







CLIP-Driven Multi-Scale Instance Learning for Weakly Supervised Video Anomaly Detection 论文阅读
文章信息:

原文链接:https://ieeexplore.ieee.org/abstract/document/10687724
源码:https://github.com/casperZB/CMSIL
Abstract
现有的弱监督视频异常检测方法主要利用多实例学习(MIL)来识别未修剪视频中的异常片段。然而,异常的语义和表现形式常常具有模糊性,这是MIL难以处理的问题。此外,MIL由于对每个实例进行独立优化,忽略了相邻片段之间的时间相关性,因此容易引发误报。因此,我们迫切需要更好地关联异常的表现形式与其语义,并实现多时间尺度的异常检测。本文提出了一种基于CLIP的多尺度实例学习(CMSIL)框架,该框架包含两个分支:视觉-语言(VL)分支和多尺度实例学习(MSIL)分支。VL分支利用对比语言-图像预训练(CLIP)提供的强大视觉概念先验来生成伪异常,从而为模型训练提供疑似异常的线索和指导。MSIL分支则采用特征金字塔,通过在每个金字塔层级内应用MIL,充分挖掘细粒度的时间依赖性,以学习不同时间尺度上的异常模式。通过两个分支的协同工作,所提出的CMSIL在处理持续时间各异的异常时展现出更高的能力。在XD-Violence和UCF-Crime数据集上进行的大量实验证明了本文方法的优越性能。
I. INTRODUCTION
视频异常检测(VAD)旨在在未修剪的视频中检测出异常事件,如事故、爆炸和暴力等,这些技术在智能监控[1]和暴力预警[2]等领域有着广泛的应用。然而,异常事件种类繁多且发生频率较低,这使得对它们进行详细标注既耗时又费力。为了降低标注成本,弱监督视频异常检测(WSVAD)逐渐流行起来,该方法在训练阶段仅依赖视频级别的标签(正常与异常)。
在弱监督设置的背景下,大多数现有工作[1]、[3]–[5]普遍采用多实例学习(MIL)[6]框架,将整个视频视为包含袋级标注的实例袋。在此框架下,每个实例指的是视频中的片段,由异常视频生成的袋被称为正袋,而由正常视频生成的袋则被称为负袋。目标是使负袋中每个实例的异常分数最小化,同时使正袋中每个异常实例的异常分数最大化。然而,如图1所示,基于MIL的方法面临两大主要挑战:
i) 偏向于简单的异常片段——由于异常语义的模糊性和细粒度标注的稀缺性,MIL检测器可能会错误地对某些片段赋予高置信度,或者仅关注具有简单背景的异常片段;
ii) 忽略时间依赖性——由于视频被分割成独立的实例,每个实例都被视为一个独立的优化单元,因此MIL忽略了相邻片段之间的时间相关性。
为了解决上述两大挑战,我们为弱监督视频异常检测(WSVAD)提出了一个基于CLIP的多尺度实例学习(CMSIL)框架,如图2所示。可以看到,多尺度实例学习分支(红色虚线框)利用基于Transformer的网络构建了一个多尺度时间特征金字塔,以学习不同时间尺度上的异常模式。这种详细且分层的方法同时考虑了长期和短期的异常实例,降低了错误选择异常实例的可能性。此外,本文提出了一个问题:是否有可用的先验知识来指导模型训练,从而防止模型偏向于视频中的简单背景片段?一个有望解决问题的方案是生成和利用伪异常标签,这些标签为片段级别的疑似异常标签,而不是仅依赖视频级别的标签来监督训练过程。因此,我们很自然地转向利用视觉-语言预训练模型CLIP[7]的强大零样本能力,为模型训练生成伪异常标签作为指导。具体来说,在视觉-语言分支(蓝色虚线框)中,我们冻结CLIP的编码器,并使用基于提示的推理[8]进行帧级分类,以识别疑似异常,随后为视频片段生成伪标签。此外,由于生成的伪标签可能不准确且存在固有的类别不平衡问题,我们引入了伪标签集成和对比表示学习来进一步提升我们的方法。简而言之,我们的主要贡献如下:
- 我们设计了一种基于多实例学习(MIL)的多尺度实例学习方法,用于跨不同时间感受野识别异常实例,该方法同时考虑了长期和短期的异常情况。
- 我们通过利用视觉语言预训练模型CLIP的集成知识先验来促进WSVAD。
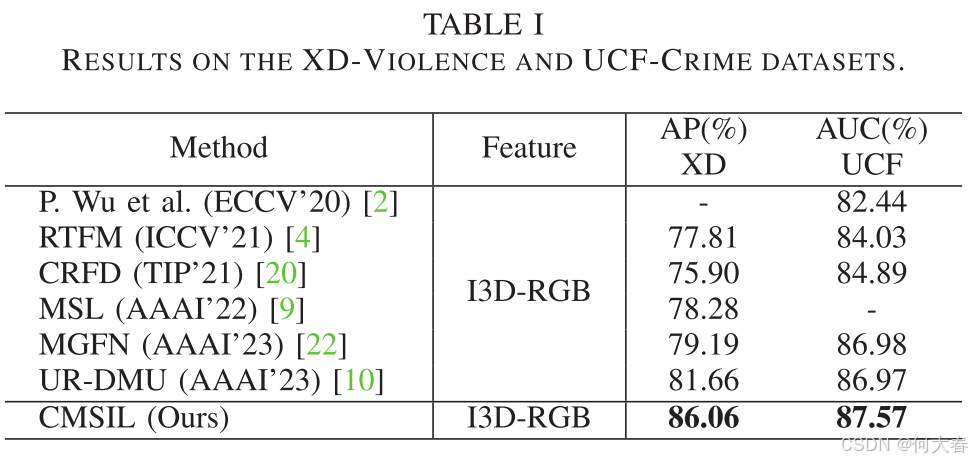
- 我们在两个具有挑战性的数据集上进行了广泛的实验。结果表明,所提出的方法优于几种最先进的方法。
II. RELATED WORKS
