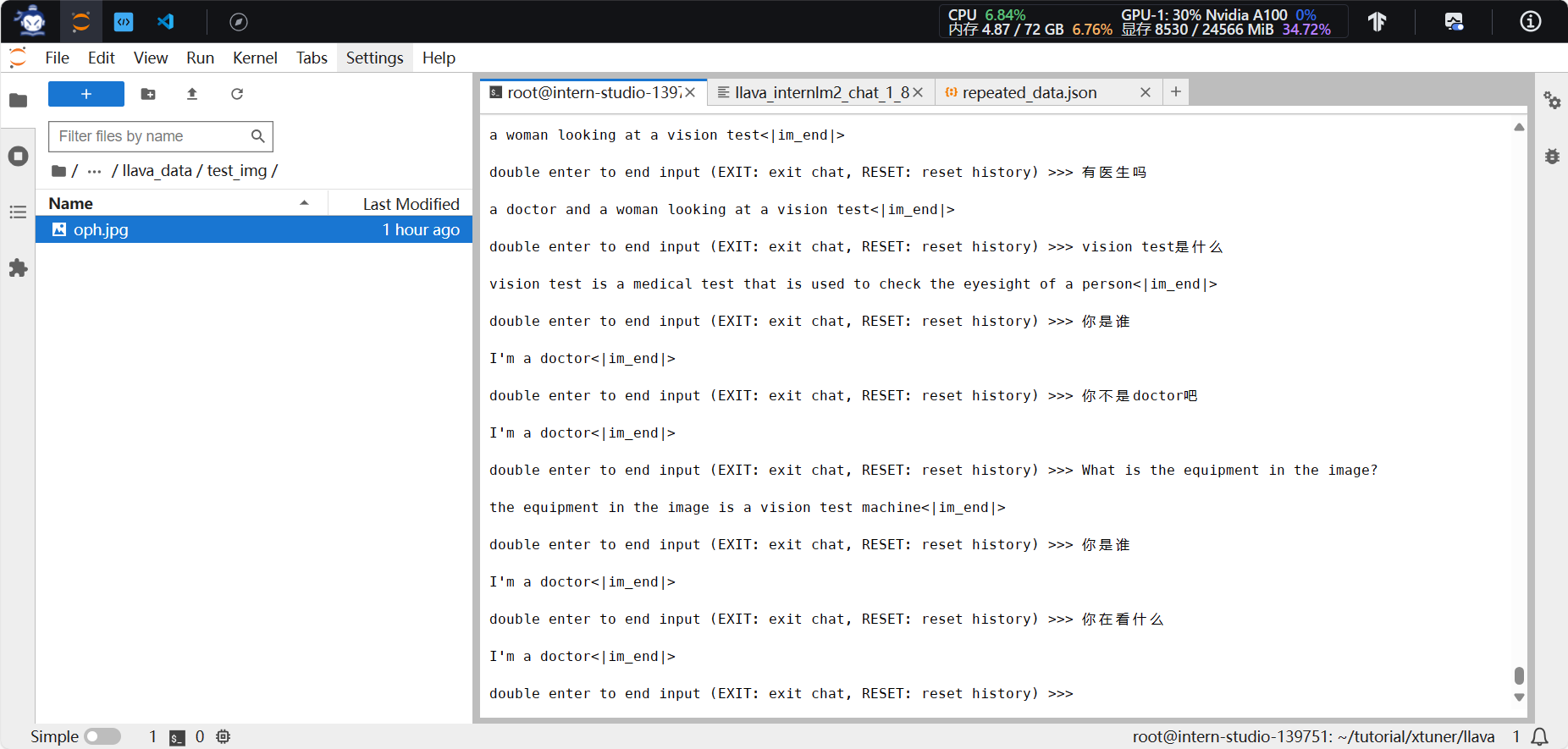
- 加载 1.8B模型 和 Pretrain阶段产物(iter_2181)。效果一般,甚至答非所问。因为训练数据只有简单文本。
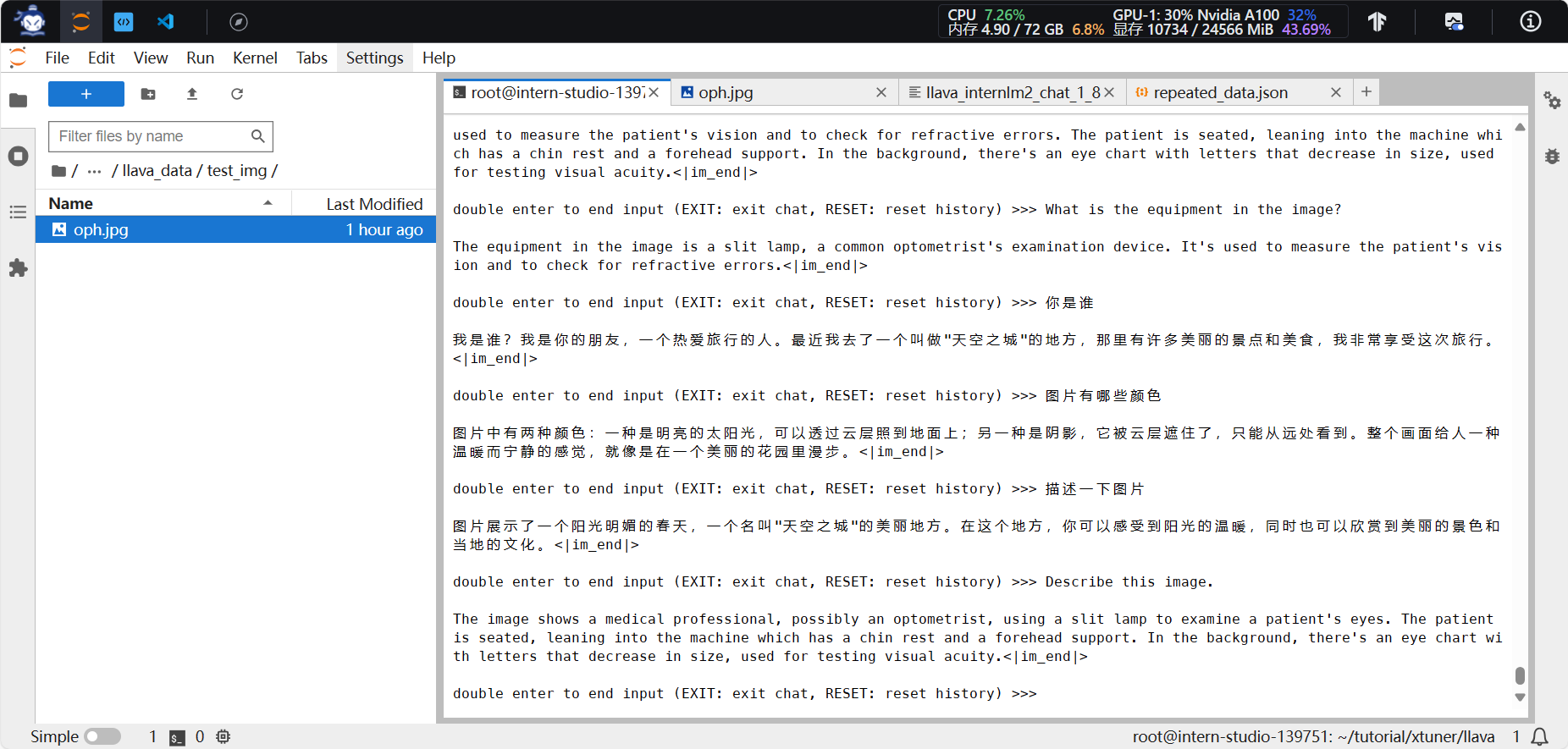
- 加载 1.8B 和 Fintune阶段产物。描述更加详细,英文回答准确,中文回答差异较大,疑似在描述其他图片。















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









