






参考B站视频
Lucene
Lucene是Apache提供的一个全文搜索核心工具包(无法直接使用),Elasticsearch与Solr是对其封装
Elasticsearch优点
除了进行文本搜索,还可以用于处理分析查询
支持分布式索引,具有良好的可伸缩性
提供更多的关键指标
端口
9300集群通信端口,9200为浏览器访问端口(通过URL进行数据操作也是该接口)
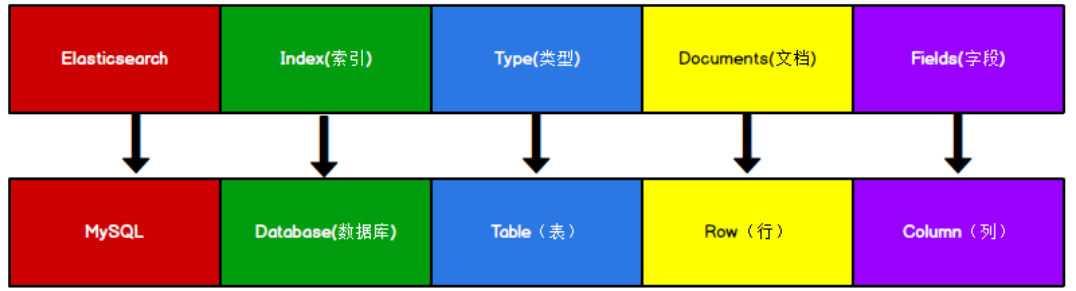
与数据库对应
普通查询通过id查询内容,使用正排索引,而Elasticsearch要做全文索引使用正排索引效率太低,使用倒排索引(根据关键字查找Id)
因此Type的概念逐渐弱化,在Elasticsearch7.X中已经删除Type(注意下面使用的是6type必须有,因为7对JDK要求太高)
URL操作(下面所有的URL全部简写)
PUT http:///索引名称 (创建索引,不允许多次创建同一个索引)
GET http:///索引名称 (查看索引信息)
DELETE http:///索引名称 (删除指定索引信息)
GET http:///_cat/indices?v (查看所有索引信息)
POST http:///索引名称/类型名 (需要Body请求体添加JSON信息)(向指定表中添加数据Id随机)
POST http:///索引名称/类型名/指定Id (需要Body请求体添加JSON信息)(向指定表中添加数据Id按指定的Id)
GET http:///索引名称/类型名/Id (按id查找)
PUT http:///索引名称/类型名/Id (需要Json请求体)(全量更新直接覆盖原来的数据)
POST http:///索引名称/类型名/Id (需要Json请求体)(增量更新,只更新提供的,不能添加原来未存在的)
DELETE http:///索引名称/类型名/Id (按Id删除数据)(删除文档只是逻辑删除)
GET http:///sk/_search (按条件查询,没有条件查询全部)(可以使用JSON或参数添加条件,推荐使用JSON)
{
"query":{
"match":{ // 指定匹配条件
"name":"博丽灵梦"
}
},
"from":0,//指定开始位置
"size":1,//查询几条
"_source":["age"],//显示的字段
//"_source":{
// "includes":[] 也可以更加详细设置 设置显示includes 或不显示excludes
//}
"sort":{// 排序条件
"age":{// 会先按上面的再按下面的分组排序
"order":"desc"
}
}
}
{
"query": {
"bool": {//指定匹配布尔值
"must": [//里面的条件必须同时满足 同理 should只需要里面的满足一个 must_not 必须不
{
"match": {//默认只要包含里面的分词就查询 例如 梦雨 会查询 博丽灵梦与雾雨魔理沙
// 可以使用 match_phrase不使用分词 进行模糊查询 使用 梦依旧可以查询 博丽灵梦
"name": "雾雨魔理沙"
}
},
{
"match": {
"age": 17
}
}
]
},
"range": {// 按范围查询
"age": {
"gt": 16 //指定age大于16 gt > get >= lt < lte <=
}
}
}
}
{
"query": {
"match": {
"name": "灵梦"
}
},
"highlight": {// 指定对查询到的字段 进行高亮显示
"pre_tags":"<br>",//指定高亮的前置标签
"post_tags":"</br>",//指定后置标签
"fields": {
"name": { }
}
}
}
{
"aggs": {//指定使用聚合操作
"names": {//指定分组名称 随意
"terms": {
"field": "age"//指定分组字段
}
},
"avg": {//指定分组名称
"avg": {//指定求平均值
"field": "age"//指定分组字段
}
},
"name":{
"cardinality":{//对指定字段去重后 统计总和
"field":"age"
}
},
"name2":{
"stats":{// 对指定字段 一次性求 count,min,max,avg,sum
"field":"age"
}
}
}
}
{
"query":{
"terms":{// 指定多个匹配 or 类似 mysql in
"name":["雨","梦"]
}
