







目录
摘要
主要介绍linux系统的一些机制,为后面linux系统c应用开发以及python应用开发做铺垫
一、linux系统调用文件操作
1.1 系统调用基本概念
系统调用(system call)其实是 Linux 内核提供给应用层的应用编程接口(API),是 Linux 应用层进入内核的入口。不止 Linux 系统,所有的操作系统都会向应用层提供系统调用,应用程序通过系统调用来使用操作系统提供的各种服务。
通过系统调用,Linux 应用程序可以请求内核以自己的名义执行某些事情,譬如打开磁盘中的文件、读写文件、关闭文件以及控制其它硬件外设。通过系统调用 API,应用层可以实现与内核的交互,其关系可通过下图简单描述:

1.2 文件I/O基础
1.2.1 文件描述符
调用 open 函数会有一个返回值,这是一个 int 类型的数据,在 open函数执行成功的情况下,会返回一个非负整数,该返回值就是一个文件描述符(file descriptor),这说明文件描述符是一个非负整数;对于 Linux 内核而言,所有打开的文件都会通过文件描述符进行索引。
当调用 open 函数打开一个现有文件或创建一个新文件时,内核会向进程返回一个文件描述符,用于指代被打开的文件,所有执行 IO 操作的系统调用都是通过文件描述符来索引到对应的文件,当调用 read/write 函数进行文件读写时,会将文件描述符传送给 read/write 函数
在 Linux 系统下,可以通过 man 命令(也叫 man 手册)来查看某一个 Linux 系统调用的帮助信息,man 命令后面跟着两个参数,数字 2 表示系统调用,man 命令除了可以查看系统调用的帮助信息外,还可以查看 Linux 命令(对应数字 1)以及标准 C 库函数(对应数字 3)所对应的帮助信息;最后一个参数 open 表示需要查看的系统调用函数名。
man 2 open #查看 open 函数的帮助信息
1.2.2 open打开文件
在 Linux 系统中要操作一个文件,需要先打开该文件,得到文件描述符,然后再对文件进行相应的读写操作(或其他操作),最后在关闭该文件;
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
·pathname:要打开或创建的文件名;
·flag:指定文件的打开方式,具体有以下参数,见下表flag 参数值:
| flag | 含义 |
|---|---|
| O_RDONLY | 以只读的方式打开文件,该参数与O_WRONLY和O_RDWR只能三选一 |
| O_WRONLY | 以只写的方式打开文件 |
| O_RDWR | 以读写的方式打开文件 |
| O_CREAT | 创建一个新文件 |
| O_APPEND | 将数据写入到当前文件的结尾处 |
| O_TRUNC | 如果pathname文件存在,则清除文件内容 |
·mode:当open 函数的flag 值设置为O_CREAT 时,必须使用mode 参数来设置文件与用户相关的权限:
| 参数 | 含义 |
|---|---|
| 当前用户 | |
| S_IRUSR | 用户拥有读权限 |
| S_IWUSR | 用户拥有写权限 |
| S_IXUSR | 用户拥有执行权限 |
| S_IRWXU | 用户拥有读、写、执行权限 |
| 当前用户组 | |
| S_IRGRP | 当前用户组的其他用户拥有读权限 |
| S_IWGRP | 当前用户组的其他用户拥有写权限 |
| S_IXGRP | 当前用户组的其他用户拥有执行权限 |
| S_IRWXG | 当前用户组的其他用户拥有读、写、执行权限 |
| 其他用户 | |
| S_IROTH | 其他用户拥有读权限 |
| S_IWOTH | 其他用户拥有写权限 |
| S_IXOTH | 其他用户拥有执行权限 |
| S_IROTH | 其他用户拥有读、写、执行权限 |
1.2.3 read 函数
用于从文件中读取若干个字节的数据,保存到数据缓冲区buf 中,并返回实际读取的字节数
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
·fd:文件对应的文件描述符,可以通过fopen 函数获得。另外,当一个程序运行时,Linux默认有0、1、2 这三个已经打开的文件描述符,分别对应了标准输入、标准输出、标准错误输出,即可以直接访问这三种文件描述符;
·buf:指向数据缓冲区的指针;
·count:读取多少个字节的数据。
1.2.4 write 函数
用于往文件写入内容,并返回实际写入的字节长度
ssize_t write(int fd, const void *buf, size_t count);
·fd:文件对应的文件描述符,可以通过fopen 函数获得。
·buf:指向数据缓冲区的指针;
·count:往文件中写入多少个字节。
1.2.5 close函数
可调用 close 函数关闭一个已经打开的文件
#include <unistd.h>
int close(int fd);
fd:文件描述符,需要关闭的文件所对应的文件描述符。
返回值:如果成功返回 0,如果失败则返回-1。
除了使用 close 函数显式关闭文件之外,在 Linux 系统中,当一个进程终止时,内核会自动关闭它打开的所有文件,也就是说在我们的程序中打开了文件,如果程序终止退出时没有关闭打开的文件,那么内核会自动将程序中打开的文件关闭。很多程序都利用了这一功能而不显式地用 close 关闭打开的文件。
显式关闭不再需要的文件描述符往往是良好的编程习惯,会使代码在后续修改时更具有可读性,也更可靠,进而言之,文件描述符是有限资源,当不再需要时必须将其释放、归还于系统。
1.2.6 lseek 函数
可以用与设置文件指针的位置,并返回文件指针相对于文件头的位置
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
·fd:文件描述符。
·offset:偏移量,以字节为单位。
·whence:用于定义参数 offset 偏移量对应的参考值,该参数为下列其中一种(宏定义):
| 参数 | 偏移量 |
|---|---|
| SEEK_SET | offset是一个绝对位置 |
| SEEK_END | offset是以文件尾为参考点的相对位置 |
| SEEK_CUR | offset是以当前位置为参考点的相对位置 |
1.2.7 示例代码
保留
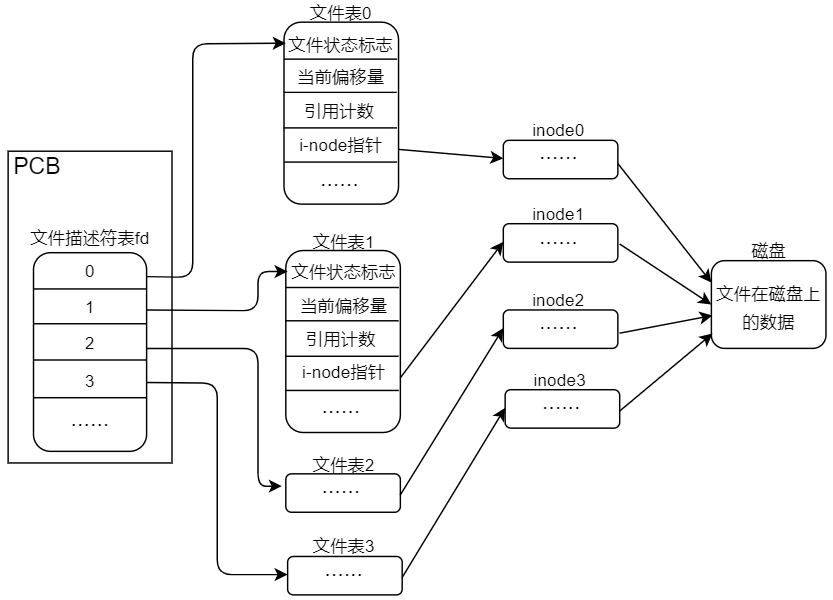
1.3 静态文件与 inode
打开一个文件,系统内部会将这个过程分为三步:
①系统找到这个文件名所对应的 inode 编号;
②通过inode编号从 inode table 中找到对应的 inode 结构体;
③根据inode结构体中记录的信息,确定文件数据所在的 block,并读出数据。
1.4 终止运行
本小节就给大家介绍了 3 中终止进程的方法:
- main 函数中运行 return;
- 调用 Linux 系统调用_exit()或_Exit();
- 调用 C 标准库函数 exit()。
1.4.1 _exit()和_Exit()函数
main 函数中使用 return 后返回,return 执行后把控制权交给调用函数,结束该进程。调用_exit()函数会清除其使用的内存空间,并销毁其在内核中的各种数据结构,关闭进程的所有文件描述符,并结束进程、将控制权交给操作系统。
调用函数需要传入 status 状态标志,0 表示正常结束、若为其它值则表示程序执行过程中检测到有错误发生
#include <unistd.h>
void _exit(int status);
#include <stdlib.h>
void _Exit(int status);
1.4.2 exit()函数
exit()函数_exit()函数都是用来终止进程的,exit()是一个标准 C 库函数,而_exit()和_Exit()是系统调用。执行 exit()会执行一些清理工作,最后调用_exit()函数。
#include <stdlib.h>
void exit(int status);
二、C标准库文件操作
2.1 标准 I/O 库简介
库函数也就是 C 语言库函数,C 语言库是应用层使用的一套函数库,在 Linux 下,通常以动态(.so)库文件的形式提供,存放在根文件系统/lib 目录下,C 语言库函数构建于系统调用之上,也就是说库函数其实是由系统调用封装而来的,当然也不能完全这么说,原因在于有些库函数并不调用任何系统调用,譬如一些字符串处理函数 strlen()、strcat()、memcpy()、memset()、strchr()等等;而有些库函数则会使用系统调用来帮它完成实际的操作,譬如库函数 fopen 内部调用了系统调用 open()来帮它打开文件、库函数 fread()就利用了系统调用 read()来完成读文件操作、fwrite()就利用了系统调用 write()来完成写文件操作。
Linux 系统内核提供了一系列的系统调用供应用层使用,我们直接使用系统调用就可以了呀,那为何还要设计出库函数呢?事实上,有些系统调用使用起来并不是很方便,于是就出现了 C 语言库,这些 C 语言库函数的设计是为了提供比底层系统调用更为方便、更为好用、且更具有可移植性的调用接口。
来看一看它们之间的区别:
(1) 库函数是属于应用层,而系统调用是内核提供给应用层的编程接口,属于系统内核的一部分;
(2) 库函数运行在用户空间,调用系统调用会由用户空间(用户态)陷入到内核空间(内核态);
(3) 库函数通常是有缓存的,而系统调用是无缓存的,所以在性能、效率上,库函数通常要优于系统调用;
(4) 可移植性:库函数相比于系统调用具有更好的可移植性,通常对于不同的操作系统,其内核向应用层提供的系统调用往往都是不同;而对于 C 语言库函数来说,由于很多操作系统都实现了 C 语言库,所以库函数在不同操作系统之间相比于系统调用具有更好的可移植性。
2.2 标准 I/O 库文件操作
2.2.1 FILE 指针
对于标准 I/O 库函数来说,它们的操作是围绕 FILE 指针进行的,当使用标准 I/O 库函数打开或创建一个文件时,会返回一个指向 FILE 类型对象的指针(FILE *),使用该 FILE 指针与被打开或创建的文件相关联,然后该 FILE 指针就用于后续的标准 I/O 操作(使用标准 I/O 库函数进行 I/O 操作),所以由此可知,FILE 指针的作用相当于文件描述符,只不过 FILE 指针用于标准 I/O 库函数中、而文件描述符则用于文件I/O 系统调用中。
FILE 是一个结构体数据类型,它包含了标准 I/O 库函数为管理文件所需要的所有信息,包括用于实际I/O 的文件描述符、指向文件缓冲区的指针、缓冲区的长度、当前缓冲区中的字节数以及出错标志等。FILE数据结构定义在标准 I/O 库函数头文件 stdio.h 中。
2.2.2 打开文件fopen()
#include <stdio.h>
FILE *fopen(const char *pathname, const char *mode);
·返回值:调用成功返回一个指向 FILE 类型对象的指针(FILE *),该指针与打开或创建的文件相关联,后续的标准 I/O 操作将围绕 FILE 指针进行。如果失败则返回 NULL,并设置 errno 以指示错误原因。
