







背景知识简介
在计算机视觉中,有一块领域叫做相机标定,这篇博客主要描述的是相机标定中,通过对应的3d点坐标(世界坐标系,World Frame)和2d点坐标(图像坐标系,Image Frame)透射投影。
什么是透射投影
我们需要把3d点
(
x
W
,
y
W
,
z
W
,
1
)
(x_W,y_W,z_W,1)
(xW,yW,zW,1)的坐标从世界坐标系(World Frame)转化到图像坐标系(Image Frame)
(
x
I
,
y
I
,
w
I
)
(x_I,y_I,w_I)
(xI,yI,wI)。这里使用的都是齐次坐标(Homogeneous Coordinates),主要的目的就是可以把旋转和位移放到同一个矩阵中,想要进一步了解的同学可以自行百度。
[
x
I
y
I
w
I
]
=
[
R
3
×
3
∣
t
3
×
1
]
[
x
w
y
w
z
w
1
]
=
P
[
x
w
y
w
z
w
1
]
\left[\begin{matrix} x_I\\ y_I\\ w_I\\ \end{matrix}\right]=\left[\begin{matrix} R^{3\times3}&|&t^{3\times1} \end{matrix}\right]\left[\begin{matrix} x_w\\ y_w\\ z_w\\ 1 \end{matrix}\right]=P\left[\begin{matrix} x_w\\ y_w\\ z_w\\ 1 \end{matrix}\right]
⎣⎡xIyIwI⎦⎤=[R3×3∣t3×1]⎣⎢⎢⎡xwywzw1⎦⎥⎥⎤=P⎣⎢⎢⎡xwywzw1⎦⎥⎥⎤
这里的
P
3
×
4
P^{3\times4}
P3×4就是我们需要的透射投影矩阵(Projection Matrix)。其中
R
3
×
3
R^{3\times3}
R3×3是一个旋转矩阵,我们可以理解为它表示了一个3d点绕着x,y,z轴分别旋转了
α
,
θ
,
γ
\alpha,\theta,\gamma
α,θ,γ度,所以虽然它包含了9个元素(
3
×
3
=
9
3\times3=9
3×3=9),但是它只有3个自由度(3 DoFs,Degree of Freedom)。然后
t
t
t可以视为一个位移,它包含3个元素且自由度为3(3 DoFs)。所以整个透射投影矩阵(Projection Matrix)
P
P
P虽然包含12(
3
×
4
=
12
3\times4=12
3×4=12)个未知元素,但是它的的自由度为6,也就是说,最少我们需要6组对应的3d点和2d点才能对它进行估计(可以简单理解为至少需要6个方程才能解6个未知数)。
p.s. 这里我们不进一步讨论矫正矩阵(Calibration Matrix)、正准矩阵(Canonical Matrix)等概念。
线性估计(Direct Linear Transformation (DLT) Algorithm)
理论推导分析
我们现在有的数据集为n组对应点,
{
(
x
i
,
X
i
)
for
i
=
0
,
1
,
2
,
.
.
.
,
n
}
\{(x_i,X_i) \text{ for } i = 0,1,2, ... ,n \}
{(xi,Xi) for i=0,1,2,...,n} 其中
x
=
(
x
I
/
w
I
,
y
I
/
w
I
,
1
)
x = (x_I/w_I,y_I/w_I,1)
x=(xI/wI,yI/wI,1)
X
=
(
x
W
,
y
W
,
z
W
,
1
)
X = (x_W,y_W,z_W,1)
X=(xW,yW,zW,1)
x
=
P
X
x = PX
x=PX
很容易,我们会联想到使用线性代数的知识
x
×
x
=
x
×
(
P
X
)
=
0
x\times x =x\times (PX)=0
x×x=x×(PX)=0(这里的乘号代表叉乘)。但是这并不是实际过程中工程师将会用的方法,具体为什么我不太记得了,希望知道的朋友可以在博客下面回复补充。现实中,工程师将使用如下等式
[
x
]
⊥
x
=
[
x
]
⊥
P
X
=
[
l
1
T
l
2
T
]
P
X
=
0
[x]^\perp x = [x]^\perp PX = \left[\begin{matrix} l_1^T\\ l_2^T \end{matrix}\right] PX= 0
[x]⊥x=[x]⊥PX=[l1Tl2T]PX=0
[
x
]
⊥
[x]^\perp
[x]⊥ 代表了相交与于
x
x
x点两条直线
l
1
3
×
1
l_1^{3\times1}
l13×1和
l
2
3
×
1
l_2^{3\times1}
l23×1 (使用了引理:若
x
x
x为直线
l
l
l上一点,那么
x
T
l
=
l
T
x
=
0
x^Tl=l^Tx=0
xTl=lTx=0)
下面我们会进行一系列推到,将 [ x ] ⊥ P X = 0 [x]^\perp PX=0 [x]⊥PX=0转化为一个更加方便计算估计 P P P的表达式。
假设
P
=
[
p
11
p
12
p
13
p
14
p
21
p
22
p
23
p
24
p
31
p
32
p
33
p
34
