







目录
1.数字信号处理基础
模拟信号到数字信号转化(ADC)
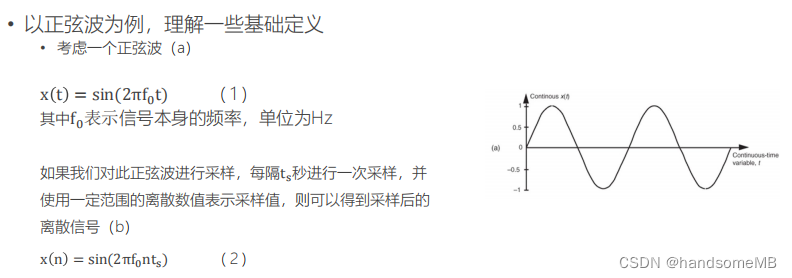
在科学和工程中,我们遇到的大多数信号都是连续的模拟信号,例如电压随着时间的变化,一天中温度的变化等等。但是计算机只能处理离散的信号,因此,必须对这些连续的模拟信号进行转化,通过采样和量化,转换成数字信号。
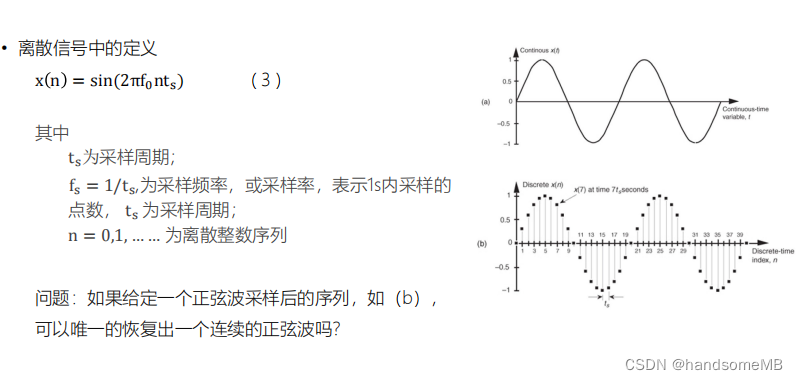
这个问题的答案是不一定,因为会有频率混叠的现象出现。
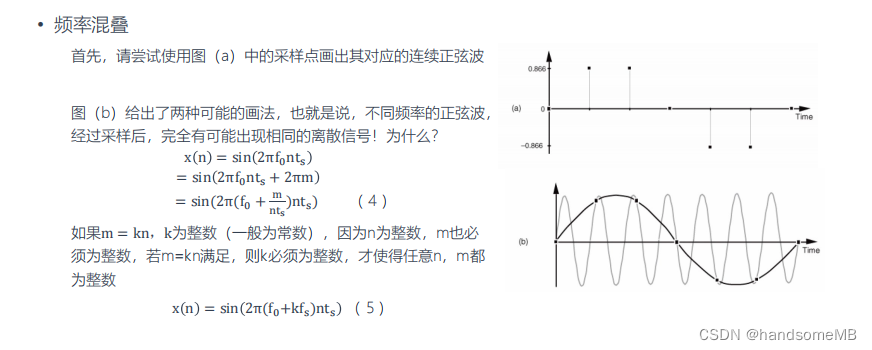
为了杜绝频率混叠现象的出现,下面我们介绍一下奈奎斯特定理。

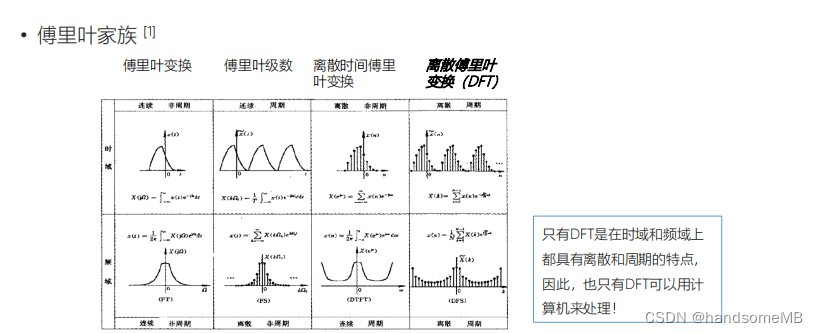
2.离散傅里叶变换(DFT)
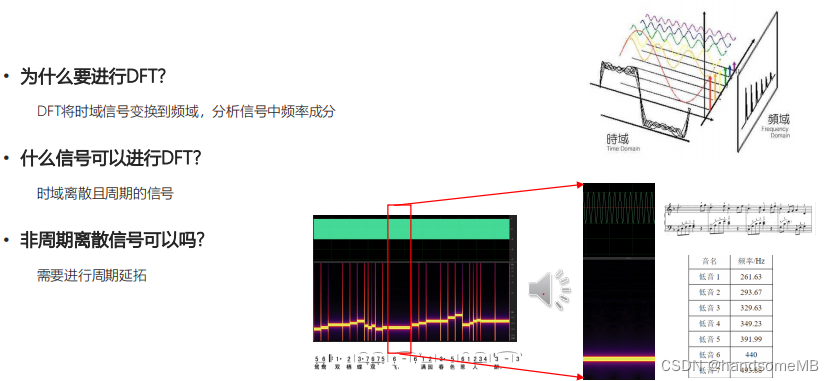
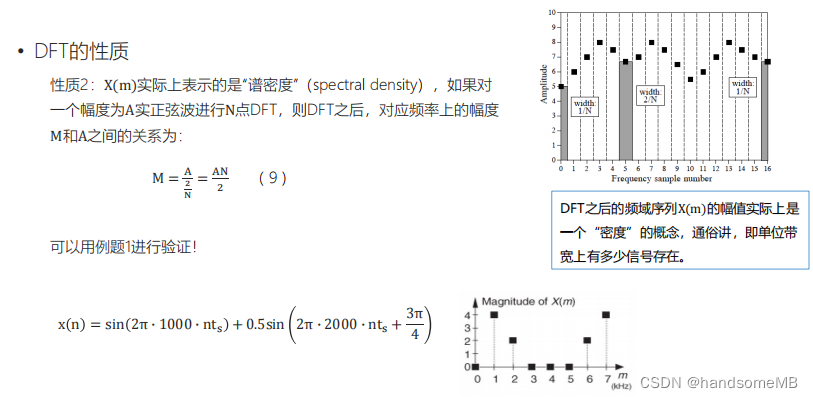
 离散傅里叶变换的性质
离散傅里叶变换的性质




3.Fbank和MFCC特征提取
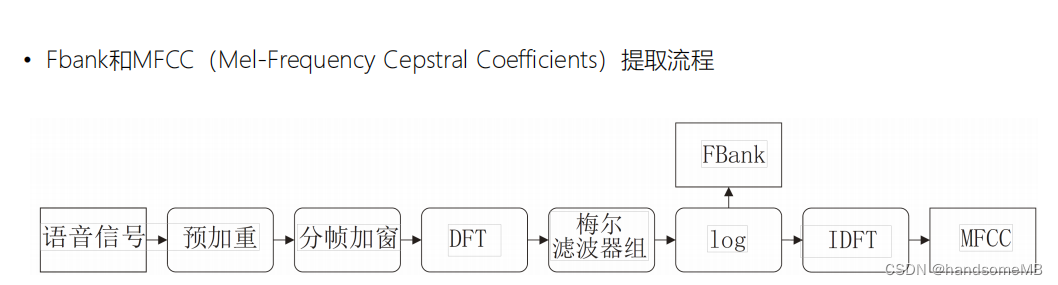
Fbank
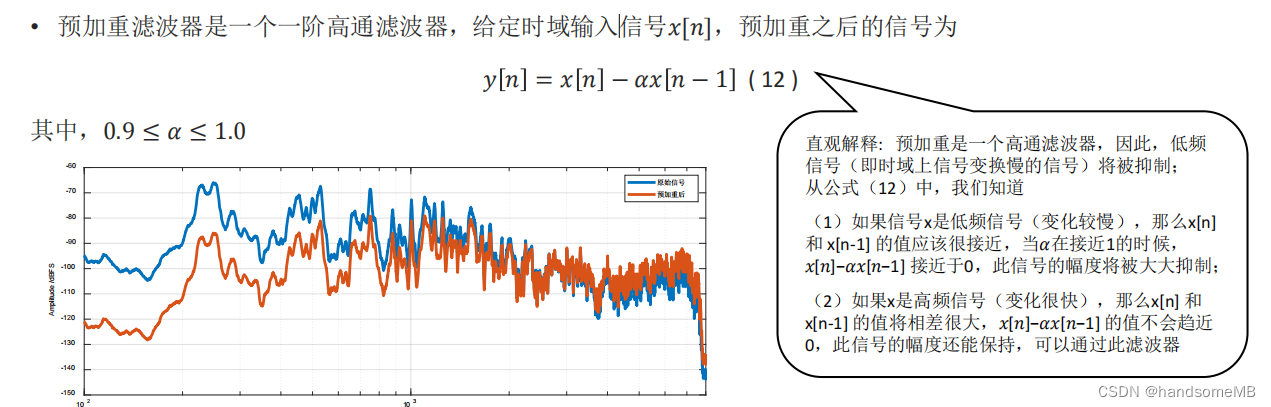
(1)预加重(pre-emphasis)
为什么要进行预加重?
提高信号高频部分的能量,高频信号在传递过程中,衰减较快,但是高频部分又蕴含很多对语音识别有利的特征,因此,在特征提取部分,需要提高高频部分能量。
(2)分帧加窗

分帧的过程,在时域上,即用一个窗函数和原始信号进行相乘。公式为y[n]=w[n] * x[n]。w[n]称为窗函数,常用的窗函数有两类,一种叫做矩形窗,一种叫做汉明窗(Hamming) 。
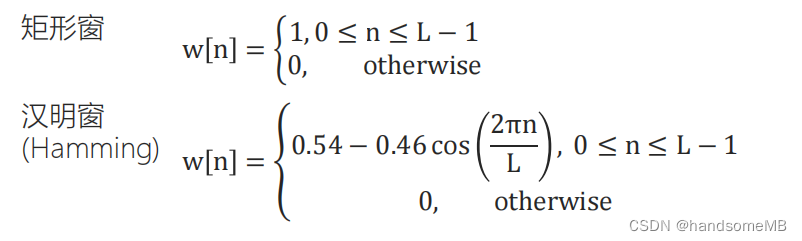