·pathname 参数用于指定要打开或创建的文件名。
·mode 参数用于指定文件的打开方式,注意该参数是一个字符串,输入时需要带双引号:
| mode | 说明 | 对应于open()函数的 flags 参数取值 |
|---|---|---|
| r | 以只读方式打开文件。 | O_RDONLY |
| r+ | 以可读、可写方式打开文件。 | O_RDWR |
| w | 以只写方式打开文件,如果参数 path 指定的文件存在,将文件长度截断为 0;如果指定文件不存在则创建该文件。 | O_WRONLY | O_CREAT | O_TRUNC |
| w+ | 以可读、可写方式打开文件,如果参数 path 指定的文件存在,将文件长度截断为 0;如果指定文件不存在则创建该文件。 | O_RDWR | O_CREAT | O_TRUNC |
| a | 以只写方式打开文件,打开以进行追加内容(在文件末尾写入),如果文件不存在则创建该文件。 | O_WRONLY | O_CREAT | O_APPEND |
| a+ | 以可读、可写方式打开文件,以追加方式写入(在文件末尾写入),如果文件不存在则创建该文件。 | O_RDWR | O_CREAT | O_APPEND |
2.2.3 读文件和写文件
#include <stdio.h>
//用于从文件流中读取数
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
//写文件,用于把数据写入到文件流
size_t fwrite(void *ptr, size_t size, size_t nmemb, FILE *stream);
·ptr:fread()将读取到的数据存放在参数 ptr 指向的缓冲区中;
·size:fread()从文件读取 nmemb个数据项,每一个数据项的大小为size个字节,所以总共读取的数据大小为nmemb * size个字节。
·stream:FILE 指针,是使用fopen 打开的文件流,fread 通过它指定要访问的文件,它从该文件中读取
·nmemb项数据,每项的大小为size,读取到的数据会被存储在ptr 指向的数组中。
·返回值:为成功读取的项数(项的单位为size)。
2.2.4 fclose关闭文件
用于关闭指定的文件流,关闭时它会把尚未写到文件的内容都写出。因为标准库会对数据进行缓冲,所以需要使用fclose 来确保数据被写出。
#include <unistd.h>
int close(int fd);
2.2.5 fflush 函数
用于把尚未写到文件的内容立即写出。常用于确保前面操作的数据被写入到磁盘上。fclose 函数本身也包含了fflush 的操作。
#include <stdio.h>
int fflush(FILE *stream);
2.2.6 fseek 函数
用于设置下一次读写函数操作的位置
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);
·offset 参数用于指定位置
·whence 参数则定义了offset 的意义
·whence 的可取值如下:
| 参数 | 功能 |
|---|---|
| SEEK_SET | offset是一个绝对位置。 |
| SEEK_END | offset是以文件尾为参考点的相对位置。 |
| SEEK_CUR | offset是以当前位置为参考点的相对位置。 |
⑦库函数 ftell()可用于获取文件当前的读写位置偏移量
long ftell(FILE *stream);
2.2 检查或复位状态
①feof()函数
int feof(FILE *stream);
库函数feof()用于测试参数 stream 所指文件的 end-of-file 标志,如果end-of-file标志被设置了,则调用feof()函数将返回一个非零值,如果end-of-file标志没有被设置,则返回0
②ferror()函数
int ferror(FILE *stream);
库函数 ferror()用于测试参数 stream 所指文件的错误标志,如果错误标志被设置了,则调用 ferror()函数将返回一个非零值,如果错误标志没有被设置,则返回 0。
③clearerr()函数
void clearerr(FILE *stream);
库函数 clearerr()用于清除 end-of-file 标志和错误标志,当调用 feof()或 ferror()校验这些标志后,通常需要清除这些标志,避免下次校验时使用到的是上一次设置的值,此时可以手动调用 clearerr()函数清除标志。
三、字符串
3.1 字符串常用函数
3.1.1 输入输出
- 字符串输出
#include <stdio.h>
int puts(const char *s); //输出字符串,只能输出到标准输出设备
int putchar(int c); //输出一个无符号字符,只能输出到标准输出设备
int fputc(int c, FILE *stream); //可把字符输出到指定的文件中
int fputs(const char *s, FILE *stream); //输出字符串
函数参数和返回值含义如下:
- s:需要输出的字符串。
- stream:文件指针。
- 返回值:成功返回非负数;失败将返回 EOF。
- 字符串输入
#include <stdio.h>
char *gets(char *s);
int getchar(void); //从标准输入设备中读取一个字符
char *fgets(char *s, int size, FILE *stream);
int fgetc(FILE *stream);
3.1.2 字符串长度
#include <string.h>
size_t strlen(const char *s);
sizeof 和 strlen 的区别:
- sizeof 是 C 语言内置的操作符关键字,而 strlen 是 C 语言库函数;
- sizeof 仅用于计算数据类型的大小或者变量的大小,而 strlen 只能以结尾为’ \0 '的字符串作为参数;
- 编译器在编译时就计算出了 sizeof 的结果,而 strlen 必须在运行时才能计算出来;
- sizeof 计算数据类型或变量会占用内存的大小,strlen 计算字符串实际长度。
3.1.3 字符串拼接
strncat()与 strcat()的区别在于,strncat 可以指定源字符串追加到目标字符串的字符数量
#include <string.h>
char *strcat(char *dest, const char *src);
char *strncat(char *dest, const char *src, size_t n);
函数参数和返回值含义如下:
- dest:目标字符串。
- src:源字符串。
- n:要追加的最大字符数。
3.1.4 字符串拷贝
strncpy()与 strcpy()的区别在于,strncpy()可以指定从源字符串 src 复制到目标字符串 dest 的字符数量
#include <string.h>
char *strcpy(char *dest, const char *src);
char *strncpy(char *dest, const char *src, size_t n);
函数参数和返回值含义如下:
- dest:目标字符串。
- src:源字符串。
- n:从 src 中复制的最大字符数。
- 返回值:返回指向目标字符串 dest 的指针。
3.1.5 内存填充
- memset 函数
参数 c 虽然是以 int 类型传递,但 memset()函数在填充内存块时是使用该值的无符号字符形式,也就是函数内部会将该值转换为 unsigned char 类型的数据,以字节为单位进行数据填充
#include <string.h>
void *memset(void *s, int c, size_t n);
函数参数和返回值含义如下:
- s:需要进行数据填充的内存空间起始地址。
- c:要被设置的值,该值以 int 类型传递。
- n:填充的字节数。
- 返回值:返回指向内存空间 s 的指针。
- bzero 函数
对数组 str 进行初始化操作,将其存储的数据全部设置为 0。
#include <strings.h>
void bzero(void *s, size_t n);
函数参数和返回值含义如下:
- s:内存空间的起始地址。
- n:填充的字节数。
- 返回值:无返回值。
3.1.6 字符串比较
- strcmp()函数
#include <string.h>
int strcmp(const char *s1, const char *s2);
函数参数和返回值含义如下:
- s1:进行比较的字符串 1。
- s2:进行比较的字符串 2。
- 返回值:
如果返回值小于 0,则表示 str1 小于 str2
如果返回值大于 0,则表示 str1 大于 str2
如果返回值等于 0,则表示字符串 str1 等于字符串 str2
- strncmp 函数
#include <string.h>
int strncmp(const char *s1, const char *s2, size_t n);
函数参数和返回值含义如下:
- s1:参与比较的第一个字符串。
- s2:参与比较的第二个字符串。
- n:最多比较前 n 个字符。
- 返回值:返回值含义与 strcmp()函数相同。
3.1.7 字符串查找
- strchr 函数
#include <string.h>
char *strchr(const char *s, int c);
char *strrchr(const char *s, int c);
strrchr()函数在字符串中是从后到前(或者称为从右向左)查找字符,找到字符第一次出现的位置就返回,返回值指向这个位置,
函数参数和返回值含义如下:
- s:给定的目标字符串。
- c:需要查找的字符。
- 返回值:返回字符 c 第一次在字符串 s 中出现的位置,如果未找到字符 c,则返回 NULL。
- strstr 函数
#include <string.h>
char *strstr(const char *haystack, const char *needle);
函数参数和返回值含义如下:
- haystack:目标字符串。
- needle:需要查找的子字符串。
- 返回值:如果目标字符串 haystack 中包含了子字符串 needle,则返回该字符串首次出现的位置;如果未能找到子字符串 needle,则返回 NULL。
3.2 字符串与数字互转
3.2.1 字符串转整形数据
- atoi、atol、atoll 函数
使用 atoi()、atol()、atoll()函数只能转换十进制表示的数字字符串,即 0~9。
#include <stdlib.h>
int atoi(const char *nptr);
long atol(const char *nptr);
long long atoll(const char *nptr);
