






正向最大匹配
其主要是目的是将一句话分成进行词语的划分,相当于看看这句话由哪些词语组成,最完美的解决方案是,我会准备一个词库,然后我输入进去一句话,刚好我用我词库里面的词语把这句话分成一个一个词,一个字不剩(也不一定是词语,可能是介词,可能是代词)。我们的正向最大匹配就是为了达到这个目的。
方法一:
- 找出词表中最长的那个词语的长度
- 从我们输入进去的话(也就是字符串)中,从头开始,用最大的那个长度去截取对应长度的字符串,看看取到的这个字符串在不在我们的词库中
- 如果取到的字符串在词库中,那么从这个字符串末尾“切一刀”(相当于找到了句子中的一个词),然后从这一刀后面再取最大词语长度的字符串,再来看这个字符串在不在词库中
- 如果不在词库中,就缩短一个单位我们截取的长度,再从之前的位置开始截取字符串
- 如果这次找到了,那么从此处砍一刀,接着后面又从最大的长度开始截取
- 如果还没找到,再缩短一个单位再找,以此往复。
- 如果已经缩短到只有一个字的长度了,那么就把这个字当作一个没有在词库中出现的词,也算是词,在其后切一刀。然后在其后同样取最大长度,循环上面的步骤,一直到句子的最后。
其实现步骤在forward_segmentation_method1.py中
def main
def main(cut_method, input_path, output_path):
word_dict, max_word_length = load_word_dict("dict.txt")
其main函数中的cut_method是用来截取或者说用来切割句子的函数,input_path是我们存放句子的文档的地址,output_path是保存的每一个句子被词库截取后“一块一块”的样子的文件路径(或者叫文件名)
load_word_dict是用来加载我们的词库的函数
def load_word_dict
#加载词典
def load_word_dict(path):
max_word_length = 0
word_dict = {} #用set也是可以的。用list会很慢
with open(path, encoding="utf8") as f:
for line in f:
word = line.split()[0]
word_dict[word] = 0
max_word_length = max(max_word_length, len(word))
return word_dict, max_word_length
其中path就是我们存放词库的文档地址:“dict.txt”,这个文档的片段为:
AT&T 3 nz
B超 3 n
c# 3 nz
C# 3 nz
c++ 3 nz
C++ 3 nz
T恤 4 n
A座 3 n
A股 3 n
A型 3 n
A轮 3 n
AA制 3 n
AB型 3 n
在方法一中,我们只会用到第一列的内容,也就是词语本身
先用open打开path中的文档
然后这个f有一点不一样,因为f相当于是现在是一个实例化的对象,我们之前遇到的f后面都会紧跟f.readline.f.readlines,f.read等等,但是这里直接接了一个循环,其是利用for循环中会自动取索引的原理,用这个索引来调取f中的值,可以理解为每一次循环都会调取f.readline()这个函数,读取f中的每一行。
对于每一行我们只需要第一个字符串的部分,所以用str.split(),()里面填写你这个字符串用字符串里面那个内容来进行分割,如果空的,那就是换行符或者空格,然后分隔开以后我们选取0号元素。
之后利用字典来存放我们的提取出来的字符,后面给它们统一配一个value都是0,主要是因为字典运算速度更快
然后比较字符的长度和我们初始化的最大字符的大小,每一次循环最大字符的大小都要决定是否更新
最后返回我们的字符字典和最大字符长度,一次循环以后我们主要参数的取值为:
word=AT&T
word_dict={'AT&T': 0}
max_word_length=4
def main
writer = open(output_path, "w", encoding="utf8")
start_time = time.time()
打开我们准备存放分割后的句子的文件,并且记录开始的时间
with open(input_path, encoding="utf8") as f:
for line in f:
words = cut_method(line.strip(), word_dict, max_word_length)
writer.write(" / ".join(words) + "\n")
打开我们保存句子的文件,利用循环把每一句分别调取出来
利用cut_method来切割我们选取的一句话,输入进去的参数我们删除这个字符串前后的空格或者特殊字符,词库字典,最大词语长度
这里删除的是在字符串的最后的换行符
def cut_method
def cut_method1(string, word_dict, max_len):
words = []
while string != '':
lens = min(max_len, len(string))
word = string[:lens]
while word not in word_dict:
if len(word) == 1:
break
word = word[:len(word) - 1]
words.append(word)
string = string[len(word):]
return words
其实它的底层逻辑就是我们最开始口述的逻辑,我们一开始输入进去的是一个长的字符串,只要这个字符串没有被切割完,也就是它不是空的,那么循环不会结束
只要我们需要截取的字符串的长度比最大的词语长度大,那么我们用来截取的最大长度就不会变
先截取输入进来的字符串的头0到lens-1个字符得到word
如果这word不在词库里面,首先判断截取下来的word是不是已经到头了,也就是没办法再缩了,已经是最前面的字符了,直接退出本次小循环
如果这个word不在词库里面且长度不是1,那么word去掉最后一个字符,然后再回到里层的while,再判断此时的word在不在词库里面,以此类推,直到word在这个词库里面了,或者word的长度为1了,那就退出循环,得到了一个分词word
把这个分词字符串装到words列表里面存好
然后string直接去掉word的部分,形成一个新的string,之后去到最外面的循环继续判断
如果一来,利用两个循环,最后在words中就会存放上这个句子中被切成一块一块的样子。
def main
with open(input_path, encoding="utf8") as f:
for line in f:
words = cut_method(line.strip(), word_dict, max_word_length)
writer.write(" / ".join(words) + "\n")
每次循环利用cut_method1得到的words就是一个列表中装了很多小字符串了。
随笔7:open这个函数
my_file = open(file, mode, buffering, encoding, errors, newline, closefd, opener)
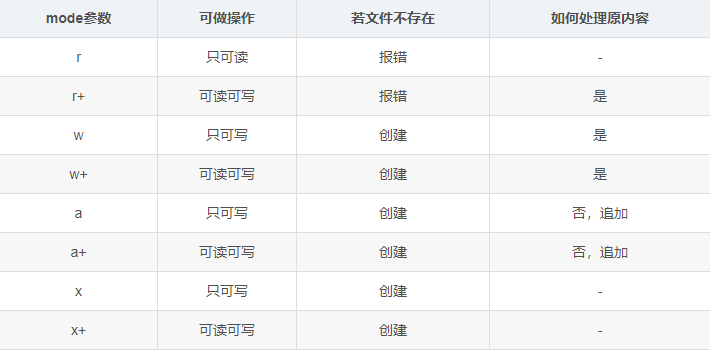
其中常用的参数设置:
- file:我们想要打开的文件路径,这个文件能不能存在取决你你后面mode的选择
- mode:这是最重要的一个参数,主要的功能可以分为4个:r,w,a,x,分别表示读,写,追加,创建文件。其中r只能对文件进行读取,如果文件不存在会报错。w只能进行写入操作,不可读取,如果指定文件不存在,那么就创建一个指定文件名的文件。a也只能写入,不可读取,若指定文件存在,则可以直接写入,如果不存在,创建该文件名的文件,然后再写入,其与w的区别在于,w在写入前会把指定文件中的内容清空以后再写,a则是在原来内容的基础上接着写入。x是创建一个文件,然后只能对该文件进行写入操作,并且创建的文件名必须不存在,否则会报错。还有一些四种基本模式的扩展:
