






随着transformer在cv领域大放异彩,原始的卷积网络到瓶颈了吗?
然后我们根据transformer的网络架构,是否能得到一些网络搭建的启发呢?

比如根据transformer去巧妙的调整网络架构,比如使用LN代替BN,减少relu函数,调整卷积和下
采样的数量和位置,调整block的分配,结果真的实现了在相同参数下,训练结果好于transformer
的一种新的网络模型。而且代码才200行就能实现目标网络的构建。
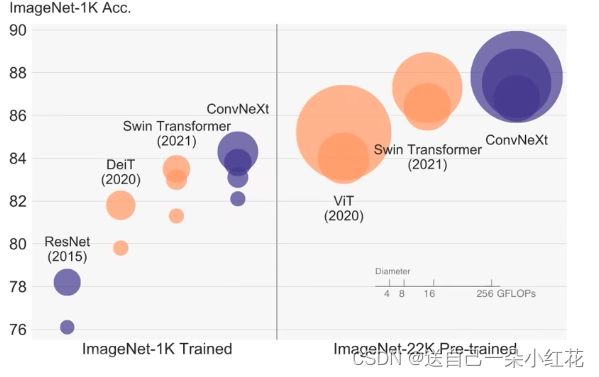
(1)首先作者以resnet-50模型为基础模型
(2)让resnet网络中堆叠的block比列,借鉴transformer模型中的比例,准确率得到提升
ResNetconv4_xstage3ResNet50stage1stage4(3, 4, 6, 3)1:1:2:1
Swin Transformer
Swin-T1:1:3:1
Swin-L1:1:9:1
Swin Transformerstage3ResNet50(3, 4, 6, 3)(3, 3, 9, 3)Swin-T78.8%79.4%
(3)在之前的卷积神经网络中,一般最初的下采样模块一般都是通过一个卷积核大小为步距为2的卷积层+步距为2的最大池化下采样共同组成,高和宽都下采样4倍。 但在模型中一般都是通过一个卷积核非常大且相邻窗口之间没有重叠的(即等于)卷积层进行下采样。 比如在中采用的是一个卷积核大小为步距为4的卷积层构成,同样是下采样4倍。
(4)借鉴了组卷积
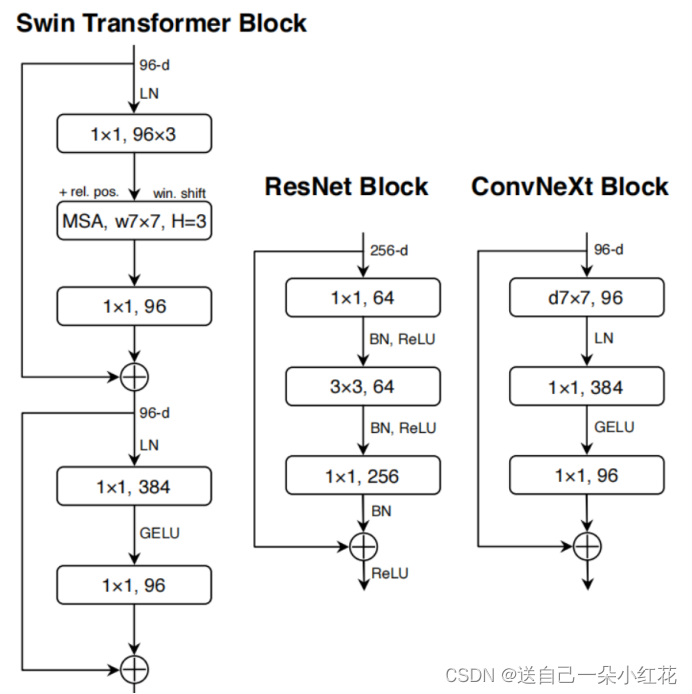
(5)两头粗中间细的瓶颈结构(resnet),转成两头细中间粗的。对较大模型的accy是比较明显的
(6)先通过DW卷积(有点类似attention模块),再通过普通卷积,即将dw模块上移,因为在transformer模块当中,attention模块在mlp模块前面,结果效果又提升了
(7)改变卷积核的内核大小,3x3-->7x7,作者试过多种,7x7最好,而神奇的事情,它竟然和swim中的窗口大小是一样的
(8)采用更少的激活函数,原先的卷积网络中我们习惯在卷积后面加上relu,但是transformer中很少,结果效果提升了,当然把relu换成了transformer 中的gelu激活,但是效果没有更明显。
(9)使用更少的norm操作,提升了1个点
(10)BN->LN又提升了一个点,都是借鉴transformer中的模型架构
(11)在transformer中,它是通过patch merging中进行下采样的,所以作者单独使用了一个下采样,而不是在block中卷积stride=2下采样
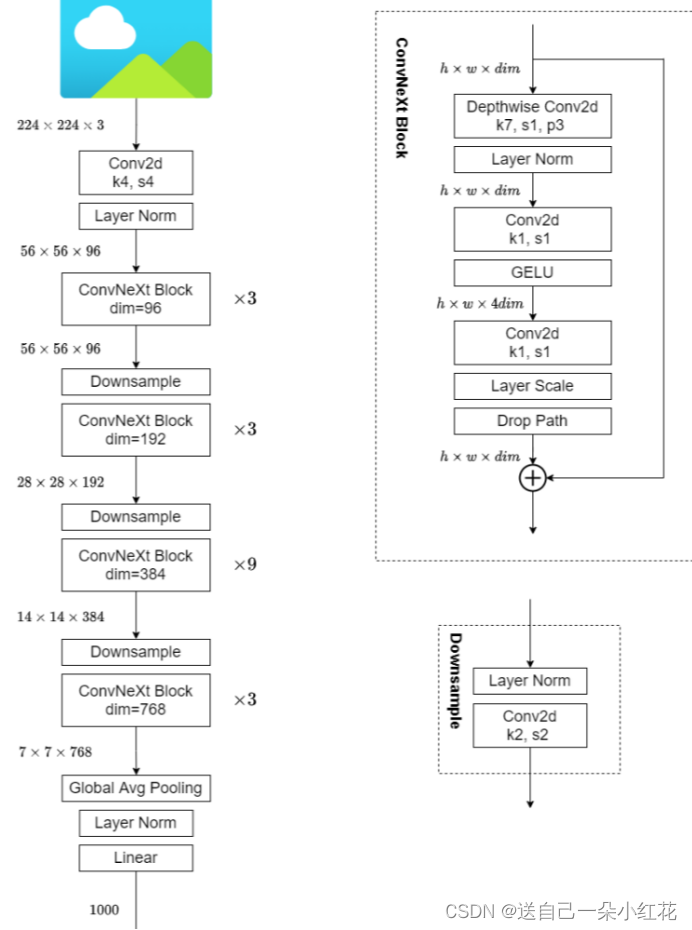
不同的convnet版本:
ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
Convnet网络block与transformer与resnet对比,或者说是改进借鉴对比
Convnet网络模型。















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