函数参数和返回值含义如下:
- nptr:需要进行转换的字符串。
- 返回值:分别返回转换之后得到的 int 类型数据、long int 类型数据以及 long long 类型数据。
- strtol、strtoll 函数
strtol()、strtoll()两个函数可分别将字符串转为 long int 类型数据和 long long ing 类型数据,与 atol()、atoll()之间的区别在于,strtol()、strtoll()可以实现将多种不同进制数(譬如二进制表示的数字字符串、八进制表示的数字字符串、十六进制表示的数数字符串)表示的字符串转换为整形数据
#include <stdlib.h>
long int strtol(const char *nptr, char **endptr, int base);
long long int strtoll(const char *nptr, char **endptr, int base);
函数参数和返回值含义如下:
- nptr:需要进行转换的目标字符串。
- endptr:char **类型的指针,如果 endptr 不为 NULL,则 strtol()或 strtoll()会将字符串中第一个无效字符的地址存储在endptr 中。如果根本没有数字,strtol()或 strtoll()会将 nptr 的原始值存储在endptr 中(并返回 0)。也可将参数 endptr 设置为 NULL,表示不接收相应信息。
- base:数字基数,参数 base 必须介于 2 和 36(包含)之间,或者是特殊值 0。参数 base 决定了字符串转换为整数时合法字符的取值范围,譬如,当 base=2 时,合法字符为’ 0 ‘、’ 1 ‘(表示是一个二进制表示的数字字符串);当 base=8 时,合法字符为’ 0 ‘、’ 1 ‘、’ 2 ‘、’ 3 ‘……’ 7 ‘(表示是一个八进制表示的数字字符串);当 base=16 时,合法字符为’ 0 ’ 、’ 1 ‘、’ 2 ‘、’ 3 ‘……’ 9 ‘、’ a ‘……’ f ‘(表示是一个十六进制表示的数字字符串);当 base 大于 10 的时候,’ a ‘代表 10、’ b ‘代表 11、’ c ‘代表 12,依次类推,’ z '代表 35(不区分大小写)。
- 返回值:分别返回转换之后得到的 long int 类型数据以及 long long int 类型数据。
- strtoul、strtoull 函数
这两个函数使用方法与 strtol()、strtoll()一样,区别在于返回值的类型不同,strtoul()返回值类型是 unsigned long int,strtoull()返回值类型是 unsigned long long int
#include <stdlib.h>
unsigned long int strtoul(const char *nptr, char **endptr, int base);
unsigned long long int strtoull(const char *nptr, char **endptr, int base);
3.2.2 字符串转浮点型数据
- atof 函数
atof()用于将字符串转换为一个 double 类型的浮点数据
#include <stdlib.h>
double atof(const char *nptr);
函数参数和返回值含义如下:
- nptr:需要进行转换的字符串。
- 返回值:返回转换得到的 double 类型数据。
- strtod、strtof、strtold 函数
strtof()、strtod()以及 strtold()三个库函数可分别将字符串转换为 float 类型数据、double 类型数据、long double 类型数据
#include <stdlib.h>
double strtod(const char *nptr, char **endptr);
float strtof(const char *nptr, char **endptr);
long double strtold(const char *nptr, char **endptr);
3.2.3 数字转字符串
数字转换为字符串推荐大家使用前面介绍的格式化 IO 相关库函数,譬如使用 printf()将数字转字符串、并将其输出到标准输出设备或者使用 sprintf()或 snprintf()将数字转换为字符串并存储在缓冲区中
3.3 正则表达式
正则表达式描述了一种字符串的匹配模式(pattern),可以用来检查一个给定的字符串中是否含有某种子字符串、将匹配的字符串替换或者从某个字符串中取出符合某个条件的子字符串。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <regex.h>
#include <string.h>
int main(int argc, char *argv[])
{
regmatch_t pmatch = {0};
regex_t reg;
char errbuf[64];
int ret;
char *sptr;
int length;
int nmatch; //最多匹配出的结果
if (4 != argc) {
/**********************************
* 执行程序时需要传入两个参数:
* arg1: 正则表达式
* arg2: 待测试的字符串
* arg3: 最多匹配出多少个结果
**********************************/
fprintf(stderr, "usage: %s <regex> <string> <nmatch>\n", argv[0]);
exit(0);
}
/* 编译正则表达式 */
if(ret = regcomp(®, argv[1], REG_EXTENDED)) {
regerror(ret, ®, errbuf, sizeof(errbuf));
fprintf(stderr, "regcomp error: %s\n", errbuf);
exit(0);
}
/* 赋值操作 */
sptr = argv[2]; //待测试的字符串
length = strlen(argv[2]);//获取字符串长度
nmatch = atoi(argv[3]); //获取最大匹配数
/* 匹配正则表达式 */
for (int j = 0; j < nmatch; j++) {
char temp_str[100];
/* 调用 regexec 匹配正则表达式 */
if(ret = regexec(®, sptr, 1, &pmatch, 0)) {
regerror(ret, ®, errbuf, sizeof(errbuf));
fprintf(stderr, "regexec error: %s\n", errbuf);
goto out;
}
if(-1 != pmatch.rm_so) {
if (pmatch.rm_so == pmatch.rm_eo) {//空字符串
sptr += 1;
length -= 1;
printf("\n"); //打印出空字符串
if (0 >= length)//如果已经移动到字符串末尾、则退出
break;
continue; //从 for 循环开始执行
}
memset(temp_str, 0x00, sizeof(temp_str));//清零缓冲区
memcpy(temp_str, sptr + pmatch.rm_so,
pmatch.rm_eo - pmatch.rm_so);//将匹配出来的子字符串拷贝到缓冲区
printf("%s\n", temp_str); //打印字符串
sptr += pmatch.rm_eo;
length -= pmatch.rm_eo;
if (0 >= length)
break;
}
}
/* 释放正则表达式 */
out:
regfree(®);
exit(0);
}
四、进程与线程
4.1 进程相关概念
①进程概念
进程是一个动态过程,而非静态文件,它是程序的一次运行过程,当应用程序被加载到内存中运行之后它就称为了一个进程,当程序运行结束后也就意味着进程终止,这就是进程的一个生命周期。Linux 系统下的每一个进程都有一个进程号(processID,简称 PID),进程号是一个正数,用于唯一标识系统中的某一个进程。
②环境变量的作用
环境变量常见的用途之一是在 shell 中,每一个环境变量都有它所表示的含义,譬如 HOME 环境变量表示用户的家目录,USER 环境变量表示当前用户名,SHELL 环境变量表示 shell 解析器名称,PWD 环境变量表示当前所在目录等,在我们自己的应用程序当中,也可以使用进程的环境变量。
4.2 进程内存
①内存布局
- 正文段:也可称为代码段,这是 CPU 执行的机器语言指令部分,文本段具有只读属性,以防止程序由于意外而修改其指令;正文段是可以共享的,即使在多个进程间也可同时运行同一段程序。
· 初始化数据段:通常将此段称为数据段,包含了显式初始化的全局变量和静态变量,当程序加载到内存中时,从可执行文件中读取这些变量的值。 - 未初始化数据段:包含了未进行显式初始化的全局变量和静态变量,通常将此段称为 bss 段,这一名词来源于早期汇编程序中的一个操作符,意思是“由符号开始的块”(block started by symbol),在程序开始执行之前,系统会将本段内所有内存初始化为 0,可执行文件并没有为 bss 段变量分配存储空间,在可执行文件中只需记录 bss 段的位置及其所需大小,直到程序运行时,由加载器来分配这一段内存空间。
- 栈:函数内的局部变量以及每次函数调用时所需保存的信息都放在此段中,每次调用函数时,函数传递的实参以及函数返回值等也都存放在栈中。栈是一个动态增长和收缩的段,由栈帧组成,系统会为每个当前调用的函数分配一个栈帧,栈帧中存储了函数的局部变量(所谓自动变量)、实参和返回值。
- 堆:可在运行时动态进行内存分配的一块区域,譬如使用 malloc()分配的内存空间,就是从系统堆内存中申请分配的。
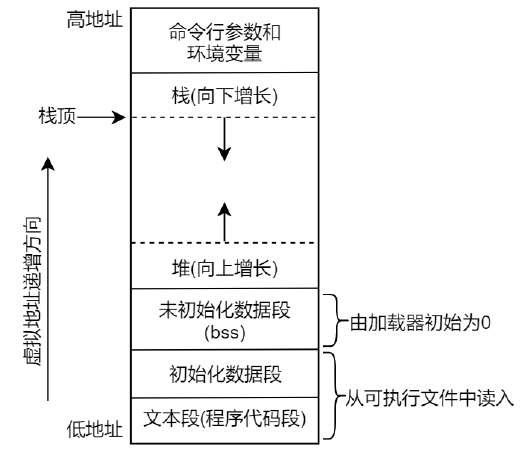
②虚拟地址空间
在 Linux 系统中,每一个进程都在自己独立的地址空间中运行,在 32 位系统中,每个进程的逻辑地址空间均为 4GB,这 4GB 的内存空间按照 3:1 的比例进行分配,其中用户进程享有 3G 的空间,而内核独自享有剩下的 1G 空间

4.3 父、子进程间的文件共享
调用 fork()函数之后,子进程会获得父进程所有文件描述符的副本,这些副本的创建方式类似于 dup(),这也意味着父、子进程对应的文件描述符均指向相同的文件表,如下图所示:

4.4 进程间通信
Linux 内核提供了多种 IPC 机制,基本是从 UNIX 系统继承而来,而对 UNIX 发展做出重大贡献的两大主力 AT&T 的贝尔实验室及 BSD(加州大学伯克利分校的伯克利软件发布中心)在进程间通信方面的侧重点有所不同。前者对 UNIX 早期的进程间通信手段进行了系统的改进和扩充,形成了“System V IPC”,通信进程局限在单个计算机内;后者则跳过了该限制,形成了基于套接字(Socket,也就是网络)的进程间通信机制。Linux 则把两者继承了下来,如下如所示:
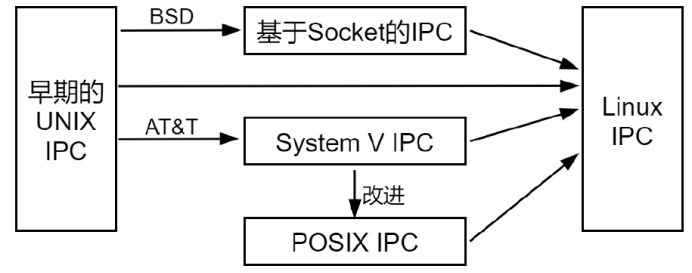
其中,早期的 UNIX IPC 包括:管道、FIFO、信号;System V IPC 包括:System V 信号量、System V消息队列、System V 共享内存;上图中还出现了 POSIX IPC,事实上,较早的 System V IPC 存在着一些不足之处,而 POSIX IPC 则是在 System V IPC 的基础上进行改进所形成的,弥补了 System V IPC 的一些不足之处。POSIX IPC 包括:POSIX 信号量、POSIX 消息队列、POSIX 共享内存。总结如下:
- UNIX IPC:管道、FIFO、信号;
- System V IPC:信号量、消息队列、共享内存;
- POSIX IPC:信号量、消息队列、共享内存;
- Socket IPC:基于 Socket 进程间通信。
4.5 线程基本概念
线程是操作系统能够调度和执行的基本单位,在 Linux 中也被称之为轻量级进程。在 Linux 系统中,一个进程至少需要一个线程作为它的指令执行体,进程管理着资源(比如 cpu、内存、文件等等),而将线程分配到某个 cpu 上执行。一个进程可以拥有多个线程,它还可以同时使用多个cpu 来执行各个线程,以达到最大程度的并行,提高工作的效率;同时,即使是在单 cpu 的机器上,也依然可以采用多线程模型来设计程序,使设计更简洁、功能更完备,程序的执行效率也更高
4.6 并发和并行
并行与串行则截然不同,并行指的是可以并排/并列执行多个任务,这样的系统,它通常有多个执行单元,所以可以实现并行运行,譬如并行运行 task1、task2、task3。并行运行并不一定要同时开始运行、同时结束运行,只需满足在某一个时间段上存在多个任务被多个执行单元同时在运行着
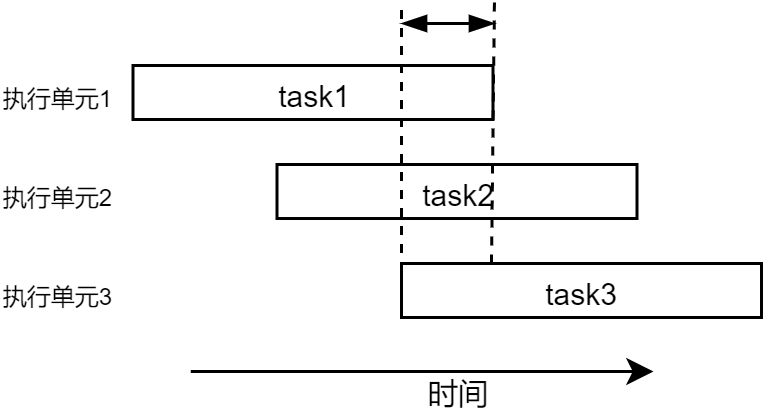
相比于串行和并行,并发强调的是一种时分复用,与串行的区别在于,它不必等待上一个任务完成之后在做下一个任务,可以打断当前执行的任务切换执行下一个任何,这就是时分复用。在同一个执行单元上,将时间分解成不同的片段(时间片),每个任务执行一段时间,时间一到则切换执行下一个任务,依次这样轮训(交叉/交替执行),这就是并发运行。如下图所示:

4.7 线程同步
对于一个单线程进程来说,它不需要处理线程同步的问题,所以线程
同步是在多线程环境下可能需要注意的一个问题。线程的主要优势在于,资源的共享性,譬如通过全局变量来实现信息共享,不过这种便捷的共享是有代价的,那就是多个线程并发访问共享数据所导致的数据不一致的问题。
- 线程同步是为了对共享资源的访问进行保护。
- 保护的目的是为了解决数据一致性的问题。
- 出现数据一致性问题其本质在于进程中的多个线程对共享资源的并发访问(同时访问)
当一个线程修改变量时,其它的线程在读取这个变量时可能会看到不一致的值,图 12.1.1 描述了两个线程读写相同变量(共享变量、共享资源)的假设例子。在这个例子当中,线程 A 读取变量的值,然后再给这个变量赋予一个新的值,但写操作需要 2 个时钟周期(这里只是假设);当线程 B 在这两个写周期中间读取了这个变量,它就会得到不一致的值,这就出现了数据不一致的问题。
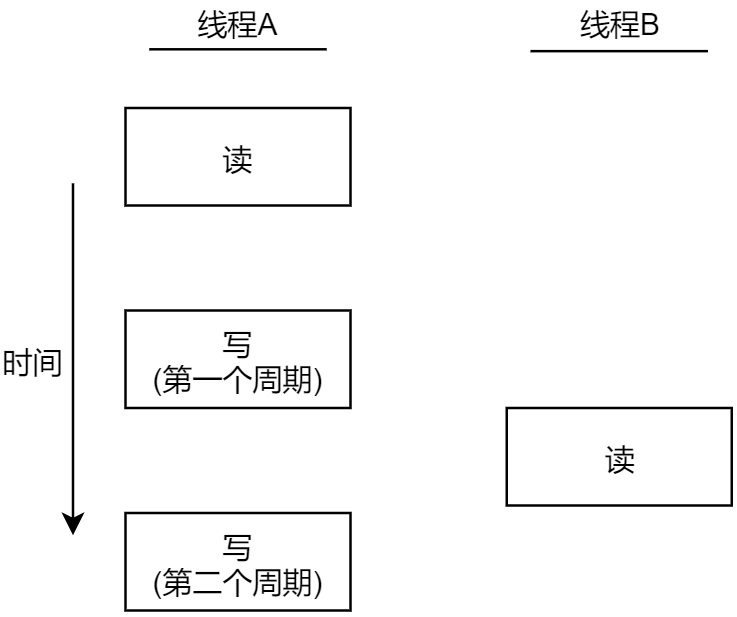
一般有以下同步方式:
- 线程同步之互斥锁;
- 线程同步之信号量;
- 线程同步之条件变量;
- 线程同步之读写锁。
五、信号
5.1 基本概念
信号是事件发生时对进程的通知机制,也可以把它称为软件中断。信号与硬件中断的相似之处在于能够打断程序当前执行的正常流程,其实是在软件层次上对中断机制的一种模拟。大多数情况下,是无法预测信号达到的准确时间,所以信号提供了一种处理异步事件的方法。
- 信号的目的是用来通信的
- 信号通常是发送给对应的进程
- 信号是异步的,产生信号的事件对进程而言是随机出现的
- 信号本质上是 int 类型数字编号,这些信号在<signum.h>头文件中定义:
| 信号名称 | 编号 | 描述 | 系统默认操作 |
|---|---|---|---|
| SIGHUP | 1 | Hangup (POSIX) | |
| SIGINT | 2 | 终端中断符 | term |
| SIGQUIT | 3 | 终端退出符 | term+core |
| SIGILL | 4 | 非法硬件指令 | term+core |
| SIGTRAP | 5 | Trace trap (POSIX) | |
| SIGABRT | 6 | 异常终止(abort) | term+core |
| SIGBUS | 7 | 内存访问错误 | term+core |
| SIGFPE | 8 | 算术异常 | term+core |
| SIGKILL | 9 | 终极终止信号 | term |
| SIGUSR1 | 10 | 用户自定义信号 1 | term |
| SIGSEGV | 11 | 无效的内存引用 | term+core |
| SIGUSR2 | 12 | 用户自定义信号 2 | term |
| SIGPIPE | 13 | 管道关闭 | term |
| SIGALRM | 14 | 定时器超时(alarm) | term |
| SIGTERM | 15 | 终止进程 | term |
| SIGSTKFLT | 16 | Stack fault. | |
| SIGCHLD/SIGCLD | 17 | 子进程终止或停止 | ignore |
| SIGCONT | 18 | 使停止状态的进程继续运行 | cont |
| SIGSTOP | 19 | 停止进程 | stop |
| SIGTSTP | 20 | 终端停止符 | stop |
| SIGXCPU | 24 | 超过 CPU 限制 | term+core |
| SIGVTALRM | 26 | 虚拟定时器超时 | term |
| SIGWINCH | 28 | 终端窗口尺寸发生变化 | ignore |
| SIGPOLL/SIGIO | 29 | 异步 I/O | term/ignore |
| SIGSYS | 31 | 无效系统调用 | term+core |
信号的分类:
从可靠性方面将信号分为可靠信号与不可靠信号
从实时性方面将信号分为实时信号与非实时信号
实时信号与非实时信号其实是从时间关系上进行的分类,与可靠信号与不可靠信号是相互对应的,非实时信号都不支持排队,都是不可靠信号;实时信号都支持排队,都是可靠信号。实时信号保证了发送的多个信号都能被接收,实时信号是 POSIX 标准的一部分,可用于应用进程。一般我们也把非实时信号(不可靠信号)称为标准信号
5.2 进程对信号的处理
5.2.1 signal()函数
signal()函数是 Linux 系统下设置信号处理方式最简单的接口,可将信号的
处理方式设置为捕获信号、忽略信号以及系统默认操作
#include <signal.h>
typedef void (*sig_t)(int);
sig_t signal(int signum, sig_t handler);
函数参数和返回值含义如下:
- signum:此参数指定需要进行设置的信号,可使用信号名(宏)或信号的数字编号,建议使用信号名。
- handler:sig_t 类型的函数指针,指向信号对应的信号处理函数,当进程接收到信号后会自动执行该处理函数;参数 handler 既可以设置为用户自定义的函数,也就是捕获信号时需要执行的处理函数,也可以设置为 SIG_IGN 或 SIG_DFL,SIG_IGN 表示此进程需要忽略该信号,SIG_DFL 则表示设置为系统默认操作。sig_t 函数指针的 int 类型参数指的是,当前触发该函数的信号,可将多个信号绑定到同一个信号处理函数上,此时就可通过此参数来判断当前触发的是哪个信号。
Tips:SIG_IGN、SIG_DFL 分别取值如下:
/* Fake signal functions. */
#define SIG_ERR ((sig_t) -1) /* Error return. */
#define SIG_DFL ((sig_t) 0) /* Default action. */
#define SIG_IGN ((sig_t) 1) /* Ignore signal. */
- 返回值:此函数的返回值也是一个 sig_t 类型的函数指针,成功情况下的返回值则是指向在此之前的信号处理函数;如果出错则返回 SIG_ERR,并会设置 errno。
5.2.2 gaction()
gaction()允许单独获取信号的处理函数而不是设置,并且还可以设置各种属性对调用信号处理函数时的行为施以更加精准的控制
#include <signal.h>
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
- signum:需要设置的信号,除了 SIGKILL 信号和 SIGSTOP 信号之外的任何信号。
- act:act 参数是一个 struct sigaction 类型指针,指向一个 struct sigaction 数据结构,该数据结构描述了信号的处理方式,稍后介绍该数据结构;如果参数 act 不为 NULL,则表示需要为信号设置新的处理方式;如果参数 act 为 NULL,则表示无需改变信号当前的处理方式。
- oldact:oldact 参数也是一个 struct sigaction 类型指针,指向一个 struct sigaction 数据结构。如果参数oldact 不为 NULL,则会将信号之前的处理方式等信息通过参数 oldact 返回出来;如果无意获取此类信息,那么可将该参数设置为 NULL。
- 返回值:成功返回 0;失败将返回-1,并设置 errno。
5.3 向进程发送信号
与 kill 命令相类似,Linux 系统提供了 kill()系统调用,一个进程可通过 kill()向另一个进程发送信号;除了 kill()系统调用之外,Linux 系统还提供了系统调用 killpg()以及库函数 raise(),也可用于实现发送信号的功能,
5.3.1 kill()函数
kill()系统调用可将信号发送给指定的进程或进程组中的每一个进程
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);
函数参数和返回值含义如下:
- pid:参数 pid 为正数的情况下,用于指定接收此信号的进程 pid;除此之外,参数 pid 也可设置为 0 或 -1 以及小于-1 等不同值,稍后给说明。
- sig:参数 sig 指定需要发送的信号,也可设置为 0,如果参数 sig 设置为 0 则表示不发送信号,但任执行错误检查,这通常可用于检查参数 pid 指定的进程是否存在。
- 返回值:成功返回 0;失败将返回-1,并设置 errno。
参数 pid 不同取值含义:
- 如果 pid 为正,则信号 sig 将发送到 pid 指定的进程。
- 如果 pid 等于 0,则将 sig 发送到当前进程的进程组中的每个进程。
