







什么是剔除错误匹配?
在我之前的一篇文章中使用了很简陋的一对一特征点匹配算法。获得了如下的结果:
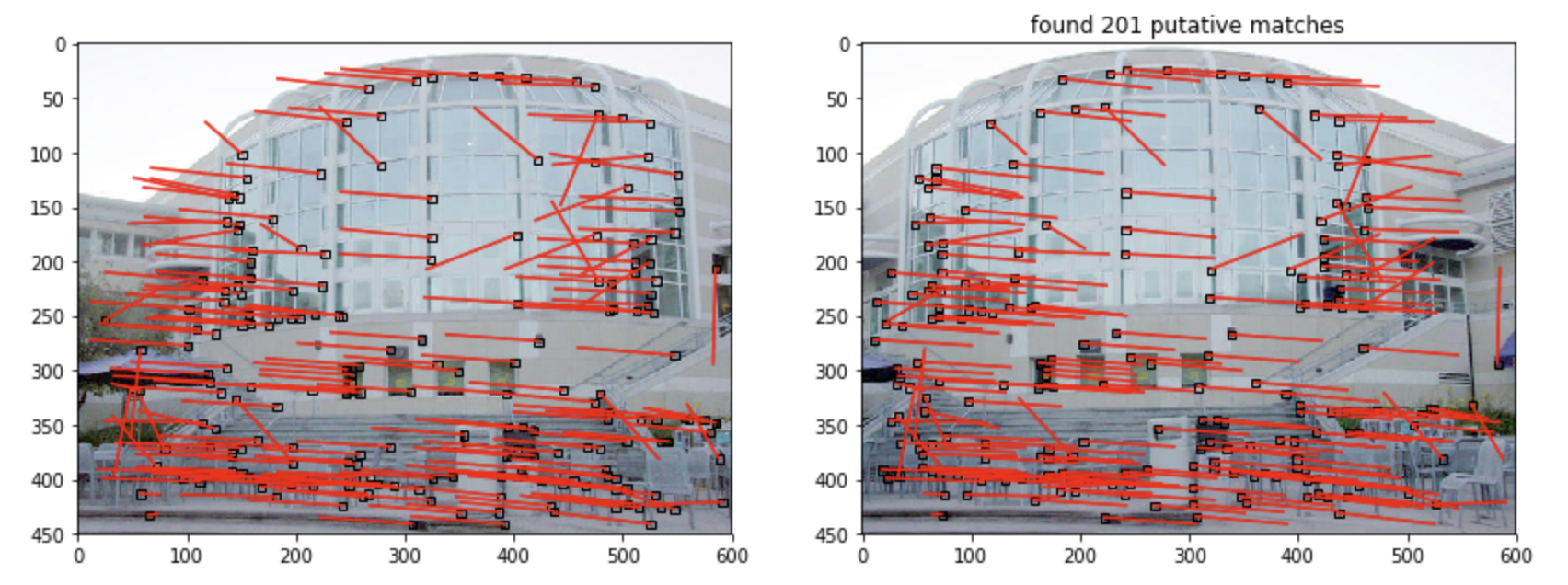
这个结果是粗糙且不令人满意的,我们接下来要介绍两种算法来剔除上述结果中的错误匹配对。
RANSAC 与 MASC 思想概述
RANSAC全称Random Sample Consensus(随机抽样一致算法),MSAC全称M-Estimate Sample Consensus。这两种算法基本思路一致,都是随机选取一部分粗糙结果中的匹配对,再利用其他的算法(如本项目是估计2维透射投影矩阵,即匹配对中的两个点之间的关系为 x 3 × 1 = H 3 × 3 x ′ 3 × 1 x^{3\times1} = H^{3\times3}x'^{3\times1} x3×1=H3×3x′3×1,那么我们就需要使用四点法来计算 H 3 × 3 H^{3\times3} H3×3)反推模型并计算该模型对于所有粗糙匹配对的cost,反复迭代,最终找到一个优化的模型,剔除所有不符合该模型的匹配对。
RANSAC与MSAC唯一的区别在于cost的计算方式。下面是算法主体的伪代码和两种不同cost计算方式的c++伪代码(在很多情况下伪代码比文字叙述更容易理解一些):
ConsensusMinCost = +inf
For (Trails=0;Trails<maxTrails&&ConsensusMinCost>Threshold; ++Trails){
Select a Random Sample;
Calculate Model;
Calculate Error;
Calculate ConsensusCost; //具体Cost算法将在下面给出
If (ConsensusCost<consensusMinCost){
consensusMinCost = consensusCost;
consensusMinCostModel = Model;
}
}
Calculate the Error for consensusMinCostModel;// 对每一组匹配对
Calculate set of Inliers ;// Error<=Tolerence, Inliers就是经过筛选后的精确匹配对
其中Tolerance是一个超参,表示Error值比这个参数的匹配对将被保留。
RANSAC的cost算法伪代码:
count = number of Data Points //粗糙匹配对的组数
cost = 0
For (n=0; n<count; n++){
cost += Error[n] <= Tolerance?0:1;
}
MSAC的cost算法伪代码:
count = number of Data Points //粗糙匹配对的组数
cost = 0
For (n=0; n<count; n++){
cost += Error[n] <= Tolerance?Error[n]:Tolerance;
}
哪种算法更好呢???