 -
- - encoding:打开文件所使用的编码,可选参数,常用的为:utf-8、ascii、gbk。默认是gbk,我们更常用的utf-8,这是国际编码规则,如果打开的文件中文占主体,还是建议改为utf-8。
这里的words在完成以后用了一个a.join(b)的语法,将b中的各个元素(b中的元素可以是字符串,可以是字典,元组,序列)用a来连起来,其中a是一个字符,双引号里面可以为空,所以它的流程就是把word中各个字符串都用斜杠连接起来,并且在最后再加一个换行符,最后将这个大的字符串写到writer中。
writer.close()
print("耗时:", time.time() - start_time)
return
当循环结束以后,停止了writer的写操作,打印出来耗时,最后啥也不返回。这就是正向最大匹配的实现方法1,我们以一句话为例:
主 / 力 / 合 / 约 / 突 / 破 / 2 / 1 / 0 / 0 / 0 / 元 / / / 吨 / 重 / 要 / 关 / 口
可以看到由于我们的词库里面的词语很少,所以基本每一个字都被给了一刀。
方法二:记录前缀字典
方法一中有一个致命的问题,那就是时间问题,因为方法1中得到一个分词可能会出现多个回退的步骤,尤其如果这个分词没在词库里面,那就肯定要分都最后一个字符,非常费时。所以这里更新了方法,在词库中每一个词后面都匹配了一个它的前缀描述
方法一之所以要回退,是因为一开始找多了,所以方法二舍弃了最大词语长度的设定,就从句子的开头一个单位开始找。
- 首先我们会对词库进行处理,这里我不光会有会有原来的词语,还会有这些词语的前缀,也就是这些词语的前1个字,前2两个字,一直到比原词少一个单位,这些词称作前缀词。我们将原词的value设置为1,所有的前缀词的value设置为0.
- 我们首先就从句子的开头开始一个单位的找,如果找的这个单位在不在词库里面,如果不在,好家伙,省事儿多了,你连词缀都不是,那么直接从你后面切一刀,然后继续从这一刀后面继续从一个单位开始找
- 如果一开始的单位就在词库里面并且其value为1,表示它就是原词,那么也在其后切一刀,然后继续从这一刀后面继续从一个单位开始找
- 如果一开始的单位在词库里面,并且该词语的value为0,也就是前缀词,那么扩展一个单位,继续看看截取的部分在词库中属性,如果还是前缀词,继续扩展单位,一直到截取的部分在词库中value为1,从后面切一刀,然后从后面重复一个单位开始找的步骤。
其代码实现为:
def load_prefix_word_dict(path):
prefix_dict = {}
with open(path, encoding="utf8") as f:
for line in f:
word = line.split()[0]
for i in range(1, len(word)):
if word[:i] not in prefix_dict: #不能用前缀覆盖词
prefix_dict[word[:i]] = 0 #前缀
prefix_dict[word] = 1 #词
return prefix_dict
首先就是生成字典的问题,这里path也是方法一的词库,我们需要把里面词语以及其前缀词并且二搭配其value组成一个字典。
首先创建一个大字典存放我们的词语
然后老方法,读取一行的内容,然后去掉前后的空格或者特殊字符,这里要注意,**这里的特殊字符是换行符,不是空格,**以后取第0位,也就是词语字符本身
然后开始创建这个词语的前缀词并为其匹配value0,那么一个词语的前缀词的个数一定是原词字符串长度减1,所以前缀词的长度就是从1到原词的长度减1,首先取1即最短的前缀词。
然后进行一步非常重要的判断,因为有的原词的前缀词恰好就是另一个原词,比如”王者荣耀“中的”王者“就有可能是另一个原词,所以这种时候,这样的前缀词不能被赋予0的value,要不然同样的原词就检测不出来了。那么如果这个原词在前缀词检测之后呢?没关系,因为这个原词虽然现在被赋值成了0,但是后面检测这个原词的时候就还会改成1.
如果原词的一部分不是另一个原词,那么就把这部分当作新的key,然后赋值value赋值为0,一直这样处理到本次原词的所有前缀词。
在结束对本次原词的前缀词value赋值以后,再记录这个原词,令其value为1(就是在这一步进行的更正)
以此循环完path中的所有词语,组成一个较方法一更大的字典。
def main
def main(cut_method, input_path, output_path):
word_dict = load_prefix_word_dict("dict.txt")
writer = open(output_path, "w", encoding="utf8")
start_time = time.time()
with open(input_path, encoding="utf8") as f:
for line in f:
words = cut_method(line.strip(), word_dict)
writer.write(" / ".join(words) + "\n")
writer.close()
print("耗时:", time.time() - start_time)
return
main函数和方法一基本相同,只不过在调用切割函数的时候参数不同而已,所以只需要看看新的切割函数的原理
def cut_method2:
def cut_method2(string, prefix_dict):
if string == "":
return []
words = [] # 准备用于放入切好的词
start_index, end_index = 0, 1 #记录窗口的起始位置
window = string[start_index:end_index] #从第一个字开始
find_word = window # 将第一个字先当做默认词
输入进来的srting还是经过处理后的一句话的字符串,prefix_dict就是我们的词库字典。
这里还设置了我们用来截取的窗口的位置,start_index和end_index 用来控制窗口的大小和位置,find_word 相当于对一句话处理的初始位置,所以find_word 一开始就是一句话的第一个字符。
while start_index < len(string):
#窗口没有在词典里出现
if window not in prefix_dict or end_index > len(string):
words.append(find_word) #记录找到的词
start_index += len(find_word) #更新起点的位置
end_index = start_index + 1
window = string[start_index:end_index] #从新的位置开始一个字一个字向后找
find_word = window
#窗口是一个词
elif prefix_dict[window] == 1:
find_word = window #查找到了一个词,还要在看有没有比他更长的词
end_index += 1
window = string[start_index:end_index]
#窗口是一个前缀
elif prefix_dict[window] == 0:
end_index += 1
window = string[start_index:end_index]
开始对这句话进行分割
我们从最开始的流程来分析,它主要分为三种情况:
①window里面的内容不在词库里面,那么直接把find_word添加进words(or后面另一种情况是句子截取到最后停止解决的操作,最后来说),并且在将window的位置移到该词组后面,大小重新回到1
②window里面的内容是原词,那么将这个内容保存进find_word中,然后window向后移一格