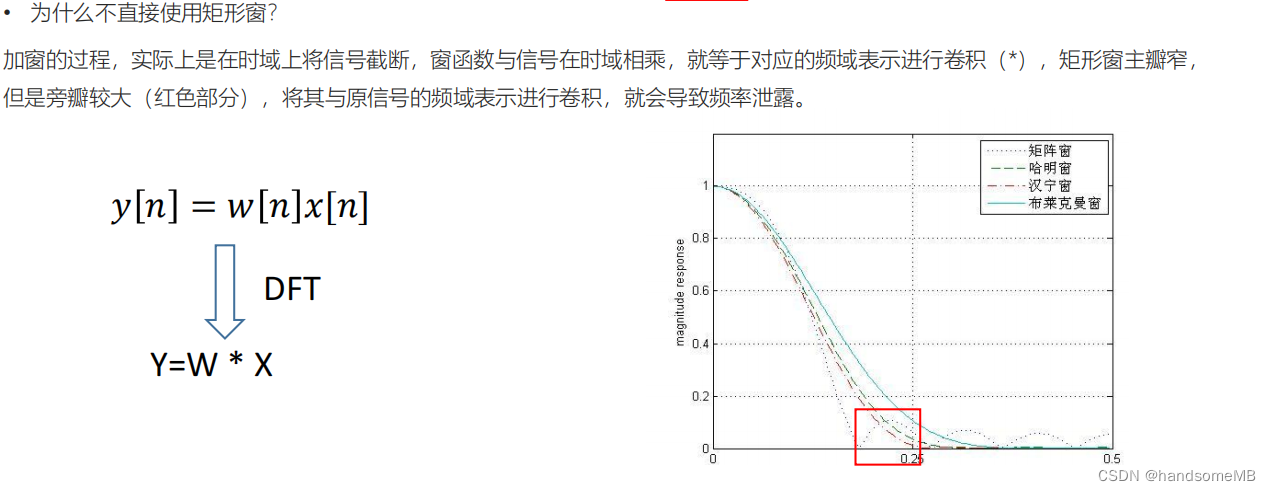
(3)DFT
在将时域信号进行了预处理和加窗后,我们使用离散傅里叶变换,将时域信号转为频域信号。当然使用FFT也是可以的。由于对称性的存在,我们通常只需要保留前N/2+1个点。然后我们取DFT系数的模便可得到谱特征(spectrum)。
(4)梅尔滤波器组
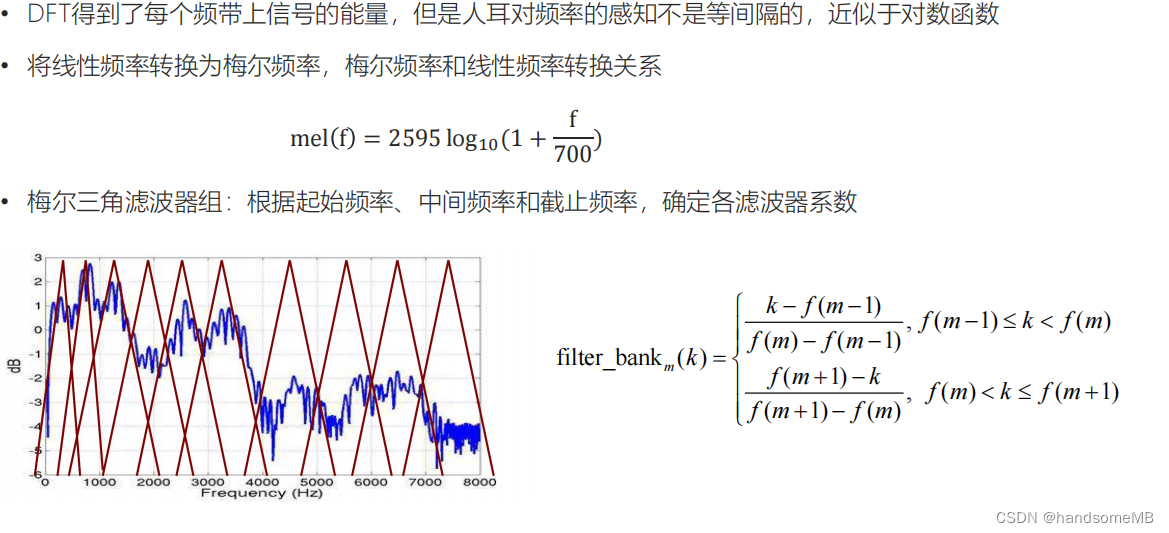

关于这一部分内容,比较难懂,可以看第5部分作业代码的内容加深理解。
(5)取对数

MFCC
MFCC特征在Fbank特征基础上继续进行IDFT变换等操作。IDFT之后的第1~K个点,为K维MFCC特征。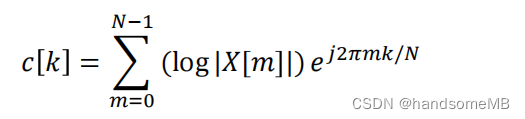
我们也可以使用离散余弦变换(DCT)来求MFCC。DCT的实质是去除各维信号之间的相关性,将信号映射到低维空间。
4.总结
本节内容非常重要,必须要好好掌握。MFCC特征一般用于对角GMM训练,各维度之间相关性小,Fbank特征则一般用于DNN训练。
5.作业代码
import librosa
import numpy as np
from scipy.fftpack import dct
# If you want to see the spectrogram picture
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
def plot_spectrogram(spec, note, file_name):
"""Draw the spectrogram picture
:param spec: a feature_dim by num_frames array(real)
:param note: title of the picture
:param file_name: name of the file
"""