弱监督视频异常检测因其能有效降低标注成本而备受关注。Sultani等人[1]首次提出了一种基于多实例学习(MIL)的视频异常检测方法。随后的基于MIL的工作[3]-[5]、[9]、[10]在此基础上进行了进一步的改进。AR-Net[3]引入了动态MIL损失和中心损失,以学习更具区分性的特征。RTFM[4]提出了一种特征幅度学习函数,以有效识别正例。MSL[9]设计了一种多序列学习策略。最近,UMIL[5]提出了一个无偏MIL框架,用于平衡异常特征的学习。UR-DMU[10]则提出了一个双记忆单元,用于同时学习正常数据的表示和异常的区分性特征。然而,这些基于MIL的方法存在固有的缺陷,因为它们将每个实例视为独立的优化单元,忽略了相邻片段之间的时间相关性。相比之下,我们利用特征金字塔来学习不同时间尺度上的异常模式,这有助于模型有效地捕捉短期和长期的异常事件。
视觉-语言提示学习已成为视频领域的一种新型训练范式。通过采用适当的文本提示模板,并将其输入到预训练的视觉-语言模型(如CLIP[7])中,可以将特定任务转化为小样本学习或零样本学习场景。Ju等人[8]引入了提示学习,以高效地完成文本-视频检索和动作定位等视频理解任务。最近,一些工作[5]、[11]开始探索CLIP在视频异常检测(VAD)领域的潜力。这些方法利用CLIP中的视觉特征来高效地提取具有区分性的表示。然而,这些方法并未充分利用文本提示来理解异常的特定语义,导致对异常语义的把握不足,并忽略了异常之间的差异。在本工作中,我们深入探索了将CLIP作为先验异常知识库,用于模型训练指导的可能性。
III. PROPOSED METHOD
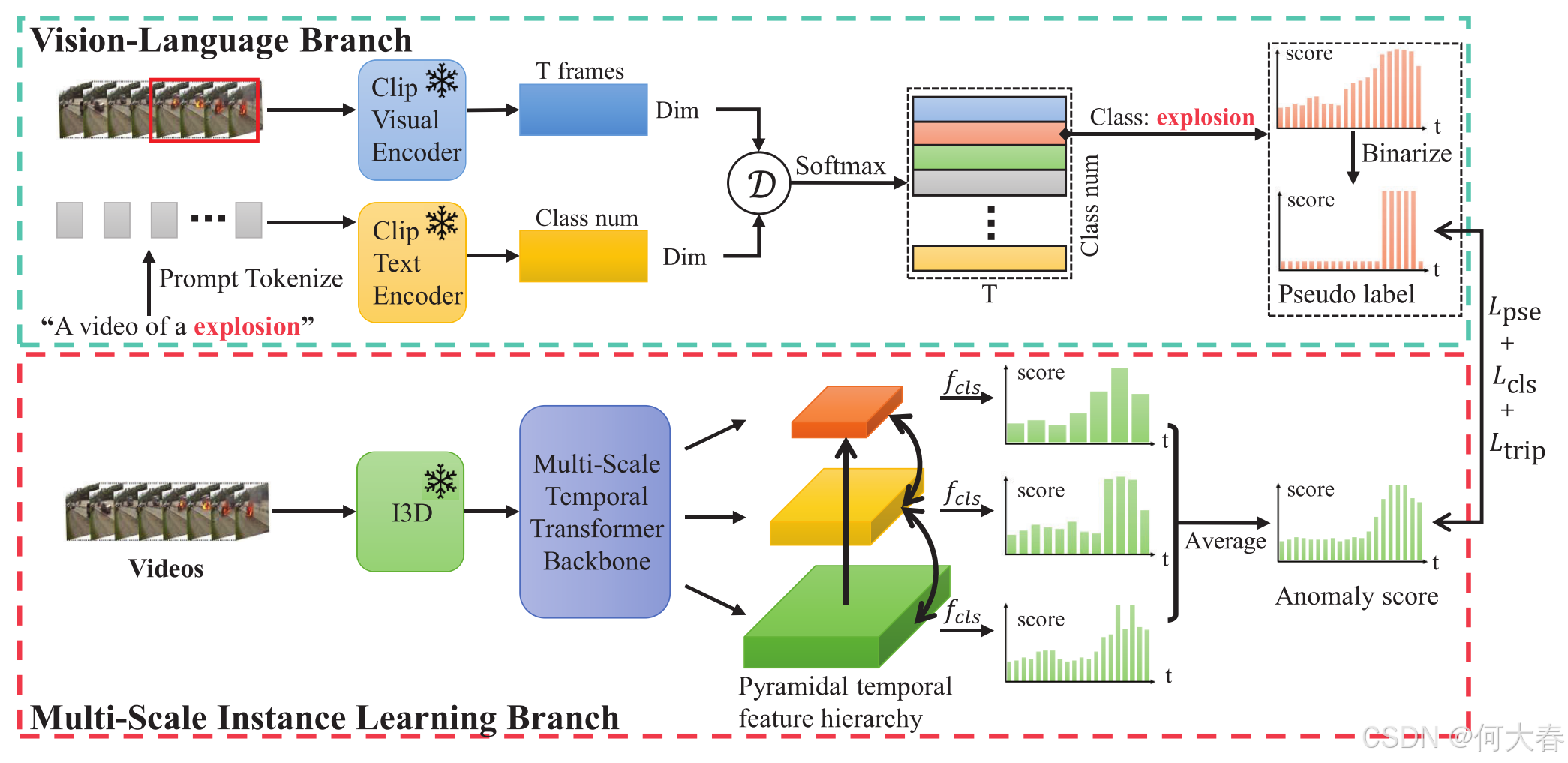
图2. 整体框架。视觉-语言分支负责生成伪标签,以直接监督模型训练。多尺度实例学习分支捕捉多分辨率的时间依赖性,并通过计算每个金字塔层级所得分数的平均值来预测异常分数。通过这两个分支的协同工作,模型能够表现得更好。
A. Preliminaries