③window里面的内容是前缀词,那么说明此时window内的内容可能小了,就不保存此时的find_word,只是将window后移一格
这里需要说明一下三个条件什么时候会触发
条件一:通过观察整体程序可以看出来,find_word是上一轮window里面的内容,所以触发条件一的第一种情况就是此时window里面的内容不是词库里面的,这个时候就要把find_word添加进words中,说明这个时候找到词组了。那么其内容不在词库中的情况有以下几种:
- (1)window里面的内容没有原词,没有前缀词,表示此时的内容就是独立的一个字,只能是一个字!将这个字添加进words中并且window往后移的同时变成1单位长度。
- (2)window里面是”前缀词+一个单位“,此时我们可以发现依然会添加进find_word,而此时的find_word里面保存的,由于find_word期间一直没动过,所以其是前一个添加jinwords步骤后紧跟的第一个字,也就是前缀词的第一个字符,也就是如果前缀词与原词脱节了,那么就会将前缀词拆成一个字一个字进行保存。
- (3)window里面是”原词+一个单位“,这个时候由于第二种情况,find_word就是原词,这个时候直接添加进去就可以了
需要说明的是,在第二种情况也就是找到原词以后,为什么window还要再后移一格,不仅是为了触发第一个条件,更是为了处理类似于:001001这种情况,我们找到第一个1的时候还要往后看,发现是0,不触发第一种情况会继续延申window,直到检测出第二个1,然后如果后面没有0了,就会把001001添加进word里面,而不会添加001。
那么触发if还有一个条件,就是or后面的 end_index > len(string)
与字符串的长度做比较说明此时的window已经很靠后了,它是为了解决句子特殊结尾的问题。
如果句子最后是由词库外的一个字结尾,那么直接触发上面的(1),之后新更新的window里卖是空的,所以find_word也是空的,但是需要注意的是,例如一句话一共六个字符,假如此时的start_index=5,end_index就是6,此时window里面就是最后一个字,如果其是词库外的字,那么直接添加进words,之后start_index=6,直接结束循环,所以这情况属于比较正常的情况。
第二种情况,句子以前缀词结尾,这样的话是不会触发window not in prefix_dict的,但是前缀词的每一个字都需要分割,由于前缀词会一直触发第二个elif,所以当end_index=7的时候,会进入到if中,将前缀词的第一个字装进words中,然后第二个字继续触发第二个elif,又直到end_index=7。当start_index=6的时候,结束循环。
第三种情况,句子以原词结尾,此时会触发第一个elif,find_word保存的就是原词并且end_index应该是6,但是由于字符串里面没有下标6,所以window里面还是这个原词,只不过end_index变大了,之后再触发一次第一个elif,find_word虽又被赋值一次,但是内容不变,这个时候end_index就是7,触发if,将原词装填以后start_index=6,结束循环。
#最后找到的window如果不在词典里,把单独的字加入切词结果
if prefix_dict.get(window) != 1:
words += list(window)
else:
words.append(window)
return words
这里if我觉得是画蛇添足,因为如果以一个词库外的字结尾,我们已经分析过逻辑了,已经会把最后一个字添加进去,这里之所以没出错是因为此时的window里面是空的。
最后一个测试的环节:
string = "王羲之草书《平安帖》共有九行"
prefix_dict = load_prefix_word_dict("dict.txt")
print(cut_method2(string, prefix_dict))
print(json.dumps(prefix_dict, ensure_ascii=False, indent=2))
json.dumps表示将prefix_dict这个字典文件转化为json文件,ensure_ascii默认是True,表示结果用阿斯克码显示,必须改为Fasle才能显示中文,indent表示缩进,如果你不缩进,它现实的文本就是全部排成一行的。
方法三:记录前后缀字典
其是改变了方法二的两个弊端,一个是我们刚才说的如果一个短词刚好是长词的前缀,那么短词是不会被记录进去的,这是遗漏的弊端。另一个是我们在找到一个词以后,都会往后再移一格,才能判断是否继续扩展window,这是耗时的弊端。
所以我们决定继续修改我们的词库。我们同样将词库中的key分成前缀词和原词,不同是后面value不再仅仅是0和1.我们规定:
- 如果value为0,那么证明这是一个前缀词
- 如果value为1,那么证明这也是原词,并且该原词不是另一个原词的前缀,可以说其是相对最大的原词。这个时候就不需要再往后移一格了,直接重新定义window就可以了。
- 如果value为2,那么证明这是一个原词,但是这个原词是一个另一个原词的一部分,也就是说当查找到这个原词的时候,还需要继续往后,因为还有一个”更大“的原词。**这里的一部分只能是作为前缀,无法作为中间而存在。例如中国人民大学,在词库里面有人民和中国人民大学,那么这个时候人民两个字依然只会被赋值为1而不会是2。所以短词作为长词的一部分只能是前缀、**实例:
#txt内容
人民
中国人民大学
#字典结果
{'人': 0, '人民': 1, '中': 0, '中国': 0, '中国人': 0, '中国人民': 0, '中国人民大': 0, '中国人民大学': 1}
其代码实现为:
首先是创建词库字典的过程
#加载词前后缀词典
#值为0代表是前缀
#值为1代表是一个词且这个词向后没有更长的词
#值为2代表是一个词,但是有比他更长的词
def load_prefix_word_dict(path):
prefix_dict = {}
with open(path, encoding="utf8") as f:
for line in f:
word = line.split()[0]
for i in range(1, len(word)):
if word[:i] not in prefix_dict: #不能用前缀覆盖词
prefix_dict[word[:i]] = 0 #前缀
if prefix_dict[word[:i]] == 1:
prefix_dict[word[:i]] = 2
prefix_dict[word] = 1 #词
return prefix_dict
直接从内层for开始说明,其是为了创建一个原词以及其前缀的value,i的取值范围了1到word长度减1
首先判断以解决短词不能被长词前缀覆盖的风险,将这个词的前i-1个部分进行value为0的赋值,也就是说如果满足第一个if,就不能满足第二个if,循环完毕以后相当于目前就是在做方法二的事,最后将该原词的value赋值为1
然后开始处理第二个词,如果第二个词的前i-1个部分不在字典里面,最好办,那就直接赋值0,如果前i-1个部分在字典里面,那么有两种情况,这部分是别的词的前缀,或者这部分就是别的原词,所以进行判断,如果其value为1,表示其为后者,那么将其value从1改为2.表示探测到这原词以后还需要往后继续探测,因为还有一个更大的原词。直到最后把将这个长词的value赋值为1,暂时表示其后没有更长的词了。
之后循环来新添加前缀或者修改原词的value
那么,长词和短词输入的顺序是否会影响最终的结果呢?我们假设短词先输入进去,那么就如同方法二的正常步骤,然后长词输入进去,这个时候就会由于二者拥有部分相同的前缀词,这部分前缀词的value不会改变,当检索到短词的时候,修改这个短词的value从1到2,然后继续长词的前缀赋值,一直到长词被赋值为1.