fig = plt.figure(figsize=(20, 5))
heatmap = plt.pcolor(spec)
fig.colorbar(mappable=heatmap)
plt.xlabel('Time(s)')
plt.ylabel(note)
plt.tight_layout()
plt.savefig(file_name)
# preemphasis config
# 预加重参数alpha
alpha = 0.97
# Enframe config
# 对于采样率为16kHz的信号,帧长、帧移一般为25ms、10ms,即400和160个采样点
frame_len = 400 # 25ms, fs=16kHz
frame_shift = 160 # 10ms, fs=15kHz
fft_len = 512
# Mel filter config
# 要提取12维MFCC特征和23维FBank
num_filter = 23
num_mfcc = 12
# Read wav file
wav, fs = librosa.load('./test.wav', sr=None)
# 第一步,对语音信号进行预加重
def preemphasis(signal, coeff=alpha):
"""perform preemphasis on the input signal.
:param signal: The signal to filter.
:param coeff: The preemphasis coefficient. 0 is no filter, default is 0.97.
:returns: the filtered signal.
"""
# 预加重公式为y[n] = x[n] - alpha * x[n-1]
return np.append(signal[0], signal[1:] - coeff * signal[:-1])
# Enframe with Hamming window function
# 第二步,对预加重的信号进行分帧加窗
def enframe(signal, frame_len=frame_len, frame_shift=frame_shift, win=np.hamming(frame_len)):
"""Enframe with Hamming widow function.
:param signal: The signal be enframed
:param win: window function, default Hamming
:returns: the enframed signal, num_frames by frame_len array
"""
num_samples = signal.size
# 原始数据共能分成int(num_frames)个帧
num_frames = np.floor((num_samples - frame_len) / frame_shift) + 1
# 创建同维度的0矩阵用来存放这int(num_frames)个帧的数据
frames = np.zeros((int(num_frames), frame_len))
for i in range(int(num_frames)):
# 截取对应的每一帧
frames[i, :] = signal[i * frame_shift:i * frame_shift + frame_len]
# 对每一帧加汉明窗
frames[i, :] = frames[i, :] * win
# 返回结果
return frames
# 第三步,进行傅里叶变换。分帧之后的语音帧,由时域变换到频域,取DFT系数的模,得到谱特征(频谱)
def get_spectrum(frames, fft_len=fft_len):
"""Get spectrum using fft