理论上来说MSAC是更优的解法。维基百科的解释为
RANSAC can be sensitive to the choice of the correct noise threshold that defines which data points fit a model instantiated with a certain set of parameters. If such threshold is too large, then all the hypotheses tend to be ranked equally (good). On the other hand, when the noise threshold is too small, the estimated parameters tend to be unstable ( i.e. by simply adding or removing a datum to the set of inliers, the estimate of the parameters may fluctuate). To partially compensate for this undesirable effect, Torr et al.
大体意思是RANSAC对于threshold的值(上述代码中的Tolerance)选取过于敏感,这个值过大了算法就无效了,过小的话算法会变得很不稳定。而MSAC可以做到部分补偿这些负面影响。
最后经过MSAC筛选后的匹配对结果如下图:
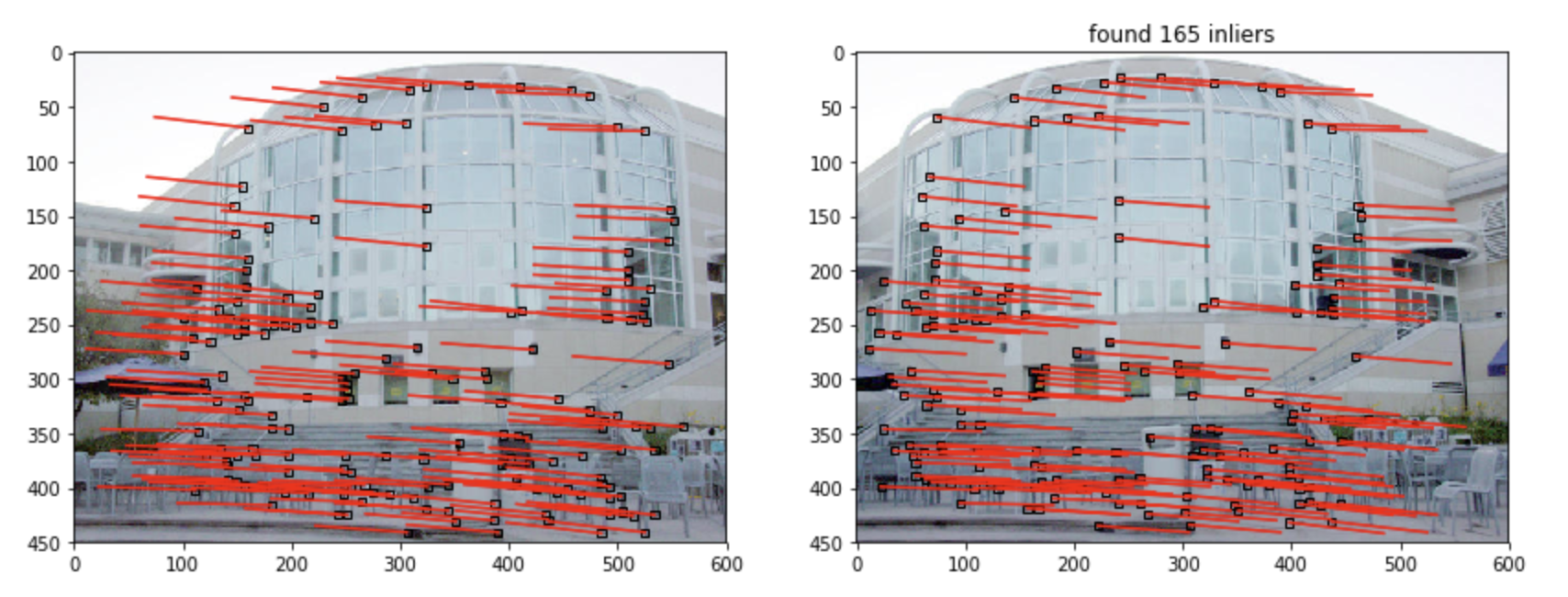
很舒服。
想了想,我把MSAC的python代码贴出来吧还是(不包括上面提到的四点法),大家可以参考:
def MSAC(pts1, pts2, thresh, tol, p):
# Inputs:
# pts1 - matched feature correspondences in image 1
# pts2 - matched feature correspondences in image 2
# thresh - cost threshold
# tol - reprojection error tolerance
# p - probability that as least one of the random samples does not contain any outliers
#
# Output:
# consensus_min_cost - final cost from MSAC
# consensus_min_cost_model - planar projective transformation matrix H
# inliers - list of indices of the inliers corresponding to input data
# trials - number of attempts taken to find consensus set
trials = 0
trials_max = np.inf
consensus_min_cost = thresh
pts1_homo=Homogenize(pts1)
pts2_homo=Homogenize(pts2)
while trials < trials_max:
random_4pts_idx = random.sample(range(60),4)
x1_4pts = pts1_homo[:,random_4pts_idx]
x2_4pts = pts2_homo[:,random_4pts_idx]
try:
H = FourPointsAlgorithm(x1_4pts,x2_4pts)
except:
continue
error,delta = SampsonError(H,pts1_homo,pts2_homo)
cost,num_inlier,temp_inliers = ComputeCost(H, pts1_homo, pts2_homo, tol)
if cost<consensus_min_cost:
consensus_min_cost = cost
consensus_min_cost_model = H
inliers = temp_inliers
s = 4 #sample size
w = num_inlier/pts1.shape[1]
if w>0:
trials_max = np.log(1-p)/np.log(1-w**s)
print('trials_max: ',trials_max,'\t trials: ',trials,'\t num_inlier: ',num_inlier)
trials = trials+1
print("Number of attempts: ", trials)
return consensus_min_cost, consensus_min_cost_model, inliers, trials















 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