- 如果 pid 等于-1,则将 sig 发送到当前进程有权发送信号的每个进程,但进程 1(init)除外。
- 如果 pid 小于-1,则将 sig 发送到 ID 为-pid 的进程组中的每个进程。
5.3.2 raise()
有时进程需要向自身发送信号,raise()函数可用于实现这一要求
#include <signal.h>
int raise(int sig);
函数参数和返回值含义如下:
- sig:需要发送的信号。
- 返回值:成功返回 0;失败将返回非零值。
5.3.3 alarm()函数
使用 alarm()函数可以设置一个定时器(闹钟),当定时器定时时间到时,内核会向进程发送 SIGALRM信号
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
函数参数和返回值:
- seconds:设置定时时间,以秒为单位;如果参数 seconds 等于 0,则表示取消之前设置的 alarm 闹钟。
- 返回值:如果在调用 alarm()时,之前已经为该进程设置了 alarm 闹钟还没有超时,则该闹钟的剩余值作为本次 alarm()函数调用的返回值,之前设置的闹钟则被新的替代;否则返回 0。
5.3.4 pause()函数
pause()系统调用可以使得进程暂停运行、进入休眠状态,直到进程捕获到一个信号为止,只有执行了信号处理函数并从其返回时,pause()才返回,在这种情况下,pause()返回-1,并且将 errno 设置为 EINTR
5.4 实时信号
5.4.1 sigpending()函数
如果进程当前正在执行信号处理函数,在处理信号期间接收到了新的信号,如果该信号是信号掩码中的成员,那么内核会将其阻塞,将该信号添加到进程的等待信号集(等待被处理,处于等待状态的信号)中,为了确定进程中处于等待状态的是哪些信号,可以使用 sigpending()函数获取。
#include <signal.h>
int sigpending(sigset_t *set);
函数参数和返回值含义如下:
- set:处于等待状态的信号会存放在参数 set 所指向的信号集中。
- 返回值:成功返回 0;失败将返回-1,并设置 errno。
判断 SIGINT 信号当前是否处于等待状态:
/* 定义信号集 */
sigset_t sig_set;
/* 将信号集初始化为空 */
sigemptyset(&sig_set);
/* 获取当前处于等待状态的信号 */
sigpending(&sig_set);
/* 判断 SIGINT 信号是否处于等待状态 */
if (1 == sigismember(&sig_set, SIGINT))
puts("SIGINT 信号处于等待状态");
else if (!sigismember(&sig_set, SIGINT))
puts("SIGINT 信号未处于等待状态");
5.4.2 发送实时信号
#include <signal.h>
int sigqueue(pid_t pid, int sig, const union sigval value);
函数参数和返回值含义如下:
- pid:指定接收信号的进程对应的 pid,将信号发送给该进程。
- sig:指定需要发送的信号。与 kill()函数一样,也可将参数 sig 设置为 0,用于检查参数 pid 所指定的进程是否存在。
- value:参数 value 指定了信号的伴随数据,union sigval 数据类型
- 返回值:成功将返回 0;失败将返回-1,并设置 errno。
5.5 异常退出 abort()函数
使用 exit()、_exit()或_Exit()这些函数来终止进程,然后这些方法使用于正常退出应用程序,而对于异常退出程序,则一般使用 abort()库函数,使用 abort()终止进程运行,会生成核心转储文件,可用于判断程序调用 abort()时的程序状态。
#include <stdlib.h>
void abort(void);
函数 abort()通常产生 SIGABRT 信号来终止调用该函数的进程,SIGABRT 信号的系统默认操作是终止进程运行、并生成核心转储文件;当调用 abort()函数之后,内核会向进程发送 SIGABRT 信号。
六、管道
6.1 管道的基本概念
一个信号从进程中产生,发送给另一个进程,这其实也是信号类型的通信,不过由于只传递信号值,没有数据传递,在很多时候无法满足我们的需求,因此管道传输数据的功能在某些场合会很有优势。
什么是管道呢?当数据从一个进程连接流到另一个进程时,这之间的连接就是一个管道(pipe)。我们通常是把一个进程的输出通过管道连接到另一个进程的输入。对于 shell 命令来说,命令的连接是通过管道字符来完成的
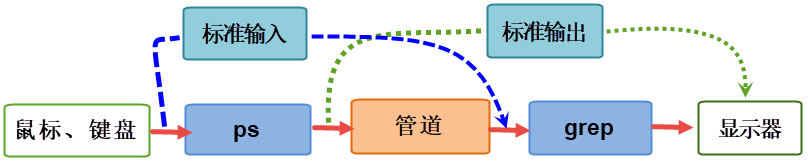
6.2 管道的分类
6.2.1 匿名管道 PIPE
匿名管道(PIPE)是一种特殊的文件,但虽然它是一种文件,却没有名字,因此一般进程无法使用 open() 来获取他的描述符,它只能在一个进程中被创建出来,然后通过继承的方式将他的文件描述符传递给子进程,这就是为什么匿名管道只能用于亲缘关系进程间通信的原因。另外,匿名管道不同于一般文件的显著之处是:它有两个文件描述符,而不是一个,一个只能用来读,另一个只能用来写,这就是所谓的“半双工”通信方式。而且它对写操作不做任何保护,即:假如有多个进程或线程同时对匿名管道进行写操作,那么这些数据很有可能会相互践踏,因此一个简单的结论是:匿名管道只能用于一对一的亲缘进程通信。最后,匿名管道不能使用 lseek() 来进行所谓的定位,因为他们的数据不像普通文件那样按块的方式存放在诸如硬盘、flash 等块设备上。
6.2.2 命名管道 FIFO
命名管道(FIFO)与匿名管道(PIPE)是不同的,命名管道可以在多个无关的进程中交换数据(通信)。我们知道,匿名管道的通信方式通常都由一个共同的祖先进程启动,只能在”有血缘关系”的进程中交互数据,这给我们在不相关的的进程之间交换数据带来了不方便,因此产生了命名管道,来解决不相关进程间的通信问题。
命名管道不同于无名管道之处在于它提供了一个路径名与之关联,以一个文件形式存在于文件系统中,这样,即使与命名管道的创建进程不存在“血缘关系”的进程,只要可以访问该命名管道文件的路径,就能够彼此通过命名管道相互通信,因为可以通过文件的形式,那么就可以调用系统中对文件的操作,如打开(open)、读(read)、写(write)、关闭(close)等函数,虽然命名管道文件存储在文件系统中,但数据却是存在于内存中的,这点要区分开。
6.3 pipe() 函数
pipe() 函数用于创建一个匿名管道,一个可用于进程间通信的单向数据通道
#include <unistd.h>
int pipe(int pipefd[2]);
**注意:**数组 pipefd 是用于返回两个引用管道末端的文
件描述符,它是一个由两个文件描述符组成的数组的指针。pipefd[0] 指管道的读取端,pipefd[1]指向管道的写端,向管道的写入端写入数据将会由内核缓冲,即写入内存中,直到从管道的读取端读取数据为止,而且数据遵循先进先出原则。pipe() 函数还会返回一个 int 类型的变量,如果为0 则表示创建匿名管道成功,如果为-1 则表示创建失败,并且设置 errno。
6.4 fifo() 函数
至此,我们还只能在有“血缘关系”的程序之间传递数据,即这些程序是由一个共同的祖先进程启动的。但如果想在不相关的进程之间交换数据,我们可以用 FIFO 文件来完成这项工作,或者称之为命名管道。命名管道是一种特殊类型的文件,它在文件系统中以文件名的形式存在,但它的的数据却是存储在内存中的。我们可以在终端(命令行)上创建命名管道,也可以在程序中创建它。
int mkfifo(const char * pathname,mode_t mode);
mkfifo() 会根据参数 pathname 建立特殊的 FIFO 文件,而参数 mode 为该文件的模式与权限。
mkfifo() 创建的 FIFO 文件其他进程都可以进行读写操作,可以使用读写一般文件的方式操作它,如 open,read,write,close 等。
mode 模式及权限参数说明:
- O_RDONLY:读管道。
- O_WRONLY:写管道。
- O_RDWR:读写管道。
- O_NONBLOCK:非阻塞。
- O_CREAT:如果该文件不存在,那么就创建一个新的文件,并用第三个参数为其设置权限。
- O_EXCL:如果使用 O_CREAT 时文件存在,那么可返回错误消息。这一参数可测试文件是否存在。
函数返回值说明如下:
- 0:成功
- EACCESS:参数 filename 所指定的目录路径无可执行的权限。
- EEXIST:参数 filename 所指定的文件已存在。
- ENAMETOOLONG:参数 filename 的路径名称太长。
- ENOENT:参数 filename 包含的目录不存在。
- ENOSPC:文件系统的剩余空间不足。
- ENOTDIR:参数 filename 路径中的目录存在但却非真正的目录。
- EROFS:参数 filename 指定的文件存在于只读文件系统内。
七、消息队列
7.1 基本概念
消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。我们可以通过发送消息来避免命名管道的同步和阻塞问题。
消息队列与信号的对比:
信号承载的信息量少,而消息队列可以承载大量自定义的数据。
消息队列与管道的对比:
• 消息队列跟命名管道有不少的相同之处,它与命名管道一样,消息队列进行通信的进程可以是不相关的进程,同时它们都是通过发送和接收的方式来传递数据的。在命名管道中,发送数据用write(),接收数据用 read(),则在消息队列中,发送数据用msgsnd(),接收数据用msgrcv(),消息队列对每个数据都有一个最大长度的限制。
• 消息队列也可以独立于发送和接收进程而存在,在进程终止时,消息队列及其内容并不会被删除。
• 管道只能承载无格式字节流,消息队列提供有格式的字节流,可以减少了开发人员的工作量。
• 消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级,接收程序可以通过消息类型有选择地接收数据,而不是像命名管道中那样,只能默认地接收。
• 消息队列可以实现消息的随机查询,消息不一定要以先进先出的顺序接收,也可以按消息的类型接收。
7.2 消息队列函数
Linux 内核提供了一系列函数来使用消息队列:
- 其中创建或打开消息队列使用的函数是 msgget(),这里创建的消息队列的数量会受到系统可支持的消息队列数量的限制;
- 发送消息使用的函数是 msgsnd() 函数,它把消息发送到已打开的消息队列末尾;
- 接收消息使用的函数是 msgrcv(),它把消息从消息队列中取走,与 FIFO 不同的是,这里可以指定取走某一条消息;
- 最后控制消息队列使用的函数是 msgctl(),它可以完成多项功能。
7.2.1 msgget() 获取函数
收发消息前需要具体的消息队列对象,msgget() 函数的作用是创建或获取一个消息队列对象,并返回消息队列标识符。函数原型如下:
int msgget(key_t key, int msgflg);
若执行成功返回队列 ID,失败返回-1。它的两个输入参数说明如下:
- key:消息队列的关键字值,多个进程可以通过它访问同一个消息队列。例如收发进程都使用同一个键值即可使用同一个消息队列进行通讯。其中有个特殊值 IPC_PRIVATE,它用于创建当前进程的私有消息队列。
- msgflg:表示创建的消息队列的模式标志参数,主要有 IPC_CREAT,IPC_EXCL 和权限 mode
7.2.2 msgsnd() 发送函数
这个函数的主要作用就是将消息写入到消息队列,俗称发送一个消息
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
参数说明:
- msqid:消息队列标识符。
- msgp:发送给队列的消息。msgp 可以是任何类型的结构体,但第一个字段必须为 long 类型,即表明此发送消息的类型,msgrcv() 函数则根据此接收消息
7.2.3 msgrcv() 接收函数
msgrcv() 函数是从标识符为 msqid 的消息队列读取消息并将消息存储到 msgp 中,读取后把此消息从消息队列中删除,也就是俗话说的接收消息
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
参数说明:
- msqid:消息队列标识符。
- msgp:存放消息的结构体,结构体类型要与 msgsnd() 函数发送的类型相同。
- msgsz:要接收消息的大小,不包含消息类型占用的 4 个字节。
- msgtyp 有多个可选的值:如果为 0 则表示接收第一个消息,如果大于 0 则表示接收类型等于 msgtyp 的第一个消息,而如果小于 0 则表示接收类型等于或者小于 msgtyp 绝对值的第一个消息。
- msgflg 用于设置接收的处理方式,取值情况如下:
– 0: 阻塞式接收消息,没有该类型的消息 msgrcv 函数一直阻塞等待
– IPC_NOWAIT:若在消息队列中并没有相应类型的消息可以接收,则函数立即返回,此时错误码为 ENOMSG
– IPC_EXCEPT:与 msgtype 配合使用返回队列中第一个类型不为 msgtype 的消息
– IPC_NOERROR:如果队列中满足条件的消息内容大于所请求的 size 字节,则把该消息截断,截断部分将被丢弃
- 返回值:msgrcv() 函数如果接收消息成功则返回实际读取到的消息数据长度,否则返回-1
7.2.4 msgctl() 操作消息队列
消息队列是可以被用户操作的,比如设置或者获取消息队列的相关属性
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
参数说明:
- msqid:消息队列标识符。
- cmd 用于设置使用什么操作命令
- buf:相关信息结构体缓冲区。
八、共享内存
8.1 共享内存基本概念
什么是共享内存?顾名思义,共享内存就是将内存进行共享,它允许多个不相关的进程访问同一个逻辑内存,直接将一块裸露的内存放在需要数据传输的进程面前,让它们自己使用。因此,共享内存是效率最高的一种 IPC 通信机制,它可以在多个进程之间共享和传递数据,进程间需要共享的数据被放在共享内存区域,所有需要访问该共享区域的进程都要把该共享区域映射到本进程的地址空间中去,因此所有进程都可以访问共享内存中的地址,就好像它们是由用 C 语言函数 malloc 分配的内存一样。
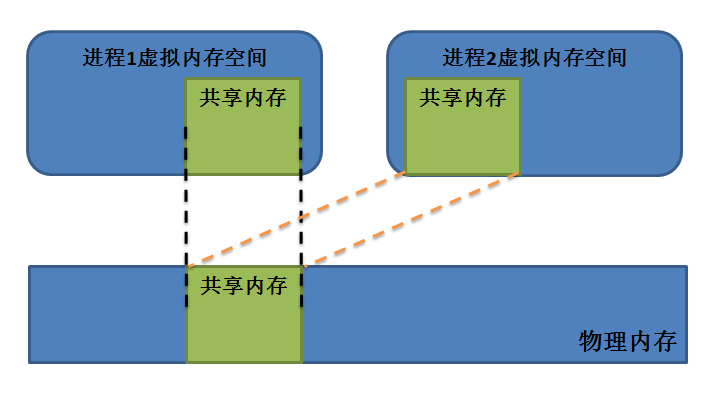
8.2 shmget() 创建共享内存函数
int shmget(key_t key, size_t size, int shmflg);
参数说明:
- key:标识共享内存的键值,可以有以下取值:
– 0 或 IPC_PRIVATE。当 key 的取值为 IPC_PRIVATE,则函数 shmget() 创建一块新的共享内存;如果 key 的取值为 0,而参数 shmflg 中设置了 IPC_PRIVATE 这个标志,则同样将创建一块新的共享内存。
– 大于 0 的 32 位整数:视参数 shmflg 来确定操作。
- size:要创建共享内存的大小,所有的内存分配操作都是以页为单位的,所以即使只申请只有一个字节的内存,内存也会分配整整一页。
- shmflg:表示创建的共享内存的模式标志参数,在真正使用时需要与 IPC 对象存取权限 mode(如 0600)进行“|”运算来确定共享内存的存取权限。msgflg 有多种情况:
– IPC_CREAT:如果内核中不存在关键字与 key 相等的共享内存,则新建一个共享内存;如果存在这样的共享内存,返回此共享内存的标识符。
– IPC_EXCL:如果内核中不存在键值与 key 相等的共享内存,则新建一个共享内存;如
果存在这样的共享内存则报错。
– SHM_HUGETLB:使用“大页面”来分配共享内存,所谓的“大页面”指的是内核为了提高程序性能,对内存实行分页管理时,采用比默认尺寸(4KB)更大的分页,以减少缺页中断。Linux 内核支持以 2MB 作为物理页面分页的基本单位。
– SHM_NORESERVE:不在交换分区中为这块共享内存保留空间。
- 返回值:shmget() 函数的返回值是共享内存的 ID。
8.3 shmat() 映射函数
如果一个进程想要访问这个共享内存,那么需要将其映射到进程的虚拟空间中,然后再去访问它,那么系统提供的 shmat() 函数就是把共享内存区对象映射到调用进程的地址空间。
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数说明:
- shmid:共享内存 ID,通常是由 shmget() 函数返回的。
- shmaddr:如果不为 NULL,则系统会根据 shmaddr 来选择一个合适的内存区域,如果为NULL,则系统会自动选择一个合适的虚拟内存空间地址去映射共享内存。
- shmflg:操作共享内存的方式:
– SHM_RDONLY:以只读方式映射共享内存。
– SHM_REMAP:重新映射,此时 shmaddr 不能为 NULL。
– NULLSHM:自动选择比 shmaddr 小的最大页对齐地址。
8.4 shmdt() 解除映射函数
int shmdt(const void *shmaddr);
参数说明:
- shmaddr:映射的共享内存的起始地址。
- 返回值:成功返回 0,如果出错则返回-1,并且将错误原因存于 error 中。
8.5 shmctl() 获取或设置属性函数
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数说明:
- shmid:共享内存标识符。
- cmd:函数功能的控制命令
- buf:共享内存属性信息结构体指针,设置或者获取信息都通过该结构体
九、信号量
9.1 system-V IPC 信号量基本概念
信号量与已经介绍过的信号、管道、FIFO 以及消息列队不同,它本质上是一个计数器,用于协调多进程间对共享数据对象的读取,它不以传送数据为主要目的,它主要是用来保护共享资源(信号量也属于临界资源),使得该临界资源在一个时刻只有一个进程独享。可能会有同学问了,为什么不使用全局变量呢?那是因为全局变量并不能在进程间共同使用,因为进程间是相互独立的,而且也无法保证引用计数的原子操作,因此使用系统提供的信号量即可。
9.2 IPC 信号量工作原理
由于信号量只能进行两种操作:等待和发送信号,即 P 操作和 V 操作,锁行为就是 P 操作,解锁就是 V 操作,可以直接理解为 P 操作是申请资源,V 操作是释放资源。PV 操作是计算机操作系统需要提供的基本功能之一,它们的行为是这样的:
- P 操作:如果有可用的资源(信号量值大于 0),则占用一个资源(给信号量值减去一,进入临界区代码); 如果没有可用的资源(信号量值等于 0),则阻塞,直到系统将资源分配给该进程(进入等待队列,一直等到资源轮到该进程)。这就像你要把车开进停车场之前,先要向保安申请一张停车卡一样,P 操作就是申请资源,如果申请成功,资源数(空闲的停车位)将会减少一个,如果申请失败,要不在门口等,要不就走人。
- V 操作:如果在该信号量的等待队列中有进程在等待资源,则唤醒一个阻塞的进程。如果没有进程等待它,则释放一个资源(给信号量值加一),就跟你从停车场出去的时候一样,空闲的停车位就会增加一个。
9.3 IPC 信号量相关函数
9.3.1 semget 创建/获取函数
semget 函数的功能是创建或者获取一个已经创建的信号量,如果成功则返回对应的信号量标识符,失败则返回-1
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semget(key_t key, int nsems, int semflg);
参数说明:
- key:与消息队列一样的是,参数 key 用来标识系统内的信号量,如果指定的 key 已经存在,则意味着打开这个信号量,这时 nsems 参数指定为 0,semflg 参数也指定为 0。特别地,可以使用 IPC_PRIVATE 创建一个没有 key 的信号量。
- nsems:本参数用于在创建信号量的时候,表示可用的信号量数目。
- semflg:semflg 参数用来指定标志位,与消息队列中的类似。主要有 IPC_CREAT,IPC_EXCL和权限 mode,其中使用 IPC_CREAT 标志创建新的信号量,即使该信号量已经存在(具有同一个键值的信号量已在系统中存在),也不会出错。如果同时使用 IPC_EXCL 标志可以创建一个新的唯一的信号量,此时如果该信号量已经存在,该函数会返回出错。
9.3.2 semop() PV 操作函数
int semop(int semid, struct sembuf *sops, size_t nsops);
参数说明:
- semid:System V 信号量的标识符,用来标识一个信号量。
- sops:是指向一个 struct sembuf 结构体数组的指针,该数组是一个信号量操作数组
9.3.3 semctl() 属性函数
semctl 函数主要是对信号量集的一系列控制操作,根据操作命令 cmd 的不同,执行不同的操作
int semctl(int semid, int semnum, int cmd, ...);
- semid:System V 信号量的标识符;
- semnum:表示信号量集中的第 semnum 个信号量。它的取值范围:0 ~ nsems-1 。
- cmd:操作命令
9.4 POSIX 信号量基本概念
信号量(Semaphore)是一种实现进程/线程间通信的机制,可以实现进程/线程之间同步或临界资源的互斥访问,常用于协助一组相互竞争的进程/线程来访问临界资源。在多进程/线程系统中,各进程/线程之间需要同步或互斥实现临界资源的保护,信号量功能可以为用户提供这方面的支持。
在 POSIX 标准中,信号量分两种,一种是无名信号量,一种是有名信号量。无名信号量一般用于进程/线程间同步或互斥,而有名信号量一般用于进程间同步或互斥。有名信号量和无名信号量的差异在于创建和销毁的形式上,但是其他工作一样,无名信号量则直接保存在内存中,而有名信号量则要求创建一个文件。
9.5 POSIX 信号量操作