Problem Formulation.在弱监督视频异常检测(WSVAD)中,每个训练视频都被标注了一个二进制异常标签y ∈ {0, 1}(即正常或异常),并被分割成不相交的片段。假设视频 v i v_i vi被分割成 t i t_i ti个不重叠的片段,这些片段包含连续的帧,然后我们使用预训练的I3D[12]时空特征提取器(如常见做法[1]-[5]、[9]所示)来提取片段特征。我们将视频vi的片段特征排列成 x i ∈ R t i × d x_i ∈ \mathbb{R}^{t_i×d} xi∈Rti×d的形式,其中d是特征的维度。接下来,我们为每个片段学习一个异常得分函数 f θ ( x i ) f_θ(x_i) fθ(xi),其值域为0到1。
Framework Overview.整体框架(参见图2)包含视觉-语言(VL)分支(第三节B部分)和多尺度实例学习(MSIL)分支(第三节C部分)。VL分支首先通过基于提示的推理生成一组片段级的伪标签。随后,MSIL分支在生成的伪标签的指导下,学习不同时间尺度上的异常模式。
B. CLIP-Driven Pseudo Label Generation
Pseudo Label Generation.在弱监督视频异常检测(WSVAD)中,视频级别的标注仅为模型学习提供了粗粒度的监督信号,这可能导致模型过于关注具有简单上下文的异常片段,从而引发错误的预测[5]。为了解决这一问题,我们的核心见解是生成细粒度的伪标签来指导模型训练。如何以低成本获得高质量的伪标签成为了一个关键问题。最近,像CLIP[7]这样的视觉-语言预训练模型在对齐视觉和语言表示方面展现出了卓越的能力。通过利用CLIP这一强大的对齐能力,我们可以提供适当的文本提示来查询潜在的异常行为片段。查询结果能够为模型训练提供片段级别的伪标签进行监督。
具体来说,给定一个包含C个类别的目标数据集,我们利用CLIP将提示(即“一个[CLS]的视频”)进行分词,并输入到文本编码器中以生成每个类别的类别嵌入。然后,我们获得类别嵌入集合 { f c t e x t } c = 1 C \{f^{text}_c\}^C_{c=1} {fctext}c=1C,其中c表示嵌入所编码的类别。同时,对于每个视频帧,我们使用 f i m g f^{img} fimg来表示由图像编码器提取的视觉特征。接着,我们计算每个帧属于类别c的概率,计算方式为:
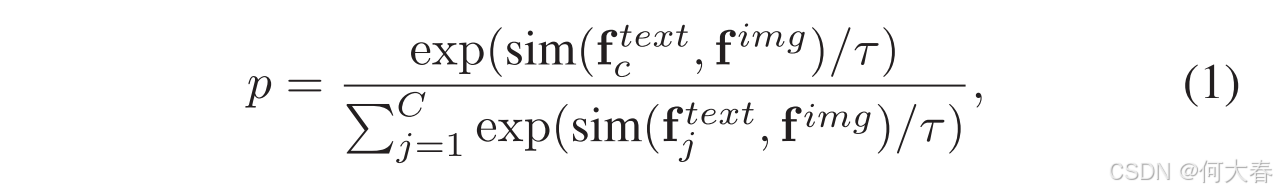