//"term":{//指定单个匹配
// "name":"雨"
//}
}
}
模糊查询
编辑距离是把一个字符转换为另一个字符所需的次数
操作支持:更改一个字符,删除一个字符,插入一个字符,装置两个相邻的字符
fuzzy会查找在指定编辑距离的完全匹配
{
"query":{
"fuzzy":{//使用案例
"name":"雨"
}
}
}
POST http:///索引名称/类型名称 (根据JSON进行定制表,注意同一个索引只能由一个类型)
{
"properties":{
"name":{//字段名
"type":"text",//指定全文索引
"index":true//可以利用来搜索
},
"sex":{
"type":"keyword",//关键字索引 必须全部匹配才可以
"index":true
},
"tel":{
"type":"keyword",
"index":false,//不能用来索引 默认值为true
"store":false,//是否独立存储 默认false(默认存储在_source) 独立存储可以获取更好的搜索性能不过更占用内存
"analyzer":"ik_max_word"//指定使用的分词器 默认ik_max_word使用ik分词器
}
}
}
类型主要支持
String: text:可分词 keyword:不可分词,必须完全匹配
Num: long,integer,short,byte,double,float
其他类型: Date Array Object
GET http:///索引名称/_mapping (查看指定索引元数据信息)
Java使用
依赖
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 的客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 依赖 2.x 的 log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<!--日志操作-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!--JSON操作-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.60</version>
</dependency>
<!-- junit 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
简单使用
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("127.0.0.1", 9200)));// 获取客服端
// 查看,删除索引 与这个类似 请求 GetIndexRequest,DeleteIndexRequest
// 客服端使用 client.indices().get client.indices().delete
CreateIndexRequest request = new CreateIndexRequest("new");// 构造创建索引请求
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT); // 发送请求
System.out.println(response.isAcknowledged());// 判断是否发送成功
client.close();//关闭客服端
数据操作
// 创建添加请求 类型 索引 指定id
IndexRequest request = new IndexRequest().type("cher").index("new").id("2233")
// 指定信息及其类型
.source(JSON.toJSONString(new Cher("博丽灵梦",16,"女")), XContentType.JSON);
// 添加
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 更新数据请求 doc指定更新项 client.update
//new UpdateRequest().index("new").type("cher").id("2233").doc(XContentType.JSON,"sex","社会");//更新数据
//根据id查询数据 client.get
//new GetRequest().index("new").type("cher").id("2233");
//删除请求 client.delete