]
=
[
p
1
T
p
2
T
p
3
T
]
P = \left[\begin{matrix} p_{11}&p_{12}&p_{13}&p_{14}\\ p_{21}&p_{22}&p_{23}&p_{24}\\ p_{31}&p_{32}&p_{33}&p_{34} \end{matrix}\right] = \left[\begin{matrix} p^{1T}\\ p^{2T}\\ p^{3T} \end{matrix}\right]
P=⎣⎡p11p21p31p12p22p32p13p23p33p14p24p34⎦⎤=⎣⎡p1Tp2Tp3T⎦⎤
p
=
vec
(
P
T
)
=
[
p
11
p
12
p
13
⋮
p
34
]
p = \text{vec}(P^T) = \left[\begin{matrix} p_{11}\\ p_{12}\\ p_{13}\\ \vdots\\ p_{34} \end{matrix}\right]
p=vec(PT)=⎣⎢⎢⎢⎢⎢⎡p11p12p13⋮p34⎦⎥⎥⎥⎥⎥⎤
l
=
[
a
b
c
]
l=\left[\begin{matrix} a\\ b\\ c \end{matrix}\right]
l=⎣⎡abc⎦⎤
那么
[
x
]
⊥
P
X
=
[
l
1
T
l
2
T
]
P
X
=
[
a
1
b
1
c
1
a
2
b
2
c
2
]
[
p
1
T
X
p
2
T
X
p
3
T
X
]
=
[
a
1
X
T
b
1
X
T
c
1
X
T
a
2
X
T
b
2
X
T
c
2
X
T
]
[
p
11
p
12
p
13
⋮
p
34
]
[x]^\perp PX=\left[\begin{matrix} l_1^T\\ l_2^T \end{matrix}\right] PX= \left[\begin{matrix} a_1&b_1&c_1\\ a_2&b_2&c_2 \end{matrix}\right] \left[\begin{matrix} p^{1T}X\\ p^{2T}X\\ p^{3T}X \end{matrix}\right]=\left[\begin{matrix} a_1X^T&b_1X^T&c_1X^T\\ a_2X^T&b_2X^T&c_2X^T \end{matrix}\right] \left[\begin{matrix} p_{11}\\ p_{12}\\ p_{13}\\ \vdots\\ p_{34} \end{matrix}\right]
[x]⊥PX=[l1Tl2T]PX=[a1a2b1b2c1c2]⎣⎡p1TXp2TXp3TX⎦⎤=[a1XTa2XTb1XTb2XTc1XTc2XT]⎣⎢⎢⎢⎢⎢⎡p11p12p13⋮p34⎦⎥⎥⎥⎥⎥⎤
因此
[
x
]
⊥
P
X
=
[
l
1
T
⊗
X
T
l
2
T
⊗
X
T
]
p
=
(
[
x
]
⊥
⊗
X
T
)
p
=
0
[x]^\perp PX = \left[\begin{matrix} l_1^T \otimes X^T\\ l_2^T \otimes X^T\\ \end{matrix}\right] p =([x]^\perp \otimes X^T)p=0
[x]⊥PX=[l1T⊗XTl2T⊗XT]p=([x]⊥⊗XT)p=0
我们可以把n组数据写成一个大型的矩阵方程
[
[
x
1
]
⊥
⊗
X
1
T
[
x
2
]
⊥
⊗
X
2
T
⋮
[
x
n
]
⊥
⊗
X
n
T
]
p
=
A
p
=
0
where
n
≥
6
\left[\begin{matrix} [x_1]^\perp \otimes X_1^T\\ [x_2]^\perp \otimes X_2^T\\ \vdots\\ [x_n]^\perp \otimes X_n^T \end{matrix}\right] p = Ap=0 \text{ where $n\geq6$ }
⎣⎢⎢⎢⎡[x1]⊥⊗X1T[x2]⊥⊗X2T⋮[xn]⊥⊗XnT⎦⎥⎥⎥⎤p=Ap=0 where n≥6
至于解这个
A
p
=
0
Ap=0
Ap=0的方程,最直接、有效的方法就是对矩阵
A
A
A使用非满秩(当
n
>
6
n>6
n>6)的SVD分解
A
=
U
Σ
V
T
=
U
2
n
×
2
n
Σ
2
n
×
12
[
v
1
T
v
2
T
⋮
v
n
T
]
A = U\Sigma V^T = U^{2n\times2n}\Sigma^{2n\times12}\left[\begin{matrix} v^{1T}\\ v^{2T}\\ \vdots\\ v^{nT} \end{matrix}\right]
A=UΣVT=U2n×2nΣ2n×12⎣⎢⎢⎢⎡v1Tv2T⋮vnT⎦⎥⎥⎥⎤
p
12
×
1
=
v
n
p^{12\times1} = v^{n}
p12×1=vn
p
p
p的线性估计结果为矩阵
V
V
V的最后一列或
V
T
V^T
VT的最后一行(不同的python扩展包中SVD分解的结果中可能是
V
V
V也可能是
V
T
V^T
VT,请仔细看函数介绍)。
python代码实现
数据可以点击这里下载