其中, τ τ τ 是CLIP学习到的温度参数,sim(·) 表示余弦相似度。接下来,为了获得视频vi的片段级伪标签,该视频由ti个片段组成,我们通过公式(1)计算每个片段内所有帧对于提示类别c的概率,然后选择这些帧中的最高分数来代表该片段的分数。由此,视频 v i v_i vi的片段级伪标签表示为 P ′ ∈ R t i P' ∈ \mathbb{R}^{t_i} P′∈Rti。
CLIP提供了多种视觉模型,如ResNet-50/101[13]、ViT-B[14]等。我们注意到,采用不同视觉架构的CLIP模型在类别准确性方面表现出偏差,如图3所示。受这一发现的启发,我们引入了一种简洁的伪标签集成策略,旨在提高伪标签的准确性。具体来说,对于使用不同视觉架构的 N N N个CLIP模型,我们运行它们,通过公式(1)生成多个伪标签,表示为 { P 1 ′ , P 2 ′ , . . . , P N ′ } \{\mathbf{P}_1^{\prime},\mathbf{P}_2^{\prime},...,\mathbf{P}_N^{\prime}\} {P1′,P2′,...,PN′}。然后,我们计算这些伪标签的平均值,形成增强的伪标签,记作 P = ∑ i = 1 N P i ′ / N \mathbf{P}=\sum_{i=1}^N\mathbf{P}_i^{\prime}/N P=∑i=1NPi′/N。我们采用这一策略的直觉在于,减轻单个模型固有的偏差,并提高伪标签的准确性。一旦获得增强的伪标签 P \mathbf{P} P,我们就通过设定一个阈值(简单设为0.5)将其二值化,以监督后续的训练过程。
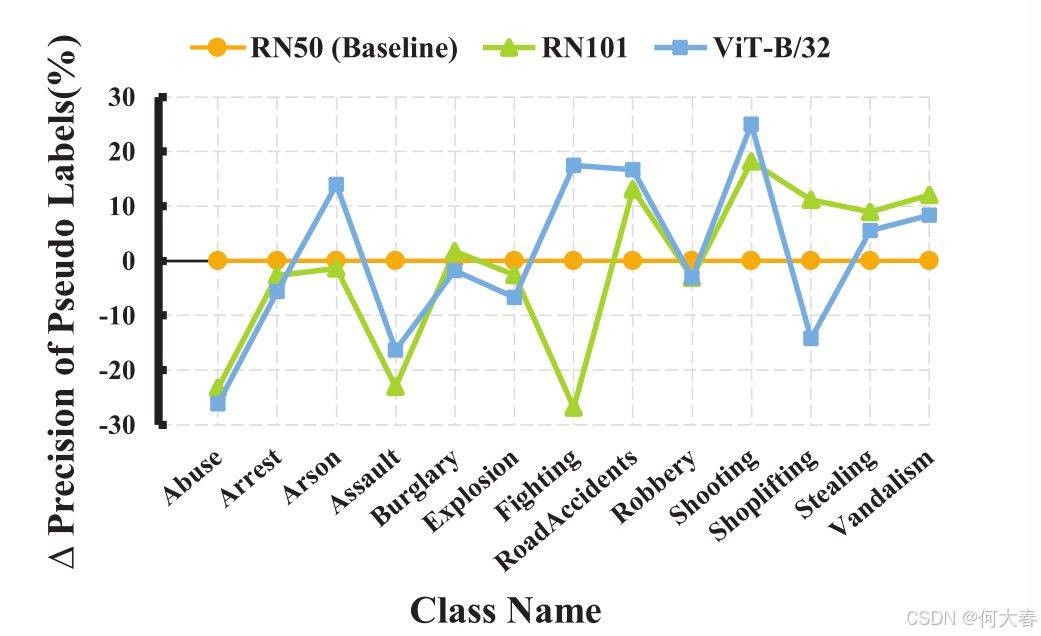
图3. 采用不同视觉架构的CLIP模型在UCF-Crime数据集[1]上展现出不同的偏好。我们为每个视觉编码器计算了类别伪标签的精确度,并展示了它们之间的性能差距(Δ)。
C. Multi-Scale Instance Learning
Multi-Scale Temporal Feature Pyramid.异常事件的持续时间差异很大,可能持续一个或多个连续片段。这要求我们能够从不同的时间尺度上检测异常。为了实现这一点,我们采用了ActionFormer [15]来生成多尺度时间特征金字塔,通过该金字塔,我们可以捕获不同时间尺度上的异常。