如果长词首先被赋值,那么当短词进来的时候,依然相同的前缀词保持value不变(也就是第一个if不会触发),然后当检测到短词本词的时候,你会发现,如果短词后长词前的步骤输入进去,短词两个if都不会触发,那么直接就会给短词赋值为1.如果后面没有第二个长词以这个短词为前缀,那么这个短词的value不会再被修改。
#txt内容
中国
中国人民大学
#字典结果
{'中': 0, '中国': 2, '中国人': 0, '中国人民': 0, '中国人民大': 0, '中国人民大学': 1}
#txt内容
中国人民大学
中国
#字典结果
{'中': 0, '中国': 1, '中国人': 0, '中国人民': 0, '中国人民大': 0, '中国人民大学': 1}
然后是我们的切割部分:
def cut_method3(string, prefix_dict):
if string == "":
return []
words = [] # 准备用于放入切好的词
start_index, end_index = 0, 1 #记录窗口的起始位置
window = string[start_index:end_index] #从第一个字开始
find_word = window # 将第一个字先当做默认词
与方法二中一样的准备工作
while start_index < len(string):
#窗口没有在词典里出现
if window not in prefix_dict or end_index > len(string):
words.append(find_word) #记录找到的词
start_index += len(find_word) #更新起点的位置
end_index = start_index + 1
window = string[start_index:end_index] #从新的位置开始一个字一个字向后找
find_word = window
#窗口是一个词,且不是任何词的前缀
elif prefix_dict[window] == 1:
words.append(window) # 记录找到的词
start_index += len(window) # 更新起点的位置
end_index = start_index + 1
window = string[start_index:end_index] # 从新的位置开始一个字一个字向后找
find_word = window
#窗口是一个词,但是有包含它的词,所以要再往后看
elif prefix_dict[window] == 2:
find_word = window #查找到了一个词,还要在看有没有比他更长的词
end_index += 1
window = string[start_index:end_index]
#窗口是一个前缀
elif prefix_dict[window] == 0:
end_index += 1
window = string[start_index:end_index]
if和方法二完全一样
第一个elif表示如果window里面的内容value为1,不用往后找了,直接把里面的内容填充,然后window和find_word全部初始化
第二个elif表示为2,也就是说这个原词后面还有长词,它是原词,但是同时也是别人的前缀。这里对find_word进行赋值并不是没有意义的,虽然如果window里面的内容判定为2,那么肯定会继续后移,下面的window反正也不外乎还是012,但是检测到2的时候,会直接把window里面的内容填充,之后find_word和window都会初始化,所以这个时候对find_word赋值完全没必要。但是,如果这个短词本身就是独立的,与对应的长词隔得老远,那么往后移会直接触发if从而将find_word的内容填充。
也就是说,短词只有和长词分开的时候才能被填充,如果其作为长词的一部分,短词是填充不了的。
第三个elif就是单纯的前缀后移一格的操作
当我们规定输入进入的str为:“中国必将屹立世界之巅,也必然屹立于世界之巅”。
字典为:
中国
必将
屹立
屹立于
世界
世界之巅
['中国', '必将', '屹立', '世界之巅', ',', '也', '必', '然', '屹立于', '世界之巅']
耗时: 2.109302520751953
可以看到,屹立属于屹立于的前缀,但是由于二者相隔较远,所以屹立被检测出来。但是世界是世界之巅的前缀,由于其属于世界之巅的一部分,所以世界并没有被检测出来。
反向最大匹配
也就是我们对一句话从屁股开始,利用window来进行词组的切割,和正向最大匹配不好说孰优孰劣。
双向最大匹配
对一句话同时进行反向最大匹配和正向最大匹配,之后比较二者的切分结果,选择优者的结果进行保存
其判优标准有三种:
- 单字词:这里的单字词并不是指这个词不在词库里面,而是词库里面本来就有这些单字词。单字词少,表明这种切分方式把句子中各个部分进行了更多的整合,因为我们的句子意思更多是以二字以上词语的结构进行表达,单字表达含义不是非常完整,所以一般来说单字词越少是效果更好的
- 非字典词:这就是游离于词库之外的单字,数字,字母,符号。自然越少越好。
- 词总量:一定程度上和单字词呈正比例关系,自然词总量越少,一般效果更好。
jieba中文分词
其对一个句子的切分的方式非常简单粗暴,叫做全切分。
jieba会有一个很大很大的词库,其会利用自己的词库把这句话所有可能切分的方式全部切出来。由于jieba自己的词库对每一个词组都统计了该词组的词频,然后通过计算某一种切割方式切割出来的各个分词的词频之和,选择词频最高的一种切割方式的结果进行返回。(这个词频是jieba自己统计的)。
基于机器学习的中文分词
分词的意义其实就是判断在某个字后面该不该切一刀,如果我们把每个字的标签根据是否在句子中切一刀位判据,如果不切设置为0,如果要切设置为1,这样的话我们就得到了一个与句子等长且顺序相同的标签(也开始说是一种序列),这就是后面要学习的序列标注任务。那么我们每一个字的预测值可以是两个,0和1或者说就一个0到1的数,大于0.5判定为1,反之为0.