import numpy as np
import time
def Homogenize(x):
# converts points from inhomogeneous to homogeneous coordinates
return np.vstack((x,np.ones((1,x.shape[1]))))
def Dehomogenize(x):
# converts points from homogeneous to inhomogeneous coordinates
return x[:-1]/x[-1]
def Normalize(pts):
# data normalization of n dimensional pts
#
# Input:
# pts - is in inhomogeneous coordinates
# Outputs:
# pts - data normalized points
# T - corresponding transformation matrix
"""your code here"""
pts_mean = pts.sum(1)/pts.shape[1] ## mean of pts
pts_var = np.var(pts, axis=1).sum() ## var = x_var + y_var (+ z_var)
s = (pts.shape[0]/pts_var)**0.5
T = np.eye(pts.shape[0]+1)
for i in range(pts.shape[0]):
T[i,i] = s
T[:,-1] = Homogenize((-pts_mean * s).reshape(-1,1)).flatten()
pts = np.dot(T,Homogenize(pts))
return pts, T
def ComputeCost(P, x, X):
# Inputs:
# x - 2D inhomogeneous image points
# X - 3D inhomogeneous scene points
#
# Output:
# cost - Total reprojection error
n = x.shape[1]
covarx = np.eye(2*n)
"""your code here"""
X = Homogenize(X)
x_project = np.dot(P,X)
x_proj = Dehomogenize(x_project)
cost = ((x-x_proj)**2).sum()
return cost
def GetPeprp(x):
# Inputs:
# x - 2D homogeneous image points, 3*n
# Output:
# x_perp - perpendicular complement of x, 2n*3
n = x.shape[1]
x_perp = np.zeros((2*n,3))
for i in range(2*n):
if i%2 == 0:
x_perp[i,0] = 1
else:
x_perp[i,1] = 1
x_inhomo = Dehomogenize(x)
x_perp[:,-1] = -x_inhomo.T.flatten()
return x_perp
def DLT(x, X, normalize=True):
# Inputs:
# x - 2D inhomogeneous image points
# X - 3D inhomogeneous scene points
# normalize - if True, apply data normalization to x and X
#
# Output:
# P - the (3x4) DLT estimate of the camera projection matrix
P = np.eye(3,4)+np.random.randn(3,4)/10
# data normalization
if normalize:
x, T = Normalize(x)
X, U = Normalize(X)
else:
x = Homogenize(x)
X = Homogenize(X)
"""your code here"""
x_perp = GetPeprp(x)
n = x.shape[1]
A = np.zeros((2*n, 12)) ## (2n,12)
for i in range(n):
for j in range(3):
A[2*i,4*j:4*j+4] = x_perp[2*i,j]*X[:,i]
A[2*i+1,4*j:4*j+4] = x_perp[2*i+1,j]*X[:,i]
_, _ , Vh = np.linalg.svd(A)
P = Vh[-1].reshape(3,4)
# data denormalize
if normalize:
P = np.linalg.inv(T) @ P @ U
P = P/np.linalg.norm(P)
return P
# load the data
x=np.loadtxt('points2D.txt').T
