







文章目录
Matrix Factorization
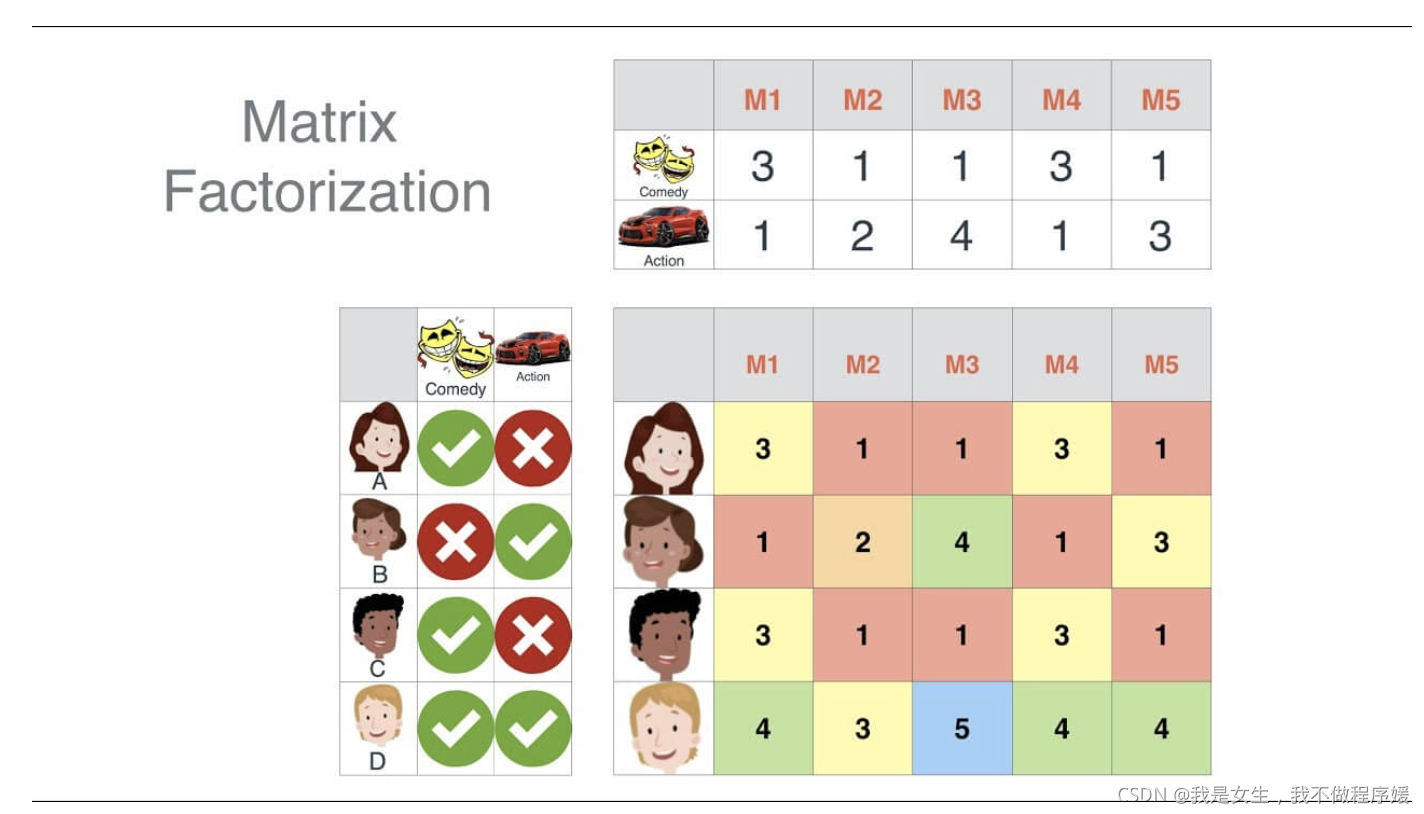
以电影为例,电影可能具有一些隐藏因子:演员、题材、主题、年代……,而用户针对这些隐因子有偏好特征属性,为了便于理解,我们假设隐因子数量 k 是 2,分别代表着喜剧片和动作片两种题材,矩阵分解后的两个小矩阵,分布代表着电影对这两种题材的符合程度以及用户对这两种题材的偏好程度,如下图:
encoder-decoder | autoencoder
Autoencoder:自编码器,用于无监督学习
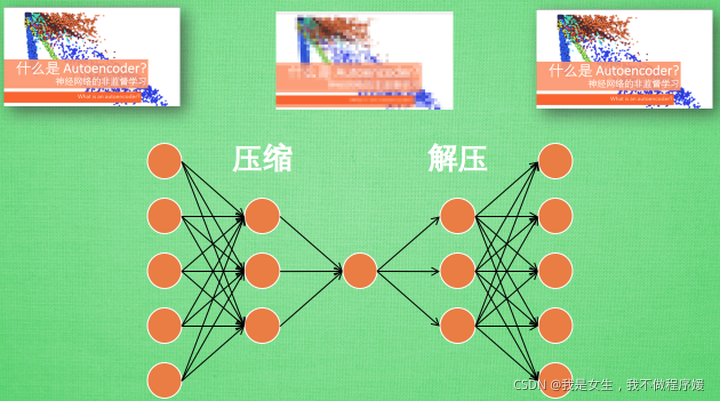
autoencoder包括了压缩(encoder)和解压(decoder)
这个Encoder就是很多个隐层网络的网络结构,输入一张图片后会输出降维以后的结果,保留的是原始数据最关键的部分。降为后再进行神经网络训练可以使输入数据量大大减小,只需要训练一个小的神经网络。
Decoder也是网络结构,输入降维的图片会输出原来的图片。
自始至终我们只用到了原始图片,而没有其标签,因此autodecoder是一种无监督的训练方法。
注:单独训练encoder和decoder,都是无法做到的。将它们连接在一起后才可以得到encoder和decoder。
在basic autoencoder的基础上,还有denoising encoder, convolutional autoencoder等等改进的方法。
在文字上的例子:搜索引擎,用query搜索document
把每一个document和query用一个vector 来描述,计算每一个query和document的相似度,看query和哪个document的相似度比较高,那它就是搜索的结果。
假设有2000个词,将这两千个词降维到2维。每一个文章都是2维空间上的一个点。同样将一个query也降维到2维空间,然后计算query和那些点的相似度。