随笔8:交叉熵只接收二维的输入,注意进行reshape
segmentation_based_on_rnn.py
首先是main.py
def main():
epoch_num = 10 #训练轮数
batch_size = 20 #每次训练样本个数
char_dim = 50 #每个字的维度
hidden_size = 100 #隐含层维度
num_rnn_layers = 3 #rnn层数
max_length = 20 #样本最大长度
learning_rate = 1e-3 #学习率
vocab_path = "chars.txt" #字表文件路径
corpus_path = "corpus.txt" #语料文件路径
vocab = build_vocab(vocab_path) #建立字表
我们目的是对输入进来的每一个字进行预测,那么我们自然就要先对每一个字进行编码,就像我们第二节课那样,编码之前我们要先对每一个字进行下标的映射,vocab就是做这件事的。
def build_vocab(vocab_path):
vocab = {}
with open(vocab_path, "r", encoding="utf8") as f:
for index, line in enumerate(f):
char = line.strip()
vocab[char] = index + 1 #每个字对应一个序号
vocab['unk'] = len(vocab) + 1
return vocab
我们输入的vocab_path = "chars.txt"的部分内容如下:
〔
〕
・
一
丁
七
万
丈
三
利用循环挨个读取f,所以line就是一行的一个字符加后面跟了一个换行符。所以使用line.strip()去掉了后面的换行符只剩下前面单一的字符。然后将字符作为key,该字符在文件中的排序(从1开始)作为对应的value,也就是之后要去embedding里面提取的下标。
在运行完循环以后,在最后加上一个独立于子表的字符“unk”,其value为整个子表长度加1
data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集
创建一句话读取的信息的对象。
def build_dataset
#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):
dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__
data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torch
return data_loader
这里的build_dataset实际融合了两个操作,首先是Dataset(自己创建的),其表示读取所有句子的操作并根据索引返回一个句子的训练数据和对应的标签。然后利用自带的DataLoader完成读取一个batch的操作,返回一个batch的训练数据和对应的标签。
class Dataset:
class Dataset:
def __init__(self, corpus_path, vocab, max_length):
self.vocab = vocab
self.corpus_path = corpus_path
self.max_length = max_length
self.load()
这里的Dataset并不继承nn.Module,因为它里面并不创建训练参数,只是做一个数据的读取作用,所以自然也就不需要forward方法。其中corpus_path就是"corpus.txt" 表示存放训练集的文件,也就是语料的地址,这里的训练集文件并不是真正符合训练标准的文件,而仅仅是很多句话,我们需要对每一句自己来定义它的01标签。vocab是我们字符的映射字典,max_length=20,表示我们需要切分的句子的而最大长度。
后面的self.load()表示运行该类里面的load()方法
一定要时刻记住我们要返回的是一个句子的训练内容(由于embedding编码属于网络训练的参数,其处于网络结构里面,所以我们输入到网络里面的其实是一个句子中的每一个字符对应字库中映射的数字,也就是之后用再embedding里面的下标),和这个句子的标签,也就是每个字的01标签。但是Dataset自己里面会创建所有句子的训练数据和标签,只不过我们提取的时候是一个一个提取的。
这里有一点区别的是,我们之前在YOLOV3或者说DETR里面的类似Dataset类,都是输入一个索引,处理对应一张图片形成这张图片的训练数据已经标签,这里有一点不同,它是直接一口气先处理了所有的句子,然后得到训练集里面所有的训练数据和标签,然后再利用getitem来直接取一句话的训练数据和标签。
class Dataset:
def load(self): 就是处理所有训练集的方法
def load(self):
self.data = []
with open(self.corpus_path, encoding="utf8") as f:
for line in f:
sequence = sentence_to_sequence(line, self.vocab)
直接打开我们的语料文件,然后循环取出每一个句子,但是后面有一个换行符。之后利用sentence_to_sequence将句子中的每一个字都按顺序进行下标的映射。
def sentence_to_sequence
def sentence_to_sequence(sentence, vocab):
sequence = [vocab.get(char, vocab['unk']) for char in sentence]
return sequence
先用循环读取句子中的每一个字符,然后利用dict.get的方式,读取对应key为该字符的value,如果字典里面没有这个字符,就用’unk’对应的value来代替。(这里并没有处理最后一个换行符,应该是疏漏)。最后返回这个列表,就是一句话中的每个字符对应的字库中的下标。也可以理解成将字符转成了固定的数字。
class Dataset:
def load(self):
label = sequence_to_label(line)
利用提提取出来的一句话,形成这句话的切点标签。
def sequence_to_label
#基于结巴生成分级结果的标注
def sequence_to_label(sentence):
words = jieba.lcut(sentence)
label = [0] * len(sentence)
pointer = 0
for word in words:
pointer += len(word)
label[pointer - 1] = 1
return label
由于并没有直接准备句子的切点标签,所以这里使用了jieba来对句子进行切分,jieba.lcut(sentence)返回就是一个列表
['主力', '合约', '突破', '21000', '元', '/', '吨', '重要', '关口', '\n']
将每一个词组都按顺序排列,注意后面还跟了一个换行符。之后我们就根据分词的结果,在对应的字上面赋予其切点标签,例如主这个字就是0,力这个字就是1,合是0,约是1…
首先创建一个和句子等长的全是0的列表,之后只需要将切点对应的换成1就可以了
pointer作为一个切点的下标,初始化为0
遍历上面列表中的字符串,pointer加上第一个字符串的长度也就是2,所以第一个切点就是在下标1。这个时候的pointer已经被更新成2了,方便切换到下一个切点。
所以在label为pointer-1的位置修改为1
循环利用pointer每次加小字符串长度的方式进行更新,并且利用每次的pointer来确定切点,结束以后的label就是一句话对应的切点标签。
class Dataset:
def load
sequence, label = self.padding(sequence, label)
当我们获得了所有训练集输入到网络的数据和各自的标签以后。我们为了保证输入网络的每个句子的统一性,需要对所有的句子进行长度的统一。padding就是做这个的。
class Dataset:
def padding:
#将文本截断或补齐到固定长度
def padding(self, sequence, label):
sequence = sequence[:self.max_length]
sequence += [0] * (self.max_length - len(sequence))
label = label[:self.max_length]