//new DeleteRequest().index("new").type("cher").id("2233");
Bulk批处理
BulkRequest request = new BulkRequest();// 构造批量请求
for (int i = 0; i < 10; i++) {
// 可以添加 增删改 各种请求 进行批处理
request.add(new IndexRequest("new","cher","000"+i)
.source(JSON.toJSONString(new Cher("博丽灵梦",i*2,"女")),XContentType.JSON));
}// 进行批处理
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);
使用强大的search函数(以下代码基于6.0.0的依赖)
SearchRequest request = new SearchRequest("new")
.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()));
SearchResponse response = client.search(request);
// 主要是使用 QueryBuilders链式调用添加条件
//matchQuery("name","博丽灵梦")添加匹配条件
//from(1).size(2)添加分页条件
//sort("age", SortOrder.DESC)指定排序条件
//fetchSource(new String[]{"name"},new String[0])指定显示与不显示的字段
组合布尔表达式
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//构造布尔查询
boolQuery.must(QueryBuilders.matchQuery("name","博丽灵梦"));//必须 and
boolQuery.should(QueryBuilders.matchQuery("age",10));// 可以 or
boolQuery.mustNot(QueryBuilders.matchQuery("sex","男"));// 必须不
SearchRequest request = new SearchRequest("new").source(new SearchSourceBuilder().query(boolQuery));
范围查询
RangeQueryBuilder queryBuilder = QueryBuilders.rangeQuery("age").gt(10);//构造使用范围查询
SearchRequest request = new SearchRequest("new").source(new SearchSourceBuilder().query(queryBuilder));
模糊查询
QueryBuilders.fuzzyQuery("name", "博丽梦").fuzziness(Fuzziness.TWO);//指定编辑距离,注意 中文需要两个编辑距离
高亮显示
new SearchSourceBuilder().query(QueryBuilders.termQuery("name","梦"))// 构造高亮显示条件
.highlighter(new HighlightBuilder().preTags("<br>").postTags("</br>").field("name"))
SearchHits hits = response.getHits();// 获取响应搜索结果
for (SearchHit hit:hits){
System.out.println(hit.getSourceAsString());
System.out.println(hit.getHighlightFields());// 显示高亮部分
}
使用聚合函数
SearchRequest request = new SearchRequest("new").source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery()) //指定聚合查询的名称与针对字段 其他使用方式类似
.aggregation(AggregationBuilders.avg("avg-age").field("age")));
SearchResponse response = client.search(request);