对于从 v i v_i vi中提取的片段特征矩阵 x i ∈ R t i × d x_i ∈ \mathbb{R}^{{t_i}×d} xi∈Rti×d,我们使其大小与视频长度无关,并且像通常的实践[1]、[3]、[4]、[9]一样,使 t i t_i ti为预定义值T。如果视频包含的片段少于T个,我们将用零填充。否则,我们对视频进行线性下采样以满足要求。然后我们将 x i ∈ R T × d x_i ∈ \mathbb{R}^{T×d} xi∈RT×d输入ActionFormer学习多尺度时间特征表示:
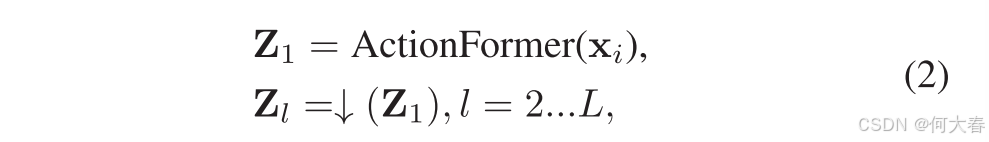
其中, Z 1 ∈ R T × F Z_1 ∈ \mathbb{R}^{T×F} Z1∈RT×F 表示第一层的特征矩阵; Z l ∈ R T l × F Z_l ∈ \mathbb{R}^{T_l×F} Zl∈RTl×F 表示第l层的特征矩阵。↓(·) 表示下采样操作符, T / T l T/T_l T/Tl 是下采样比例。通过这种方式,我们获得了包含L个尺度的时间特征金字塔 Z = Z 1 , Z 2 , . . . , Z L Z = {Z_1, Z_2, ..., Z_L} Z=Z1,Z2,...,ZL。
Multi-Scale Instance Learning.时间特征金字塔Z涵盖了从低级到高级的一系列语义信息。这使得我们能够同时从短期和长期的片段中学习,并捕获不同时间尺度上的异常实例。在我们的方法中,采用了多实例学习(MIL)来独立预测每个金字塔层级上最异常的实例。当 L = 1 L=1 L=1时,我们的多尺度多实例学习(MSIL)退化为标准的多实例学习(MIL)。
一旦获得时间特征金字塔 Z Z Z,我们就应用一个轻量级的分类头 f c l s f_{cls} fcls来获取金字塔每一层上的实例级异常分数。形式上,对于特征金字塔 Z Z Z,分类头 f c l s f_{cls} fcls会检查金字塔上所有 L L L层中的每一个时刻 t t t,并预测每个时刻 t t t上异常实例的概率。这可以表示为:
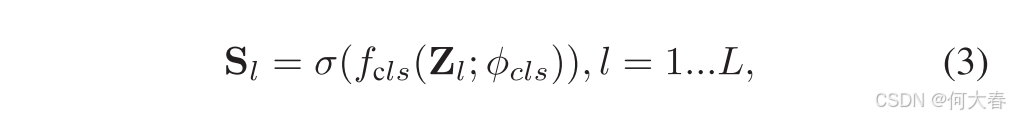
其中, f c l s f_\mathrm{cls} fcls 是通过三层一维卷积实现的,卷积核大小为3,前两层使用层归一化(Layer Normalization),并使用ReLU[16]作为激活函数; ϕ c l s \phi_{cls} ϕcls 表示可学习的参数; σ \sigma σ 选择sigmoid激活函数。得到的 S l ∈ R T l \mathbf{S}_l\in\mathbb{R}^{T_l} Sl∈RTl 表示在每个层级上独立做出的实例级预测。然后,实例序列直接由之前生成的伪标签P进行监督。需要注意的是,伪标签也需要通过下采样算子与每个金字塔层级的时刻进行对齐:
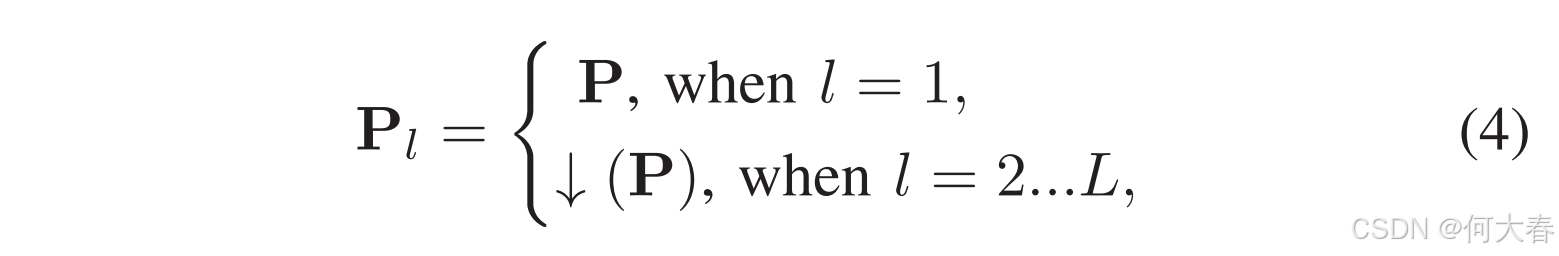
其中,
P
l
∈
R
T
l
P_l ∈ \mathbb{R}^{T_l}
Pl∈RTl 表示每个层级的实例级伪标签,↓(·) 表示下采样操作符。当每个层级都有实例级伪标签时,我们将弱监督视频异常检测(WSVAD)视为一个监督学习问题,并使用焦点损失(focal loss)[17]进行训练。这可以表示为:
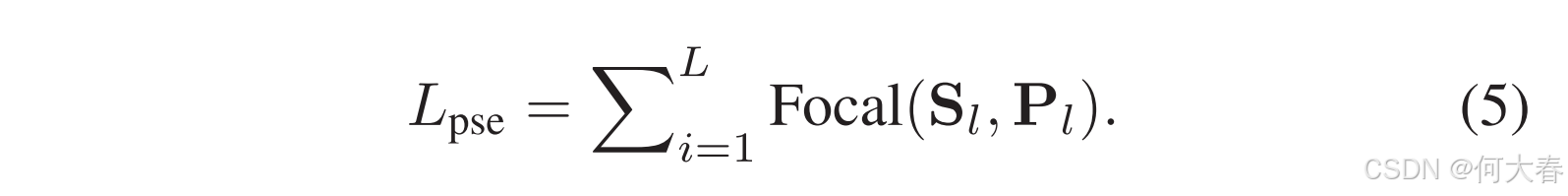
焦点损失(focal loss)缓解了数据固有的不平衡问题,特别是在异常检测中,正样本的数量明显少于负样本。
然而, L p s e \mathcal{L}_{pse} Lpse本身在区分正常模式和异常模式方面并不足够鲁棒。由于生成的伪标签可能存在波动和不准确,如果没有适当的自我纠正机制,模型在后续的训练阶段将会受到高置信度的错误伪标签的监督。为了缓解这个问题,我们引入了视频分类损失( L c l s \mathcal{L}_{cls} Lcls)和三重损失( L t r i p \mathcal{L}_{trip} Ltrip)。