:param frames: the enframed signal, num_frames by frame_len array
:param fft_len: FFT length, default 512
:returns: spectrum, a num_frames by fft_len/2+1 array (real)
"""
# 在此处使用的是快速傅里叶变换,在使用时常将一帧凑成2的整数次方。
# 例如在语音特征提取阶段,对于16k采样率的信号,一帧语音信号长度为400个采样点,为了进行512点的FFT,通常将400个点补0,得到512个采样点。
cFFT = np.fft.fft(frames, n=fft_len) # CFFT的维度为(356, 512)
# 由于对称性的存在,在进行N点DFT之后,只需要保留前N/2+1个点,即512/2 + 1 = 257
valid_len = int(fft_len / 2) + 1
# 取系数的模,得到谱特征
spectrum = np.abs(cFFT[:, 0:valid_len]) # spectrum的维度为(356, 257)
return spectrum
# 第四步,设计梅尔滤波器组和对数操作得到Fbank特征
def fbank(spectrum, num_filter=num_filter):
"""Get mel filter bank feature from spectrum
:param spectrum: a num_frames by fft_len/2+1 array(real)
:param num_filter: mel filters number, default 23
:returns: fbank feature, a num_frames by num_filter array
DON'T FORGET LOG OPRETION AFTER MEL FILTER!
