





原文链接:https://gist.github.com/mingfeima/e08310d7e7bb9ae2a693adecf2d8a916
通常,性能优化的第一步是进行性能分析,例如识别工作负载的性能热点。本要点介绍了 PyTorch 上性能分析的基本知识,你将可以知道:
- 如何找到瓶颈算子?
- 如何追踪某个的源文件?
- 如何识别线程问题?
- 如何知道某个算子是否能够高效运行?
本教程以我最近的一个项目 pssp-transformer 为例,指导您完成 PyTorch CPU 性能优化的路径。重点将放在第 1 部分和第 2 部分。
PyTorch Autograd Profiler
注意:最新的PyTorch 2.0版本中将该分析器功能独立出来,可以直接使用 torch.profiler 来调用分析器。
PyTorch 在 autgrad 模块中有一个内置的分析器,又名 PyTorch autograd 分析器。使用方法相当简单,你可以告诉 torch.autograd 引擎以以下方式记录每个运算符的执行时间:
with torch.autograd.profiler.profile() as prof:
output = model(input)
print(prof.key_averages().table(sort_by="self_cpu_time_total"))代码片段在这里,torch.autograd.profiler 将记录任何 PyTorch 运算符(包括在 PyTorch 中注册为扩展的外部运算符,例如来自 detector2 的 _ROIAlign),但不会记录 PyTorch 的外部运算符,例如 numpy。对于 CUDA 分析,你需要提供参数 use_cuda=True。
运行分析器后,你将对哪些运算符是热点有一个基本的了解。对于 pssp-transformer 模型,可以获得类似以下内容:
--------------------------------------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls
--------------------------------------- --------------- --------------- --------------- --------------- --------------- ---------------
bmm 14.91% 35.895s 30.11% 72.485s 3.634ms 19944
div 12.09% 29.100s 24.52% 59.034s 1.076ms 54846
copy_ 11.07% 26.636s 13.41% 32.290s 231.292us 139608
mm 10.76% 25.891s 21.65% 52.112s 1.254ms 41550
mul 8.92% 21.477s 17.93% 43.157s 1.770ms 24376
bernoulli_ 7.35% 17.687s 14.72% 35.421s 3.996ms 8864
native_layer_norm_backward 6.69% 16.103s 13.39% 32.241s 5.820ms 5540
_softmax_backward_data 3.80% 9.145s 7.64% 18.379s 5.529ms 3324
_softmax 3.42% 8.228s 6.85% 16.491s 4.961ms 3324
masked_fill_ 2.64% 6.362s 5.26% 12.671s 1.906ms 6648
mkldnn_convolution_backward_weights 2.52% 6.061s 2.53% 6.096s 2.751ms 2216
mkldnn_convolution 2.49% 5.999s 5.00% 12.034s 2.715ms 4432
mkldnn_convolution_backward_input 1.96% 4.728s 1.98% 4.757s 2.147ms 2216
embedding_dense_backward 1.64% 3.953s 3.30% 7.949s 7.174ms 1108
add_ 1.32% 3.169s 2.69% 6.465s 40.992us 157716
div_ 1.31% 3.152s 4.00% 9.628s 724.096us 13296
sum 1.18% 2.847s 2.44% 5.863s 407.041us 14404
add 1.13% 2.724s 2.31% 5.565s 295.455us 18836
empty 0.50% 1.214s 0.59% 1.414s 7.353us 192240
mul_ 0.45% 1.084s 1.08% 2.597s 25.472us 101936该表本身非常直观。乍一看,bmm() 似乎是造成 CPU 性能不佳的原因。但实际上,还需要考虑其他一些因素:
- 每个操作符的输入配置不同:工作负载可能会多次调用 bmm(),基本上我们想知道:输入张量大小?因为 4K x 4K 可能运行效率高,而 4K x 13 则相反。
- 算子效率:比如这个算子是否运行效率低下?