X=np.loadtxt('points3D.txt').T
# compute the linear estimate without data normalization
print ('Running DLT without data normalization')
time_start=time.time()
P_DLT = DLT(x, X, normalize=False)
cost = ComputeCost(P_DLT, x, X)
time_total=time.time()-time_start
# display the results
print('took %f secs'%time_total)
print('Cost=%.9f'%cost)
# compute the linear estimate with data normalization
print ('Running DLT with data normalization')
time_start=time.time()
P_DLT = DLT(x, X, normalize=True)
cost = ComputeCost(P_DLT, x, X)
time_total=time.time()-time_start
# display the results
print('took %f secs'%time_total)
print('Cost=%.9f'%cost)
大家可以自行写一下plot结果的部分,差不多会是这样,黑色的是真实2d点,红色的是根据线性估计计算出的
P
P
P计算出的投影点。
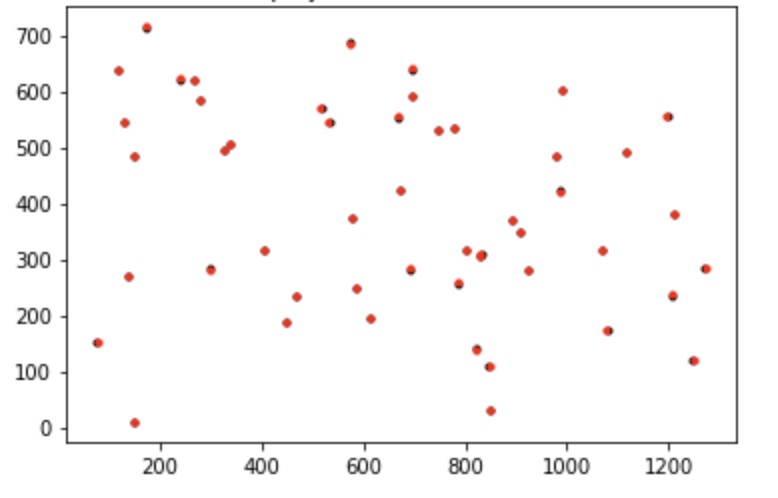
代码中引入了归一化(Normalization)的概念,可以有效地降低参数估计中的误差。具体的公式可以从代码中推出,这里就不一一展开了。
非线性估计
Levenberg Marquardt 算法介绍
给定条件:
- 度量矢量 (Measurement Vector) x x x和它的协方差 Σ x \Sigma_x Σx
- 参数矢量 (Parameter Vector) P ^ \hat{P} P^(始化估计)
目标:
- 寻找到 P ^ \hat{P} P^最小化 ϵ T Σ x − 1 ϵ \epsilon^T\Sigma_x^{-1}\epsilon ϵTΣx−1ϵ,其中 ϵ = x − x ^ \epsilon = x-\hat{x} ϵ=x−x^, x ^ \hat{x} x^为使用估计的参数获得的度量。
具体算法:
- λ = 0.001 , ϵ = x − x ^ \lambda = 0.001,\epsilon = x-\hat{x} λ=0.001,ϵ=x−x^
- 计算Jacobian矩阵 J = ∂ x ^ ∂ P J = \frac{\partial \hat{x}}{\partial P} J=∂P∂x^
- 加权最小二乘法方程: ( J T Σ x − 1 J ) δ = J T Σ x − 1 ϵ (J^T\Sigma_x^{-1}J)\delta = J^T\Sigma_x^{-1}\epsilon (JTΣx−1J)δ=JTΣx−1ϵ,这条方程从 J δ = ϵ J\delta=\epsilon Jδ=ϵ中获得。
- 增广方程: ( J T Σ x − 1 J + λ I ) δ = J T Σ x − 1 ϵ (J^T\Sigma_x^{-1}J+\lambda I)\delta = J^T\Sigma_x^{-1}\epsilon (JTΣx−1J+λI)δ=JTΣx−1ϵ,求解 δ \delta δ。值得注意的是,这里的 ( J T Σ x − 1 J + λ I ) (J^T\Sigma_x^{-1}J+\lambda I) (JTΣx−1J+λI)是一个对称矩阵。
- 获得候选参数矢量: P ^ 0 = P ^ + δ \hat{P}_0 = \hat{P}+\delta P^0=P^+δ
- P ^ 0 → x ^ 0 , ϵ 0 = x − x ^ 0 \hat{P}_0 \rightarrow \hat{x}_0 ,\epsilon_0=x-\hat{x}_0 P^0→x^0,ϵ0=x−x^0
- 判定:如果 ϵ 0 Σ x − 1 ϵ 0 \epsilon_0\Sigma_x^{-1}\epsilon_0 ϵ0Σx−1ϵ0小于 ϵ Σ x − 1 ϵ \epsilon\Sigma_x^{-1}\epsilon ϵΣx−1ϵ,则 P ^ = P ^ 0 , ϵ = ϵ 0 , λ = 0.1 λ \hat{P} = \hat{P}_0,\epsilon=\epsilon_0,\lambda=0.1\lambda P^=P^0,ϵ=ϵ0,λ=0.1λ,回到步骤2,并记一次迭代;反之, λ = 10 λ \lambda = 10\lambda λ=10λ,回到步骤4,不计入迭代次数。
(未完待续…)















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