最后用decoder讲2维点还原为document即为与query相同的同类文章。
Word2Vec
文本embedding的方法,包括CBOW(由上下文预测当前值)和Skip-Gram(由当前值预测上下文)两种训练模型。
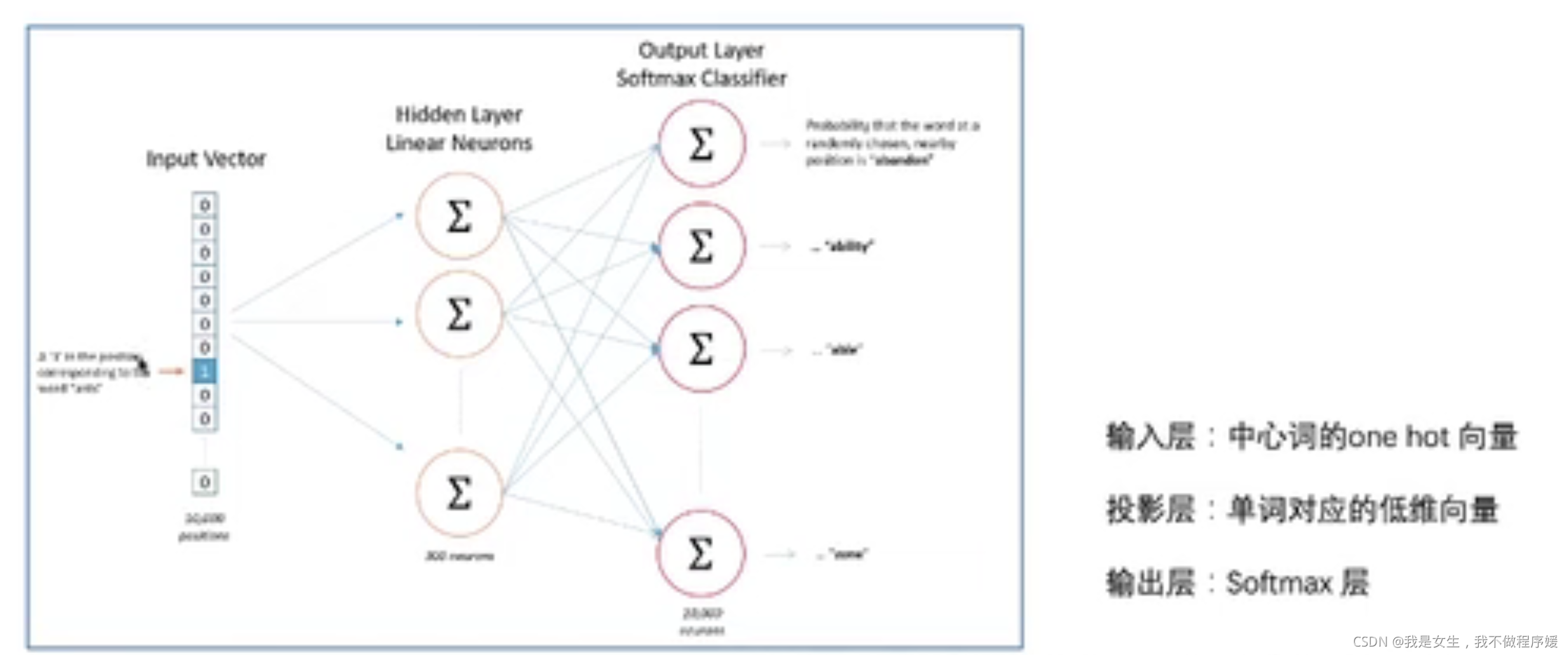
最终得到的隐含层系数矩阵W即为最终的embedding方式。
提高速度的优化方式:
- Negative Sample(负采样)
- Hierarchical Softmax

Deepwalk
将Word2vec用于图算法。
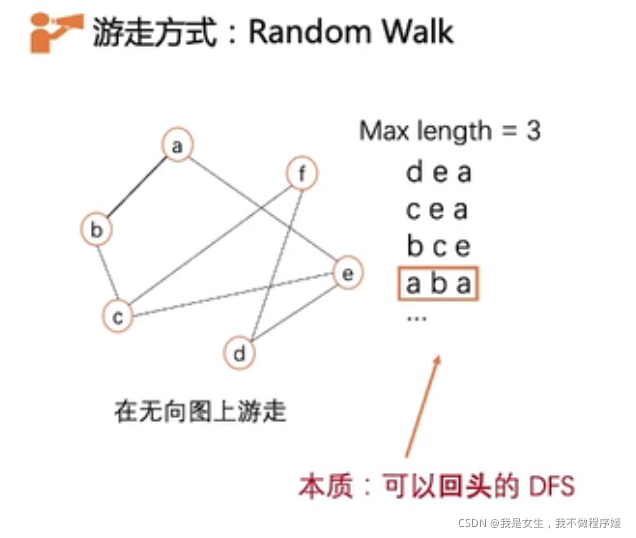
将网络中的路径类比为句子,点类比为Word,则可在图上应用Word2vec进行编码。
训练出的embedding规则会将经常出现在同一条路径(即相邻)的节点编码为相似节点。
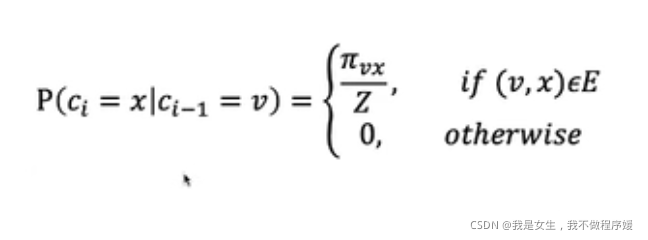
通过调整随机游走产生各条路径的概率(如根据边权重调整概率),可以训练得到更符合网络预期的编码模型。
信息网络相关概念
一阶相似性:两个顶点之间的直接相似度。对于有边连接的每对顶点,该边的权重表示两点之间的一阶相似性,如果两点之间没有边,则一阶相似性为0。
二阶相似性:两点邻域网络结构之间的相似性。数学上,让 p u = { v u 1 , v u 2 . . . v u n } p_u=\{v_{u1},v_{u2}...v_{un}\} pu={vu1,vu2...vun}表示一阶附近与所有其他的顶点,那么 u 和 v 之间的二阶相似性由 p u p_u pu 和 p v p_v pv 之间的相似性来决定。如果没有一个顶点同时和u 与 v 连接,那么其二阶相似性是0。
GNN与GCN