- P 操作:如果有可用的资源(信号量值大于 0),则占用一个资源(给信号量值减去一,进入临界区代码); 如果没有可用的资源(信号量值等于 0),则被阻塞到,直到系统将资源分配给该进程/线程(进入等待队列,一直等到资源轮到该进程/线程)。这就像你要把车开进停车场之前,先要向保安申请一张停车卡一样,P 操作就是申请资源,如果申请成功,资源数(空闲的停车位)将会减少一个,如果申请失败,要不在门口等,要不就走人。
- V 操作:如果在该信号量的等待队列中有进程/线程在等待资源,则唤醒一个阻塞的进程/线程。如果没有进程/线程等待它,则释放一个资源(给信号量值加一),就跟你从停车场出去的时候一样,空闲的停车位就会增加一个。
9.6 POSIX有名信号量
有名信号量其实是一个文件,它的名字由类似 “sem.[信号量名字]”这样的字符串组成,注意看文件名前面有 “sem.”,它是一个特殊的信号量文件,在创建成功之后,系统会将其放置在/dev/shm 路径下,不同的进程间只要约定好一个相同的信号量文件名字,就可以访问到对应的有名信号量,并且借助信号量来进行同步或者互斥操作,需要注意的是,有名信号量是一个文件,在进程退出之后它们并不会自动消失,而需要手工删除并释放资源。
sem_t *sem_open(const char *name, int oflag, mode_t mode, unsigned int value);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t *sem);
int sem_close(sem_t *sem);
int sem_unlink(const char *name);
- sem_open() 函数用于打开/创建一个有名信号量
- sem_wait() 函数是等待(获取)信号量,如果信号量的值大于 0,将信号量的值减 1,立即返回。如果信号量的值为 0,则进程/线程阻塞。相当于 P 操作。成功返回 0,失败返回-1。
- sem_trywait() 函数也是等待信号量,如果指定信号量的计数器为 0,那么直接返回 EAGAIN错误,而不是阻塞等待。
- sem_post() 函数是释放信号量,让信号量的值加 1,相当于 V 操作。成功返回 0,失败返回-1
- sem_close() 函数用于关闭一个信号量,这表示当前进程/线程取消对信号量的使用
- sem_unlink() 函数就是主动删除一个信号量,直接删除指定名字的信号量文件。
9.7 POSIX 无名信号量
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t *sem);
- sem_init():初始化信号量。
- sem_destroy():销毁信号量,其中 sem 是要销毁的信号量。只有用 sem_init 初始化的信号量才能用 sem_destroy() 函数销毁。成功返回 0,失败返回-1。
- sem_wait()、sem_trywait()、sem_post() 等函数与有名信号量的使用是一样的。
十、互斥锁与条件变量
10.1 互斥锁基本概念
互斥锁(mutex)又叫互斥量,从本质上说是一把锁,在访问共享资源之前对互斥锁进行上锁,在访问完成后释放互斥锁(解锁);对互斥锁进行上锁之后,任何其它试图再次对互斥锁进行加锁的线程都会被阻塞,直到当前线程释放互斥锁。如果释放互斥锁时有一个以上的线程阻塞,那么这些阻塞的线程会被唤醒,它们都会尝试对互斥锁进行加锁,当有一个线程成功对互斥锁上锁之后,其它线程就不能再次上锁了,只能再次陷入阻塞,等待下一次解锁。
10.2 互斥锁相关函数
10.2.1 互斥锁初始化
- 使用 PTHREAD_MUTEX_INITIALIZER 宏初始化互斥锁
# define PTHREAD_MUTEX_INITIALIZER \
{ { 0, 0, 0, 0, 0, __PTHREAD_SPINS, { 0, 0 } } }
- 使用 pthread_mutex_init()函数初始化互斥锁
使用 PTHREAD_MUTEX_INITIALIZER 宏只适用于在定义的时候就直接进行初始化,对于其它情况则不能使用这种方式
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
函数参数和返回值含义如下:
- mutex:参数 mutex 是一个 pthread_mutex_t 类型指针,指向需要进行初始化操作的互斥锁对象;
- attr:参数 attr 是一个 pthread_mutexattr_t 类型指针,指向一个 pthread_mutexattr_t 类型对象,该对象用于定义互斥锁的属性(在 12.2.6 小计中介绍),若将参数 attr 设置为 NULL,则表示将互斥锁的属性设置为默认值,在这种情况下其实就等价于 PTHREAD_MUTEX_INITIALIZER 这种方式初始化,而不同之处在于,使用宏不进行错误检查。
- 返回值:成功返回 0;失败将返回一个非 0 的错误码。
10.2.2 互斥锁加锁和解锁
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex); //加锁
int pthread_mutex_unlock(pthread_mutex_t *mutex); //解锁
调用 pthread_mutex_lock()函数对互斥锁进行上锁,如果互斥锁处于未锁定状态,则此次调用会上锁成功,函数调用将立马返回;如果互斥锁此时已经被其它线程锁定了,那么调用 pthread_mutex_lock()会一直阻塞,直到该互斥锁被解锁,到那时,调用将锁定互斥锁并返回。
调用 pthread_mutex_unlock()函数将已经处于锁定状态的互斥锁进行解锁
10.2.3 pthread_mutex_trylock()函数
当互斥锁已经被其它线程锁住时,调用 pthread_mutex_lock()函数会被阻塞,直到互斥锁解锁;如果线程不希望被阻塞,可以使用 pthread_mutex_trylock()函数;调用 pthread_mutex_trylock()函数尝试对互斥锁进行加锁,如果互斥锁处于未锁住状态,那么调用 pthread_mutex_trylock()将会锁住互斥锁并立马返回,如果互斥锁已经被其它线程锁住,调用 pthread_mutex_trylock()加锁失败,但不会阻塞,而是返回错误码 EBUSY。
#include <pthread.h>
int pthread_mutex_trylock(pthread_mutex_t *mutex);
10.2.4 销毁互斥锁
#include <pthread.h>
int pthread_mutex_destroy(pthread_mutex_t *mutex);
参数 mutex 指向目标互斥锁;同样在调用成功情况下返回 0,失败返回一个非 0 值的错误码。
10.3 条件变量基本概念
条件变量是线程可用的另一种同步机制。条件变量用于自动阻塞线程,知道某个特定事件发生或某个条件满足为止,通常情况下,条件变量是和互斥锁一起搭配使用的。使用条件变量主要包括两个动作:
- 一个线程等待某个条件满足而被阻塞;
- 另一个线程中,条件满足时发出“信号”
10.4 条件变量相关函数
10.4.1 条件变量初始化
- 使用宏定义初始化
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
- 使用函数 pthread_cond_init()
#include <pthread.h>
int pthread_cond_destroy(pthread_cond_t *cond);
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);
10.4.2 通知和等待条件变量
条件变量的主要操作便是发送信号(signal)和等待。发送信号操作即是通知一个或多个处于等待状态的线程,某个共享变量的状态已经改变,这些处于等待状态的线程收到通知之后便会被唤醒,唤醒之后再检查条件是否满足。等待操作是指在收到一个通知前一直处于阻塞状态。
函数 pthread_cond_signal()和 pthread_cond_broadcast()均可向指定的条件变量发送信号,通知一个或多个处于等待状态的线程。调用 pthread_cond_wait()函数是线程阻塞,直到收到条件变量的通知。
#include <pthread.h>
int pthread_cond_broadcast(pthread_cond_t *cond);
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
- 参数 cond 指向目标条件变量,向该条件变量发送信号。
- mutex:是一个 pthread_mutex_t 类型指针,指向一个互斥锁对象
- 返回值:调用成功返回 0;失败将返回一个非 0 值的错误码。
十二、高级I/O(Linux网络IO)
11.1 异步 I/O
在 I/O 多路复用中,进程通过系统调用 select()或 poll()来主动查询文件描述符上是否可以执行 I/O 操作。而在异步 I/O 中,当文件描述符上可以执行 I/O 操作时,进程可以请求内核为自己发送一个信号。之后进程就可以执行任何其它的任务直到文件描述符可以执行 I/O 操作为止,此时内核会发送信号给进程。所以要使用异步 I/O,还得结合前面所学习的信号相关的内容,所以异步 I/O 通常也称为信号驱动 I/O。
要使用异步 I/O,程序需要按照如下步骤来执行:
- 通过指定 O_NONBLOCK 标志使能非阻塞 I/O。
- 通过指定 O_ASYNC 标志使能异步 I/O。
- 设置异步 I/O 事件的接收进程。也就是当文件描述符上可执行 I/O 操作时会发送信号通知该进程,通常将调用进程设置为异步 I/O 事件的接收进程。
- 为内核发送的通知信号注册一个信号处理函数。默认情况下,异步 I/O 的通知信号是 SIGIO,所以内核会给进程发送信号 SIGIO。在 8.2 小节中简单地提到过该信号。
- 以上步骤完成之后,进程就可以执行其它任务了,当 I/O 操作就绪时,内核会向进程发送一个 SIGIO信号,当进程接收到信号时,会执行预先注册好的信号处理函数,我们就可以在信号处理函数中进行 I/O 操作。
11.2 非阻塞 I/O
关于“阻塞”一词前面已经给大家多次提到,阻塞其实就是进入了休眠状态,交出了 CPU 控制权。前面所学习过的函数,譬如 wait()、pause()、sleep()等函数都会进入阻塞,本小节来聊一聊关于阻塞式 I/O 与非阻塞式 I/O。
阻塞式 I/O 顾名思义就是对文件的 I/O 操作(读写操作)是阻塞式的,非阻塞式 I/O 同理就是对文件的I/O 操作是非阻塞的。这样说大家可能不太明白,这里举个例子,譬如对于某些文件类型(读管道文件、网络设备文件和字符设备文件),当对文件进行读操作时,如果数据未准备好、文件当前无数据可读,那么读操作可能会使调用者阻塞,直到有数据可读时才会被唤醒,这就是阻塞式 I/O 常见的一种表现;如果是非阻
塞式 I/O,即使没有数据可读,也不会被阻塞、而是会立马返回错误!