label += [-100] * (self.max_length - len(label))
return sequence, label
其中sequence是一句话的各个字符的下标映射,label是各个字符的切点标签。二者的shape均为[len(sequence)]。
首先对超出最大长度的句子的下标映射进行截断,我后面都不要了,不大于最大长度的句子不会改变。
然后创建一个最大长度与该句子长度之差的全0列表,之后把这个全9列表加在原来的句子字符的下标映射列表后面。先当与多余的部分对应的下标映射是0。
同样对超出最大长度的句子的切点标签进行截断
同样在原句的标签和后面补齐padding的标签,全是-100,这个-100是人为任意设置的。最后返回padding后的下标映射和标签。
class Dataset:
def load
sequence = torch.LongTensor(sequence)
label = torch.LongTensor(label)
self.data.append([sequence, label])
#使用部分数据做展示,使用全部数据训练时间会相应变长
if len(self.data) > 10000:
break
随笔9:一定要记住将输入进去的数据和对应的标签全部要转化为tensor类型,最好就是长整型
之后将一句话的下标映射tensor和对应的切点标签tensor添加进data列表里面。
后面做了一个停止循环的过程,如果句子已经达到了10000句,就先打住,这样的操作适合小数据。
def __len__(self):
return len(self.data)
def __getitem__(self, item):
return self.data[item]
class Dataset::作为返回一张训练数据和对应标签的类,自然也会重写__getitem__和__len__.前者可以直接用对象[idx]返回对应的训练数据和标签,后者用len(对象)可以直接返回def len(self):对应的返回内容,一般都是整个训练集的个数。
def build_dataset
#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):
dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__
data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torch
return data_loader
之后将一句话数据处理的类的对象放到DataLoader里面,设置每个epoch开始之前,都会数据做打乱处理,batch_size = 20 。
最后返回处理一个batch的数据处理的类的对象,作为for循环利用索引来提取对应的内容。
def main():
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
当我们得到一个batch的数据以后,就需要把这个batch输入到我们的训练模型中,该训练模型既可以有RNN,也可以用CNN,也可以i搭配全连接,看你自己的选择,但是必须包含编码的embedding。
class TorchModel(nn.Module):
class TorchModel(nn.Module):
def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab) + 1, input_dim) #shape=(vocab_size, dim)
self.rnn_layer = nn.RNN(input_size=input_dim,
hidden_size=hidden_size,
batch_first=True,
num_layers=num_rnn_layers,
nonlinearity="relu",
dropout=0.1)
self.classify = nn.Linear(hidden_size, 2)
self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)
其中初始化中的vocab就是我们创建的字与数字的映射字典,假设我们的字一共有4000个,那么这个字典的长度为4001,这里初始化embedding的行又加了个1,这个1主要是对于0号索引,因为vocab中并没有0号的映射,0其实是我们padding的下标。这里的input_dim设置为50,也是任意都可以,大网络经常设置为128或者128的倍数。
从结构可以看出来这里使用的RNN网络,我们需要输入的参数一个是我们一个字的编码维度,也就是input_dim,即50.一个是我们想要映射到的维度,hidden_dim设置为100。
随笔10:其实RNN和全连接层最后的映射结果都是相似的,把一个维度映射到另一个维度,前者关心前前后后的影响,后者只是融合,但是是整体的融合,整体的融合相当于没融合。
这里还设置了RNN堆叠的层数为3,也就是之前讲述的RNN网络上下排列进行串联。激活函数为relu,dropout为0.1
最后还设置了一个全连接层,输入的维度就是我们一个字映射后的维度hidden_dim,输出为2,也就是表示预测的切点是0还是1.对于2来说,1,0就是0。0,1就是1.
损失函数选择交叉熵函数,里面有一个ignore_index设置为-100,这和我们设置字符的切点标签padding部分的-100是对应的。也就是说-100标签对应的字符预测结果不会参与到交叉熵的计算,自然反向传播的时候也不会受到其影响,这就排除了padding的影响。
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)
y_pred = self.classify(x) #output shape:(batch_size, sen_len, 2)
if y is not None:
return self.loss_func(y_pred.view(-1, 2), y.view(-1))
else:
return y_pred
将各个层串起来。首先将x,其shape为[b,20]输入到编码器中获取对应索引的编码,运行后的x.shape=[b,20,50].
随笔11:RNN网络的输入是三维哦,0表示batch,1表示字符个数,2表示字符编码维度。
随笔12:nn.RNN中的batch_first默认是False,一定要修改过来
经过RNN网络以后得到映射后的shape为[b,20,100]
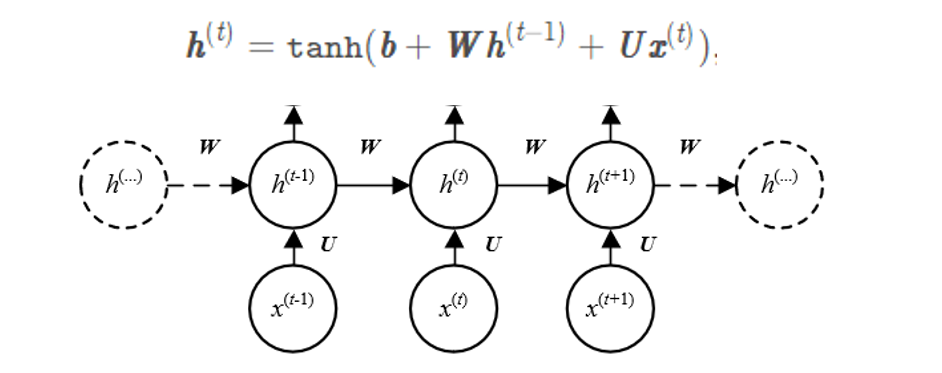
这里重点说一下RNN网络的输出:
我们之前说过一个RNN网络需要训练的参数只有W和U,h都是全0初始化,h的作用相当于是反应RNN网络进行到某个阶段的输出,我们之前输出过一个RNN层的两个输出的格式:
tensor([[[ 0.7973, -0.7923, -0.6053, 0.0629, 0.7845, -0.8398],
[ 0.9910, -0.9805, -0.2413, -0.0800, 0.9970, -0.9991],
[ 0.9997, -0.9982, -0.5220, -0.2173, 0.9999, -1.0000],
[ 0.9788, -0.7375, 0.6682, -0.5727, 0.9812, -0.9964]]],
grad_fn=<TransposeBackward1>)
tensor([[[ 0.9788, -0.7375, 0.6682, -0.5727, 0.9812, -0.9964]]],
grad_fn=<StackBackward0>)
所以output实际上也就是我们每一个阶段的hi单纯的堆叠起来。就成了我们RNN网络的总输出,顺便带出来的hn其实就是最后一步得到的hi。
首先不同的batch肯定是经过相同的RNN层,那么一句话的字符输入进去,不同的字符编码占据各个xi,最后得到的hi实际的shape仅仅就是[hidden_dim]的长度,这也是我们初始的时候创建h0的时候它的shape。也就是说一句话只能产生一个[hidden_dim]的hi,那么batch句话就能产生batch个不同的hi。也就是说我们的RNN只有一层,那么最后得到hi的shape为[B,hidden_dim],但是我们看到,就算我们把batch设置为1,最后还是三维的。那多出来的一维是什么呢?是RNN堆叠的层数。我们一句话虽然输出只有一个[hidden_dim],但是我们可以有很多层RNN,这样的话,一句话就会产生多个hi。所以三维的组成就是[RNN层数,Batch,hidden_dim],注意batch是第1维,不是第0维。