对于第一个问题,我们需要找到此运算符在此工作负载中的使用位置 - 对于 bmm(),一个简单的 grep 就可以完成这项工作。但是对于重载运算符(例如 div)怎么办?这是 Python 代码中的简单除法 (/)。在这里,我们将需要 Python 级分析工具,例如第 2 部分中的 cprofile。
对于第二个问题,我们需要 vtune 来收集性能指标,例如 CPI、带宽等。此外,具有相关领域知识也将是一个很大的优势,因为我之前优化过 torch.bmm(),我知道基本上我们对 bmm() 无能为力。但 native_layer_norm_backward 是一个顺序内核。
cProfile Profiler
cProfile 是 Python 内置的分析器,这意味着 Python 中的任何内容都将被记录。用法:
python -m cProfile -o output.pstats <your_script.py> arg1 arg2 …获得 output.pstats 文件后,你可以使用一个非常酷的工具将结果转换为人可读的图像 - gprof2dot
pip install graphviz
pip install gprof2dot
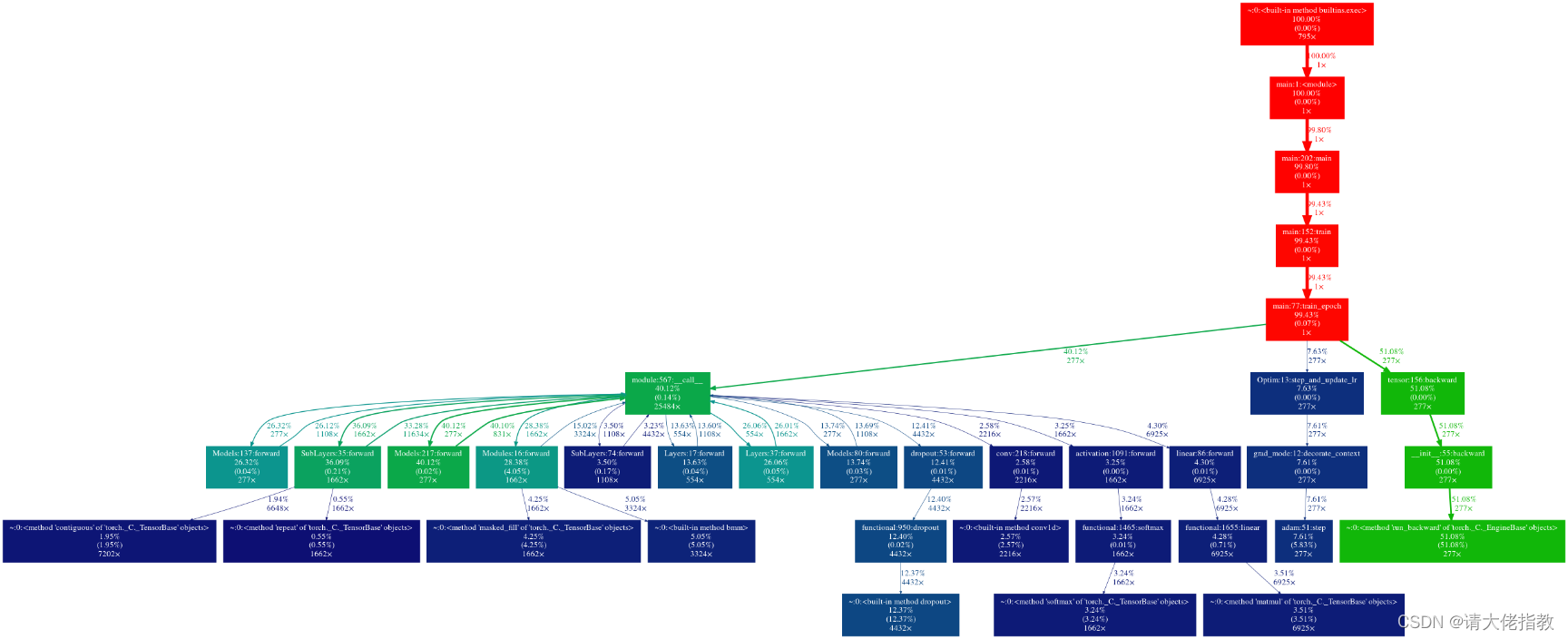
gprof2dot -f pstats output.pstats | dot -Tpng -o output.png在 pssp-transformer 上,你将可以获得如 z1.png 所示的树,你可以在其中获取源代码跟踪。因此,找到输入配置将非常容易。
VTune
vtune 是用于 CPU 性能分析的终极工具,类似于 GPU 上的 nvprof。你可以使用 GUI 以及脚本启动 vtune。我在另一个 gist 中列出了常用的收集脚本。
通过收集 openmp 线程指标,可以随时直接看到有多少个活动线程,从而识别oversubcription 问题。
通常,当我决定针对输入大小优化特定运算符时,我会编写一个微基准测试来输入到 vtune 中。vtune 能够提供许多有用的信息,这是一个超出本文讨论范围的庞大话题,同时需要大量的专业知识。
最简单的是,vtune 能够在指令级别收集性能指标。通常 CPI(每条指令的周期数)应低于 0.5 或 1。异常高的 CPI 可能来自:a)慢指令(例如整数除法);b)关键路径上的函数调用未内联;c)内存访问;d)大对象的构造/解构(例如 TensorImpl,你不应该经常在 PyTorch 上看到这种情况,它开销很大)等。
Closing
对于工作负载 pssp-transformer,经过上面列出的一系列分析后,热点将是:
- ScaledDotProductAtention - 一旦检查输入、权重张量大小,很容易发现内存占用太大,并且连续运算符(bmm、div、softmax)每次都会刷新缓存。解决方案是以缓存友好的方式将这些运算符融合在一起。
- LayerNorm 后向是一个顺序内核。解决方案是Optimize LayerNorm performance on CPU both forward and backward.















 3855
3855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