普通文件的读写操作是不会阻塞的,不管读写多少个字节数据,read()或 write()一定会在有限的时间内返回,所以普通文件一定是以非阻塞的方式进行 I/O 操作,这是普通文件本质上决定的;但是对于某些文件类型,譬如上面所介绍的管道文件、设备文件等,它们既可以使用阻塞式 I/O 操作,也可以使用非阻塞式 I/O
进行操作
11.3 多路复用 I/O
11.3.1 多路复用基本概念
I/O 多路复用(IO multiplexing)它通过一种机制,可以监视多个文件描述符,一旦某个文件描述符(也就是某个文件)可以执行 I/O 操作时,能够通知应用程序进行相应的读写操作。I/O 多路复用技术是为了解决:在并发式 I/O 场景中进程或线程阻塞到某个 I/O 系统调用而出现的技术,使进程不阻塞于某个特定的I/O 系统调用。
由此可知,I/O 多路复用一般用于并发式的非阻塞 I/O,也就是多路非阻塞 I/O,譬如程序中既要读取鼠标、又要读取键盘,多路读取。
我们可以采用两个功能几乎相同的系统调用来执行 I/O 多路复用操作,分别是系统调用 select()和 poll()。这两个函数基本是一样的,细节特征上存在些许差别!
I/O 多路复用存在一个非常明显的特征:外部阻塞式,内部监视多路 I/O。
11.3.2 select()函数介绍
系统调用 select()可用于执行 I/O 多路复用操作,调用 select()会一直阻塞,直到某一个或多个文件描述符成为就绪态(可以读或写)。
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
这些参数按照如下方式使用:
- readfds 是用来检测读是否就绪(是否可读)的文件描述符集合;
- writefds 是用来检测写是否就绪(是否可写)的文件描述符集合;
- exceptfds 是用来检测异常情况是否发生的文件描述符集合。
- 返回值:
- 返回-1 表示有错误发生,并且会设置 errno。可能的错误码包括 EBADF、EINTR、EINVAL、EINVAL以及 ENOMEM,EBADF 表示 readfds、writefds 或 exceptfds 中有一个文件描述符是非法的;EINTR表示该函数被信号处理函数中断了,其它错误大家可以自己去看,在 man 手册都有相信的记录。
- 返回 0 表示在任何文件描述符成为就绪态之前 select()调用已经超时,在这种情况下,readfds,writefds 以及 exceptfds 所指向的文件描述符集合都会被清空。
- 返回一个正整数表示有一个或多个文件描述符已达到就绪态。返回值表示处于就绪态的文件描述符的个数,在这种情况下,每个返回的文件描述符集合都需要检查,通过 FD_ISSET()宏进行检查,以此找出发生的 I/O 事件是什么。如果同一个文件描述符在 readfds,writefds 以及 exceptfds 中同时被指定,且它多于多个 I/O 事件都处于就绪态的话,那么就会被统计多次,换句话说,select()返回三个集合中被标记为就绪态的文件描述符的总数
11.3.3 poll()函数介绍
在 poll()函数中,则需要构造一个 struct pollfd 类型的数组,每个数组元素指定一个文件描述符以及我们对该文件描述符所关心的条件
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
函数参数含义如下:
- fds:指向一个 struct pollfd 类型的数组,数组中的每个元素都会指定一个文件描述符以及我们对该文件描述符所关心的条件,稍后介绍 struct pollfd 结构体类型。
- nfds:参数 nfds 指定了 fds 数组中的元素个数,数据类型 nfds_t 实际为无符号整形。
- timeout:该参数与 select()函数的 timeout 参数相似,用于决定 poll()函数的阻塞行为
- 返回值:与 select()函数的返回值是一样的,
11.4 存储映射 I/O
存储映射 I/O(memory-mapped I/O)是一种基于内存区域的高级 I/O 操作,它能将一个文件映射到进程地址空间中的一块内存区域中,当从这段内存中读数据时,就相当于读文件中的数据(对文件进行 read 操作),将数据写入这段内存时,则相当于将数据直接写入文件中(对文件进行 write 操作)。这样就可以在不使用基本 I/O 操作函数 read()和 write()的情况下执行 I/O 操作。
11.4.1 mmap()
为了实现存储映射 I/O 这一功能,我们需要告诉内核将一个给定的文件映射到进程地址空间中的一块内存区域中,这由系统调用 mmap()来实现。
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
函数参数和返回值含义如下:
- addr:参数 addr 用于指定映射到内存区域的起始地址。通常将其设置为 NULL,这表示由系统选择该映射区的起始地址,这是最常见的设置方式;如果参数 addr 不为 NULL,则表示由自己指定映射区的起始
地址,此函数的返回值是该映射区的起始地址。 - length:参数 length 指定映射长度,表示将文件中的多大部分映射到内存区域中,以字节为单位,譬如length=1024 * 4,表示将文件的 4K 字节大小映射到内存区域中。
- offset:文件映射的偏移量,通常将其设置为 0,表示从文件头部开始映射;所以参数 - offset 和参数 length就确定了文件的起始位置和长度,将文件的这部分映射到内存区域中
- fd:文件描述符,指定要映射到内存区域中的文件。
- prot:参数 prot 指定了映射区的保护要求,
- 返回值:成功情况下,函数的返回值便是映射区的起始地址;发生错误时,返回(void *)-1,通常使用MAP_FAILED 来表示,并且会设置 errno 来指示错误原因。
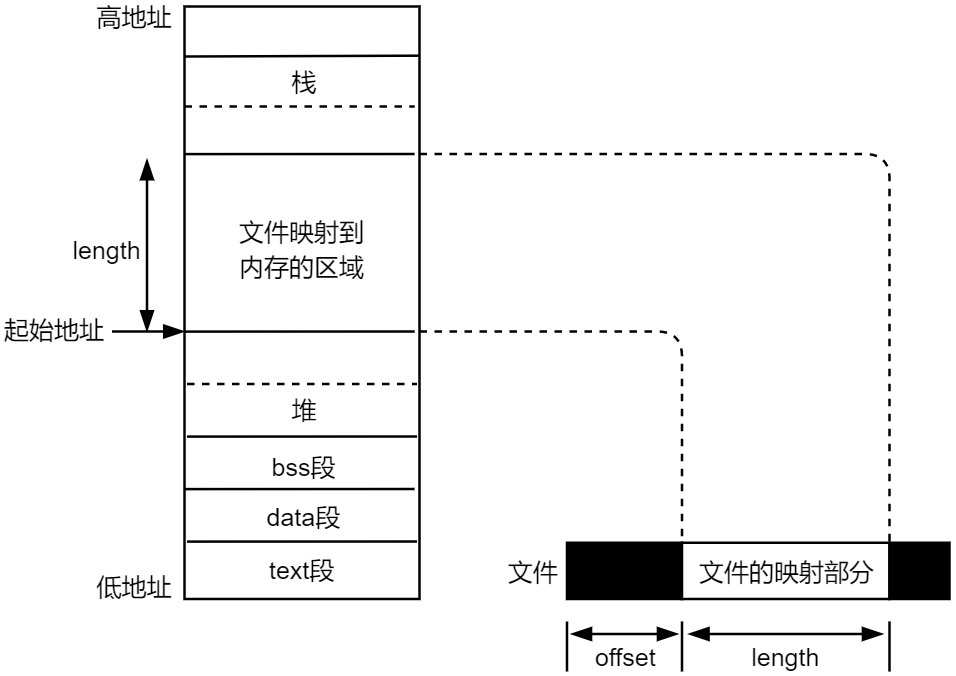
11.4.2 munmap()函数解除映射
#include <sys/mman.h>
int munmap(void *addr, size_t length);
11.4.3 mprotect()函数
使用系统调用 mprotect()可以更改一个现有映射区的保护要求
#include <sys/mman.h>
int mprotect(void *addr, size_t len, int prot);
- prot 的取值与 mmap()函数的 prot 参数的一样,mprotect()函数会将指定地址范围的保护要求更改为参数 prot 所指定的类型
- 参数 addr 指定该地址范围的起始地址,addr 的值必须是系统页大小的整数倍;
- len 指定该地址范围的大小。
- mprotect()函数调用成功返回 0;失败将返回-1,并且会设置 errno 来只是错误原因。
11.4.4 msync()函数
对于存储 I/O 来说亦是如此,写入到文件映射区中的数据也不会立马刷新至磁盘设备中,而是会在我们将数据写入到映射区之后的某个时刻将映射区中的数据写入磁盘中。所以会导致映射区中的内容与磁盘文件中的内容不同步。我们可以调用 msync()函数将映射区中的数据刷写、更新至磁盘文件中(同步操作),系统调用 msync()类似于 fsync()函数,不过 msync()作用于映射区
#include <sys/mman.h>
int msync(void *addr, size_t length, int flags);
- 参数 addr 和 length 指定了需同步的内存区域的起始地址和大小。
- 参数 flags 应指定为 MS_ASYNC 和 MS_SYNC 两个标志之一
- msync()函数在调用成功情况下返回 0;失败将返回-1、并设置 errno。
















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