L c l s L_\mathrm{cls} Lcls 是一个视频级分类损失,它聚合了属于同一类别的实例。为了获得视频级预测,我们采用了前 k k k项均值策略:对于由 t i t_i ti个片段组成的视频 v i v_i vi,我们取 k = ⌈ t i α ⌉ k=\lceil\frac{t_i}{\alpha}\rceil k=⌈αti⌉个异常分数最大的项,并计算它们的均值作为 s i s_i si,这给出了视频 v i v_i vi的视频级异常分数。我们采用这一策略的初衷是考虑到视频时长的多样性,而不是像以往的工作[1]、[9]、[10]那样采用固定的 k k k值。在这个过程中, α α α是一个超参数, L c l s \mathcal{L}_{cls} Lcls以二元交叉熵(BCE)的形式计算:
对于三重损失 L t r i p \mathcal{L}_{trip} Ltrip,我们采用了[18]中定义的形式。它可以通过对比表示学习来精炼特征表示,从而获得更具区分性的特征分布。在我们的情况下, L t r i p \mathcal{L}_{trip} Ltrip被定制为如下形式,以分离异常和正常的特征嵌入:
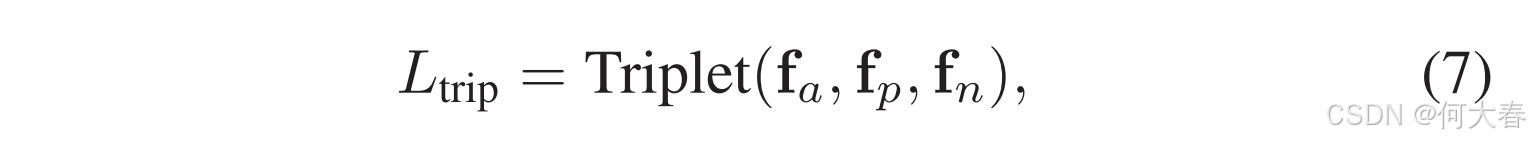
其中, f a f_a fa(锚点)是基于预测分数 S l S_l Sl所选实例的平均特征。同样地, f p f_p fp(正例)是基于伪标签 P l P_l Pl所选实例的平均特征,而 f n f_n fn(负例)表示正常视频的平均特征。
由于总损失函数可以被视为多个不同任务的总和,因此我们在[19]中使用多任务学习方法来平衡它们:
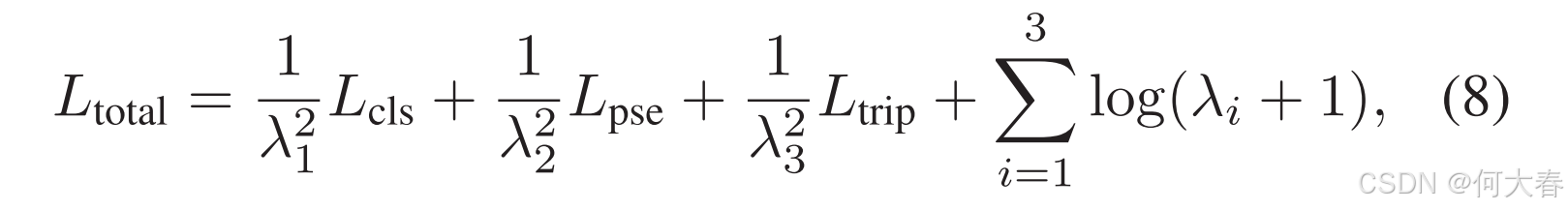
其中 λ i λ_i λi, i ∈ 1 , 2 , 3 i ∈{1,2,3} i∈1,2,3,是可学习的损失权重。
IV. EXPERMENTS
V. CONCLUSION
我们提出了一个名为CMSIL的双分支框架,用于弱监督视频异常检测。为了防止模型仅关注具有简单上下文的异常片段,我们引入了VL分支,利用CLIP模型进行语义指导。同时,我们设计了MSIL分支,利用特征金字塔来学习不同时间尺度上的异常模式,这有助于模型有效地捕捉短期和长期异常。实验结果表明,与最先进的方法相比,CMSIL具有优越性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