"""
feats = np.zeros((int(fft_len / 2 + 1), num_filter)) # feats的维度为(257, 23)
# 梅尔滤波器设计原理
# 将信号的最高频率和最低频率 映射到Mel 频率上, 根据Mel 滤波器的个数K, 在Mel低频率和Mel 高频率之间 线性间隔出 K 个附加 点, 共 (K + 2) 个 Mel频率点m(i)。
low_mel_f = 0
# 最高mel值,最大信号频率为 fs/2
high_mel_f = 2595 * np.log10(1 + (fs // 2) / 700)
# 线性划分梅尔频率范围为num_filter + 1段,产生num_filter + 2个Mel频率值
mel_points = np.linspace(low_mel_f, high_mel_f, num_filter + 2)
# 将梅尔频率转值按照公式换为对应的线性频率,
fre_points = 700 * (10 ** (mel_points / 2595.0) - 1)
# 计算Mel滤波器系数
# mid为各个mel滤波器中心点对应FFT/DFT的区域编码。公式为 (N+1)/fs * fre_points。N为DFT/FFT时的长度,fs为采样频率。
mid = (fft_len + 1) * fre_points / fs
for m in range(1, num_filter + 1):
left = int(mid[m - 1])
center = int(mid[m])
right = int(mid[m + 1])
for k in range(left, center):
feats[k, m - 1] = (k - left) / (center - left)
for k in range(center, right):
feats[k, m - 1] = (right - k) / (right - center)
# 计算fbank并取对数
feats = np.dot(spectrum, feats)
feats = 20 * np.log10(feats) # DB (356,23)
return feats
# 第五步,MFCC特征在Fbank特征基础上继续进行IDFT变换等操作,IDFT之后的第1~K个点,为K维MFCC特征,例如使用DCT离散余弦变换,DCT的实质是去除各维信号之间的相关性,将信号映射到低维空间。
def mfcc(fbank, num_mfcc=num_mfcc):
"""Get mfcc feature from fbank feature
:param fbank: a num_frames by num_filter array(real)
:param num_mfcc: mfcc number, default 12
:returns: mfcc feature, a num_frames by num_mfcc array
"""
feats = np.zeros((fbank.shape[0], num_mfcc)) # 维度为(356,12)
# 直接使用DCT变换即可
feats = dct(fbank, type=2, axis=1, norm='ortho')[:, 1:(num_mfcc + 1)]
return feats
def write_file(feats, file_name):
"""Write the feature to file
:param feats: a num_frames by feature_dim array(real)
:param file_name: name of the file
"""
f = open(file_name, 'w')
(row, col) = feats.shape
for i in range(row):
f.write('[')
for j in range(col):
f.write(str(feats[i, j]) + ' ')
f.write(']\n')
f.close()
# 主函数
def main():
# 模拟信号只有通过A/D转化为数字信号后才能用软件进行处理
# wav是音频的振幅矩阵,类型是ndarray,其维度为(57280,)
wav, fs = librosa.load('./test.wav', sr=None)
# 第一步,预加重, 得到的signal的维度还是(57280,)
signal = preemphasis(wav)
# 第二步,分帧加窗
frames = enframe(signal)
# 第三步,进行离散傅里叶变换,将语音帧由时域变换到频域,取DFT系数的模,得到各帧的频谱
spectrum = get_spectrum(frames)
# 获取频域特征Fbank
fbank_feats = fbank(spectrum)
# 获取MEL频率倒谱系数特征Mfcc
mfcc_feats = mfcc(fbank_feats)
# 将提取到的语音特征保存及可视化
plot_spectrogram(fbank_feats.T, 'Filter Bank', 'fbank.png')
write_file(fbank_feats, './test.fbank')
plot_spectrogram(mfcc_feats.T, 'MFCC', 'mfcc.png')
write_file(mfcc_feats, './test.mfcc')
if __name__ == '__main__':
main()
本次作业网址:https://github.com/nwpuaslp/ASR_Course/tree/master/02-feature-extraction














 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