System.out.println(response.getAggregations());//获取聚合数据
配置集群(集群之间共享数据)
配置文件(config/elasticsearch.yml)
主节点配置
cluster.name: my-application # 同一个集群名字必须一致
node.name: node1001 # 节点名称必须不一致
node.master: true
node.data: true
network.host: localhost # 设置host
http.port: 1001 # 设置数据端口
transport.tcp.port: 9301 # 设置集群连接端口
http.cors.enabled: true # 开启跨域
http.cors.allow-origin: "*" # 允许所有跨域
其他节点配置
cluster.name: my-application # 同一个集群名字必须一致
node.name: node1002 # 节点名称必须不一致
node.master: true # 是否有资格成功主节点 若有多个设置 会通过选取 只选取一个作为主节点
discovery.zen.minimum_master_nodes: 3 # 配置允许选举主节点的最小数目 推荐 设置 主节点数/2+1
node.data: true # 是否存储数据 默认为true
network.host: localhost # 设置host
http.port: 1002 # 设置数据端口
transport.tcp.port: 9302 # 设置集群连接端口
discovery.zen.ping.unicast.hosts: ["localhost:9301"] #设置连接到的集群
discovery.zen.fd.ping_timeout: 1m # 设置连接超时
discovery.zen.fd.ping_retries: 5 # 设置重试次数
http.cors.enabled: true # 开启跨域
http.cors.allow-origin: "*" # 允许所有跨域
集群请求
GET http:///_cluster/health (获取指定集群信息)
status: green:所有主分片,副分片(副本)都正常允许 yellow:主分片正常运行,副分片并非 red:有主分片未正常运行
GET http:///_cat/nodes (获取所有节点信息)
核心概念
索引:有相似特征文档的集合(索引必须全部小写),用于搜索到的数据必须索引,提高查询速度
类型:对索引的逻辑分区,逐渐不再使用

文档:可被索引的基本信息单元(一条数据),以JSON的形式表示
字段:对文档不同属性的分类标识
映射:处理数据的方式与规则的限制,例如数据类型,分析器,是否被索引等
分片:将索引划分为多份,每一份都是一个分片,每个分片也是一个功能完整的索引(用于提高响应速度)
分片的优点:1,允许水平分割扩展内容容量 2,允许在分片上进行分布式,并行操作,提高性能与吞吐量
分片公式:节点数<=主分片数*(副本数+1) (注意副本数,不是副分片数,即节点数不应大于主分片+副分片数)
副本:允许为分片创建一个或多个副本,用于实现故障转移机制
副本优点:1,提供高可用性,注意副本不与原分片放到同一节点 2,扩展吞吐量,可以在所有副本并行运行
分配:master节点将分片(主分片/副本)分配给每个节点的过程,若是副本还包含从主分片复制数据的过程
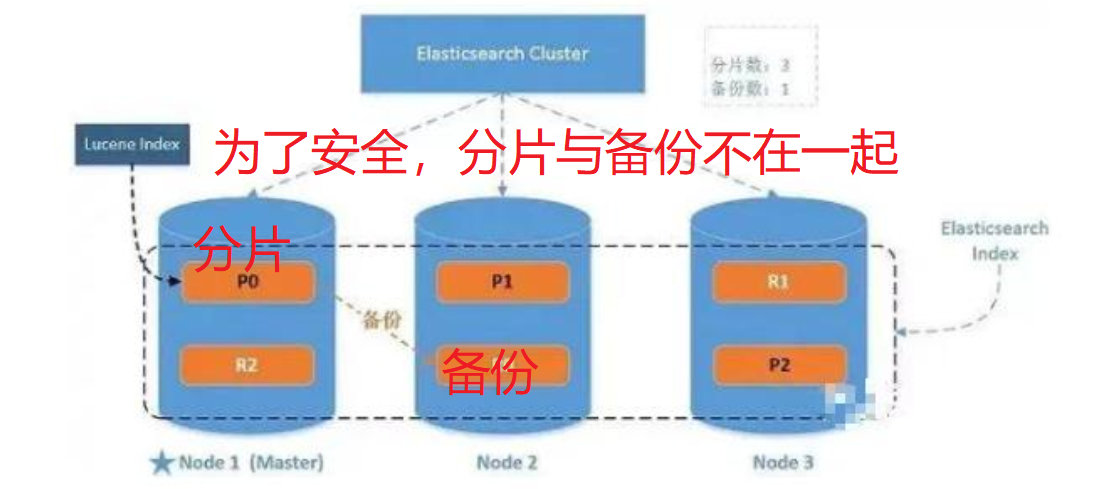
集群指令
PUT http:///索引名称
{
"settings":{
"number_of_shards":3,//设置主分片数量
"number_of_replicas":1//设置副分片数量
}
}
PUT http:///索引名称/_settings
{
"number_of_replicas":2//设置副本数量 例如 主分片为 3 副本数量为2 副分片一共 6个
}
通过浏览器插件查看

应对故障
若存在主分片的节点挂掉,会有新的副分片会提升为主分片(若主节点挂掉,类似会有新的主节点产生)
存储数据时,会通过对id Hash操作再对主分片数取余得到放到那个主分片中,获取类似,不过可以从副分片中获取(轮询用于负载均衡)
写入流程
1,计算要写入的主分片
2,主分片保存数据成功,并把数据发给多个副本
3,副本保存会向主分片反馈,主分片向客服端反馈
写入延时=主分片写入延时+(并行写入副分片的最大延时)
Translog