那么RNN的层数会影响output的维度吗?当RNN只有一层的时候,输入一句话的时候output就是各个hi的叠加,shape为[num_chars,hidden_dim],当我们增加RNN的层数的时候,无非就是把hidden_dim维映射到hidden_dim维,然后重复几遍,所以一句话的输出还是[num_chars,hidden_dim],输入一个batch的时候就是[b,num_chars,hidden_dim],所以可以发现,RNN的层数并不会影响总输出output的shape。其shape为[b,num_chars,hidden_dim],batch在第0维。
另外补充一点,RNN是允许输入两维的,但是用的很少,等遇到了再讨论
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)
y_pred = self.classify(x) #output shape:(batch_size, sen_len, 2)
if y is not None:
return self.loss_func(y_pred.view(-1, 2), y.view(-1))
else:
return y_pred
所以上面经过RNN以后的x.shape=[b,20,100]
然后将RNN的输出放到全连接层里面进行降维,得到y_pred.shape=[b,20,2]
如果是训练,y存在,那么利用交叉熵损失函数对预测值和标签计算损失,计算之前需要把预测值降低到二维,y原本也是二维[b,20],然后直接用view压成1为[bx20]
如果y存在,那么表示在验证,就直接返回预测值。
番外:对于DataLoader中的collate_fn参数的进一步解释
我们已经知道的是DataLoader的作用之一就是将反复抽取一张图的训练数据和标签,然后,然后是重点,它最初的处理方式只是把每一张图的训练数据和标签作为以一个整体(这个整体的类型是什么取决于你写的提取一张图的训练数据和标签的程序返回的是什么类型,一般都是list,也就是[sample,target],也就是本例),然后简单的放到一个list里面,第一,它没有把训练内容放一块,把标签放一块,第二就算放一块,整体的类型是list也不能直接放到网络里面。所以collate_fn就是做这件事的。我们首先说一下默认的collate_fn的作用是什么:就是把训练数据放一块,形成一个batch的tensor,标签放一块,形成一个batch的tensor,二者组成一个list,之后用循环就能分别调取这两个tensor。在本例里面,我们就使用的是默认的collate_fn,在本例中我们每一个数据读取出来的格式为[tensor,tensor],请注意最外面是列表。那么如果使用的默认的collate_fn就只能把一张图的训练数据和标签放在一个list里面吗?可以放在元组或者其他形式吗?这就要从collate_fn的源码说起了,我只列出相关的代码:
def default_collate(batch):
elem = batch[0]
elem_type = type(elem)
if isinstance(elem, torch.Tensor):
out = None
if torch.utils.data.get_worker_info() is not None:
# If we're in a background process, concatenate directly into a
# shared memory tensor to avoid an extra copy
numel = sum(x.numel() for x in batch)
storage = elem.storage()._new_shared(numel)
out = elem.new(storage).resize_(len(batch), *list(elem.size()))
return torch.stack(batch, 0, out=out)
我们知道输入的这个batch实际就是一个list,然后list里面每一个元素就是一个小list,也就是[sample,target],所以这里的elem就是第一个样本的训练数据和标签,它的类型是list,所以elem_type 就是list。
所以它自然不会符合下面if的条件,因为它的里面才是torch.tensor。看后面的源码可以知道,它实际是根据输入进来的batch的类型采取不同的操作,返回不同的信息。所以如果elem是list如何操作呢?在这一行:
elif isinstance(elem, collections.abc.Sequence):
在这一行,其中collections.abc.Sequence就是一种范围更广的list,可以理解成序列的类型。所以单纯找list是找不到的。
# check to make sure that the elements in batch have consistent size
it = iter(batch)
elem_size = len(next(it))
if not all(len(elem) == elem_size for elem in it):
raise RuntimeError('each element in list of batch should be of equal size')
后面紧接着做了一个判断,首先将batch,也就是大list取了一个迭代器,用next(it)得到了第一个小list,所以elem_size 在我们这个例子中等于2,之后循环遍历从第二个开始的每一个小list,如果后面的小list里面的元素个数不等于2,那么就会报错。也就是说每一个图片得到的该图片的信息都必须是两个(一个是sample,一个是target)。
transposed = list(zip(*batch)) # It may be accessed twice, so we use a list.
if isinstance(elem, tuple):
return [default_collate(samples) for samples in transposed] # Backwards compatibility.
else:
try:
return elem_type([default_collate(samples) for samples in transposed])
except TypeError:
# The sequence type may not support `__init__(iterable)` (e.g., `range`).
return [default_collate(samples) for samples in transposed]
先用*list的方法把每一个小list脱开list的束缚取出来。即从:
[[2], [3], [4], [5]]
#转为
[2] [3] [4] [5]
然后用zip形成一个迭代器,来提取每一个小list相同位置的信息放在一块,也就是sample们放在一块,target们放在一块
随笔12:zip()是没办法打印出来的,指挥显示它是第一个迭代器,可以采取前面加list的方法让它显形。
这样的话transposed 就是一个list里面装两个大tensor,一个是一个batch的samples,一个是一个batch的targets。
而一个batch的samples或者targets之间每个图片的是存放在一个turple里面的,也就是说transposed 的类型为:
[(troch.tensor , torhc.tensor…),(troch.tensor , torhc.tensor…)]
首先判断elem是不是tuple,虽然我们这里是list,但是不妨碍我们进去看看,就假设是两个tensor装进一个tuple。
先用循环取出来transposed 里面的训练集和标签集,都是tuple。然后重新放到这个函数里面,请注意,这里直接就启动第一个if了,因为我们输入进去的是(troch.tensor , torhc.tensor…),而我们判别类型用的是:elem = batch[0],所以elem的类型并不是tuple,而是torch.tensor。
所以直接把输入的(troch.tensor , torhc.tensor…),在最外围进行stack,如果torch.tensor.shape=[3,416,416],那么返回的就是[b,3,416,416],这就完成了一个batch的整合,另一个标签同理。所以如果类型是tuple,最后return回去的就是:
[[b,3,416,416],[b,10]](数据都是假设的,10没有实际意义),类型为[tensor,tensor].