图神经网络(GNN):用多维向量(节点属性)表示图节点,学习过程将节点之间的关系加入节点向量。B站一个通俗易懂的讲解
图卷积神经网络(GCN):改进的GNN。B站一个通俗易懂的讲解
假设图中有N个节点(node),每个节点都有自己的D维特征,这些节点的特征组成一个N×D维的矩阵X,然后各个节点之间的关系也会形成一个N×N维的矩阵A(邻接矩阵)(adjacency matrix)。X和A便是模型的输入。
学习结果:每个节点的embedding中既包含节点属性信息,又包含了关系信息(即相邻接点表示相似)。
GCN的迭代公式为:
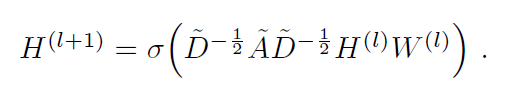
其中H是每一层的特征矩阵,输入层的H即为X;
W是权重矩阵。
交叉熵与相对熵(KL散度)
交叉熵:用来衡量在给定的真实分布P下,使用非真实分布Q所指定的策略消除系统的不确定性所需要付出的努力的大小。
交叉熵=
−
∑
i
=
1
n
p
i
l
o
g
2
q
i
-\sum_{i=1}^np_ilog_2 q_i
−∑i=1npilog2qi
相对熵:又称K-L散度(Kullback-Leibler Divergence):是一种量化两种概率分布P和Q之间差异的方式。
KL(p||q) =
−
∑
i
=
1
n
p
i
l
o
g
2
q
i
−
(
−
∑
i
=
1
n
p
i
l
o
g
2
p
i
)
=
∑
i
=
1
n
p
i
l
o
g
2
p
i
q
i
-\sum_{i=1}^np_ilog_2q_i- (-\sum_{i=1}^np_ilog_2p_i)=\sum_{i=1}^np_ilog_2\frac{p_i}{q_i}
−∑i=1npilog2qi−(−∑i=1npilog2pi)=∑i=1npilog2qipi
性质:1. 非对称性,KL(p||q)≠KL(q||p)
2. 非负性:当且仅当P=Q时,KL(p||q)=0;否则KL(p||q)>0.