为了保证数据的可靠性,会在操作后记录Translog,Translog默认是写磁盘的,用于恢复数据
1,一个文档被索引后被添加到内存缓存区,并记录Translog
2,默认每秒刷新一次(近 实时搜索)把缓存写入新的段中(没有进行fsync操作)清空缓存,Translog并不清空
3,Translog大到一定程度(默认512M)或定时触发(默认30分钟),再次刷新时,会把段全量提交,清空缓存写入新段,写入一个保存点通过fsync写入文件系统,老的Translog被删除,创建新的
启动时会先使用最后一个提交点恢复已知的段,并重放Translog中所有最后一次提交后发生的修改
写操作策略(为了保证一致性,consistency参数)
one:只要主分片OK就允许写操作
all:必须所有主分片,副分片都OK才允许写操作
quorum:(默认值),主分片,及其大多数副分片没有问题允许写操作
timeout超时参数
默认若没有足够的副本(参考上面的写操作策略),ElasticSearch会等待,默认会等待1分钟,可以使用timeout手动指定超时时间
更新流程
1,计算要修改的主分片
2,修改主分片内容并尝试重新索引,若文档已被修改重复该操作,超过retry_on_conflict失败放弃(类似CAS)
3,若主节点成功更新,会把新文档转发给副本进行更新,一旦所有副本都成功更新返回成功主分片返回成功
倒排索引(通过段存储)
通过关键字查询对应的文档id
倒排索引无法修改
好处:不需要锁 可以长久的保留再内存,减少磁盘命中率,提高性能 始终有效,不需要重建 允许对倒排索引进行数据压缩
更新(先标记原来的被删除,再添加新版本)删除(直接标记删除),因为不能修改原来的倒排索引,采用添加新倒排索引的方式,会先按时间顺序搜索,被删除的会使用段对应的.del文件标记,在结果集返回之前进行移除,会在修改积累到一定程度对倒排索引进行重整(使用现存索引建立新的索引,并应用修改,删除标记删除的)
文档分析
将一块文本分成适合倒排索引的独立词条
将这些词条统一为标准格式提高他们的可搜索性
GET http:///_analyze (对指定文件进行分词)
{
"analyzer":"standard",//指定分词器
"text":"Hello World"//指定待分词的对象
}
默认无法对中文分词(会把中文拆分为一个个汉字)可以添加IK中文分词器对中文分词(注意版本必须对应)
中文分词器: ik_max_word:使用最细粒度的拆分 ik_smart:使用最粗粒度的拆分
自定义分词(需要重启)
在IK的config目录创建用户自定义字典,写入自定义分词
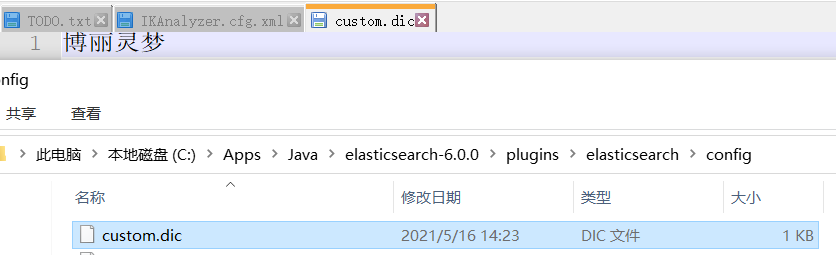
并在IK的config目录的IKAnalyzer.cfg.xml中注册

采用乐观并发控制
使用_version(版本号进行控制)每次修改_version自增,对于低版本的_version更新修改会失败
POST http:///test/sk/2233?version=5 (可以在尾部附加版本号,JSON更新数据省略)
优化写入速度
使用批量提交数据(默认批量提交数据要求数据量不超过100M)
优化存储设备
合理使用合并(Lucene以段的形式存储,当有新数据写入时自动创建新段,因为段合并消耗大量IO默认后台定期段合并)
减少Refresh的间隔(默认1s刷新一次,对于实时性不强的搜索可以加大Refresh间隔)
减少副本数量(副本复制会降低写索引的速度,若需要大量写可以考虑先禁用副本复制,写入完毕再恢复)
设置内存不要超过物理内存的50%
Lucene的段存储在单个文件,这些文件都不会变换,利于缓存,操作系统会把他们缓存起来,若设置内存过大,Lucene缓存可用内存会变小,严重影响效率
主节点选举
先判断节点数是否达到discovery.zen.minimum_master_nodes
都有被选举资格的(node.master:true)按node.name排序,靠前的作为主节点
脑裂问题(出现多个主节点)
出现原因:
网络延迟导致部分节点访问不到主节点,重新选举新的主节点
节点负载,主节点是主节点的同时也是data节点,访问量太大时,会停止响应,其他节点误以为主节点不存在
作为data节点内存回收,JVM大规模内存回收,造成主节点失去响应
解决方案:
增大主节点响应时间,减少误判
角色分离,主节点不做为data节点
设置适当的discovery.zen.minimum_master_nodes值















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