所以如果是一张图片返回的类型是tuple是可以的,但是必须有一个’_fields’这个玩意儿
if isinstance(elem, tuple):
return [default_collate(samples) for samples in transposed] # Backwards compatibility.
else:
try:
return elem_type([default_collate(samples) for samples in transposed])
except TypeError:
# The sequence type may not support `__init__(iterable)` (e.g., `range`).
return [default_collate(samples) for samples in transposed]
因为我们是list,所以if不满足条件,后面的操作流程基本是一样的,因为我们是list,所以二者的流程完全一样。也不会触发下面的except。
以上就是默认的处理方式,基本可以满足我们的要求
但是,我们可以看到,里面会对数据进行stack操作,前提上进行操作的数据的shape是完全一样的。所以当我们的每一条的数据的长度不一致而又没有进行padding的时候,那么默认的collate_fn失效。所以我们必须重写collate_fn。我们用YOLOV3里面的collate_fn重写来看看是如何操作的:
def collate_fn(self, batch):
paths, imgs, targets = list(zip(*batch))
# Remove empty placeholder targets
targets = [boxes for boxes in targets if boxes is not None]
# Add sample index to targets
for i, boxes in enumerate(targets):
boxes[:, 0] = i
targets = torch.cat(targets, 0)
# Selects new image size every tenth batch
if self.multiscale and self.batch_count % 10 == 0:
self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
# Resize images to input shape
imgs = torch.stack([resize(img, self.img_size) for img in imgs])
self.batch_count += 1
return paths, imgs, targets
你甭管重写的规则是啥,二者的输入都是一样的。都是[单张输出格式,单张输出格式,单张输出格式…]
我们这里单张的输出格式为(img_path, img, targets),大类型是一个tuple。所以batch就是:
[(img_path, img, targets),(img_path, img, targets),(img_path, img, targets)…]
zip我们上面后跟的列表,这里是元组,其实只要是序列,都可以用zip来迭代。你把元组换成列表,最后的输出是一样的。
如果我们只看它返回的imgs,它其实制作了一个stack的操作,和默认的一样,返回的targets也先使用循环组成一个batch的数据(此时targets已经是二维),然后修改了某个数,这个数要来显示该目标来自于哪个图,最后用torch。cat同样得到一个有着batch维度的大tensor。(stack要改变维度,cat不会改变维度)
随笔12:torch的操作不一定数据必须全都是tensor,比例tensor外面包一个list或者tuple都是可以操作的,把list和tuple所在的维度看作一个tensor最大的外围维度就可以了,但是!输入网络必须要全是tensor
为什么我这里举的例子好像没有进行padding,因为padding好多时候在处理一张图的时候就已经做完了,collate_fn的目的更多的是对数据进行整合,另外做一些数据的小修改,使其符合一些特殊网络的要求,有的步骤确实可以放在处理一张图的时候做,但是有的步骤一个batch一起处理会更高效,或者只能一个batch的时候做,比如上面对targets的第一位的修改,只能配合batch的索引进行修改。
def main():
data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器
#训练开始
for epoch in range(epoch_num):
model.train()
watch_loss = []
for x, y in data_loader:
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
#保存模型
torch.save(model.state_dict(), "model.pth")
创建模型以后对优化器进行初始,然后就可以开始训练了
模型设置为循环模式
准备损失列表
进入循环以后对一个batch的数据进行提取,一个batch的数据类型是[tensor,tensor]自然xy都是tensor了
ps:在我们YOLOV3的举例中返回的是tuple,其实都一样,循环可不会管你最外层是什么。
随笔13:我们可以假设其实data_loader就是一个大列表[ [batch], [batch], [batch], [batch]…]每次循环的拿一个batch,这个batch可以是列表框着,也可以是tuple,不影响。
训练完毕以后保存模型的参数到model.pth文件以便后面进行预测。
#保存词表
writer = open("vocab.json", "w", encoding="utf8")
writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))
writer.close()
return
由于我们是写,所以相当于会创建一个vocab.json文件,然后把我们在网络里面设置好的字符与数字的映射字典保存进去。
def predict
#最终预测
def predict(model_path, vocab_path, input_strings):
#配置保持和训练时一致
char_dim = 50 # 每个字的维度
hidden_size = 100 # 隐含层维度
num_rnn_layers = 3 # rnn层数
vocab = build_vocab(vocab_path) #建立字表
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
model.load_state_dict(torch.load(model_path)) #加载训练好的模型权重
model.eval()
创建模型,创建字符与下标映射的字典(但是我们已经创建好了,只需要把json格式转一下就可以了),将训练好的参数载入模型。将模型设置为验证模式。
for input_string in input_strings:
#逐条预测
x = sentence_to_sequence(input_string, vocab)
with torch.no_grad():
result = model.forward(torch.LongTensor([x]))[0]
result = torch.argmax(result, dim=-1) #预测出的01序列
#在预测为1的地方切分,将切分后文本打印出来
for index, p in enumerate(result):
if p == 1:
print(input_string[index], end=" ")
else:
print(input_string[index], end="")
print()
我们输入的需要预测句子是很多据组成的列表,形如
input_strings = ["同时国内有望出台新汽车刺激方案",
"沪胶后市有望延续强势",
"经过两个交易日的强势调整后",
"昨日上海天然橡胶期货价格再度大幅上扬"]
这里选择逐句进行分词,我认为可能得到结果不难,但是把结果显示各个句子的字符串上面就比较难了。所以选择一条一条输进去,还有一个问题就是我们创建的sentence_to_sequence也只能对一个句子的字符进行映射,x的shape其实是1维的。然后输入进去的x外面套了一个[],也不叫变成了二维,因为现在全体并不是tensor,所以加了个torch.LongTensor,这样就是二维tensor了,刚好符合网络的输入要求。得到预测结果取了个0表示把预测出来的二维变成一维,因为batch是1.由于y_pred.shape=[b,20,2],取了个[0]就是[20,2]
然后利用torch.argmax把2里面最大值的下标,所以result.shape=[20]
之后利用循环,在result每一个为1的地方进行断句(因10是0,01是1,所以第1号下标大的预测的就是1)
ps:我们可以发现padding的部分其实也进入了网络,并且也从embedding里面获得了编码,我们知道在网络里面,并不是说你输入一个字符,那么对应位置的输出就完全是这个字符的输出,不管是全连接还是RNN,都会融合一点别的字符的信息,之所以是一一对应只是因为我们后面用标签来强制规定的,机器只是照着我们的方向训练而已。
if __name__ == "__main__":
main()
input_strings = ["同时国内有望出台新汽车刺激方案",
"沪胶后市有望延续强势",
"经过两个交易日的强势调整后",
"昨日上海天然橡胶期货价格再度大幅上扬"]
# predict("model.pth", "chars.txt", input_strings)
最后真main和预测,整个流程就结束了。
总结
- 目前的分词在大部分情况下,效果已经比较理想,优化空间不大
- 分词即使发生错误,下游任务也不一定会发生错误,所以不值得花大量精力优化分词
- 随着神经网络和预训练模型的兴起,中文任务逐渐不再需要单独分词,因为网络已经被训练能很好得寻找句子中的规律
- 解决不了的问题,是真的不好解决了,例如网红带节奏的词。
















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