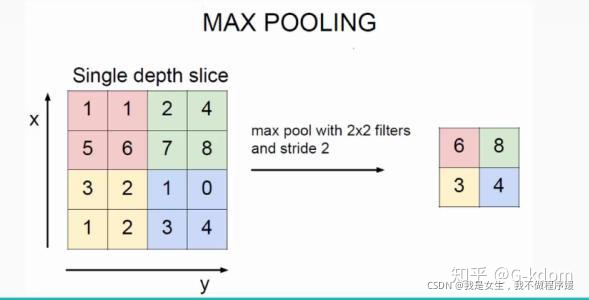
Pooling:池化
池化的本质:降维
- 最大池化(Max pooling):
- 平均池化(Average Pooling):
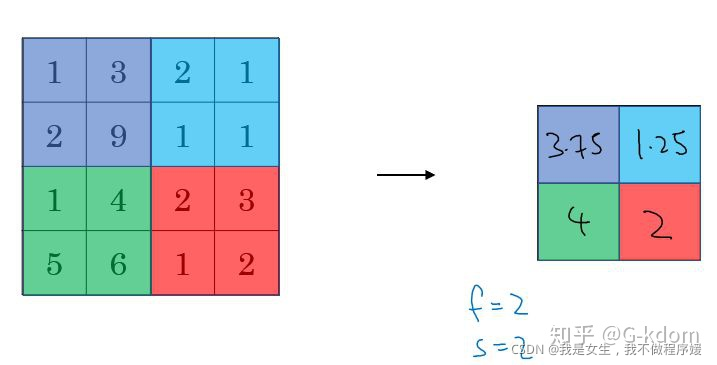
池化实质上是损失部分信息换取运算速度。
graph pooling
graph pooling 就是对图进行降维。
- hard rule
已知图结构,预先规定池化分组

如图,预先规定[1,2,3,5],[4],[6,7]分别进行池化 - Graph coarsening
代表论文:DiffPool
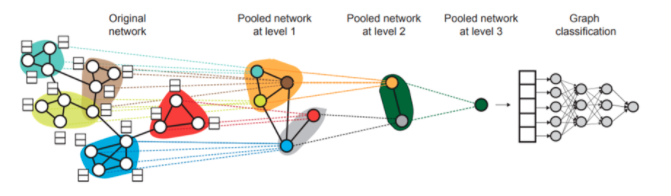
先对节点进行soft clustering,合成super node,再进行coarsening - node selection
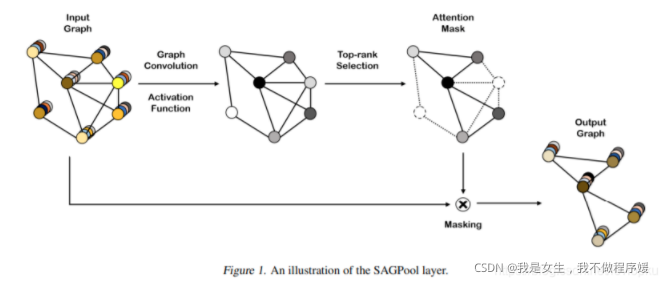
代表论文:self- attention graph pooling
选择一些重要的节点代替原图。
softmax
softmax是一个多分类的激活函数,用于将前一层的输出值转化为概率(三分类问题则输出三个概率),选取概率最大的类别作为分类结果。

因此,softmax的输入输出维度应该一致,如果不一致,可以在softmax之前加入一个全连接层。
全连接层
全连接的核心操作就是矩阵向量乘积
y
=
W
x
y=Wx
y=Wx
本质就是由一个特征空间线性变换到另一个特征空间.














 9669
9669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









