







文章目录

Abstract
已有研究表明,大型语言模型(LLM)在文本的少样本推理中表现excellent,本文证明LLM在表结构的f复杂少样本推理中表现也很competent。
Introduction
已有结构化文本推理方法基于特定的输入输出格式和领域,在实际应用中需要大量语料进行微调才能取得理想效果。
本文希望找到一套通用的、不需要微调的、对表结构没有严格限制的少样本推理模型。
Related works
reasoning over tables: 存在上述缺点
In-context learning with LLMs: GPT-3可以很好地执行少样本学习
Chain of Thoughts Reasoning(CoT):相比传统prompt learning多了一些推理过程模板。
本文没有详细介绍CoT,可以参考原文:论文笔记(2):Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.

Method
任务:基于表格的QA 和 fact vertification
提示文本生成(对应CoT原文中的Chain-of-thought):linearize the table+concatenate it with a few examples

Models:
| LLM | details |
|---|---|
| GPT3(direct) | GPT-3直接预测 |
| GPT3(+CoT) | 结合chain of thoughts |
| GPT3(+CoT-SC) | 结合chain of thoughts和多路径投票策略 |
| Codex | Codex模型 |
Experiment
dataset
question answering: WikiTableQuestions, FetaQA
fact vertification: TabFact, FEVEROUS
作者对每个数据集进行了few-shot的注释,其中direct模型的QA作为prompt(图左),CoT版本模型的Q+Explaination+A作为prompt(图右)。


baselines
Pre-trained Encoder-Decoder Model : against T5(2020) and BART(2020)
Pre-trained Table Understanding Model: TAPAS (2020), TABERT (2020), and TAPEX(2021)
Neural Symbolic Model: LogicFactChecker (2020), Neural-Symbolic Machine (2018)
results
main results
LLMs are not optimized, but highly competent, especially when combined with CoT.

LLM 表现不是最好的,但与表结构推理模型相差不大,且与COT结合后表现更好。
analysis
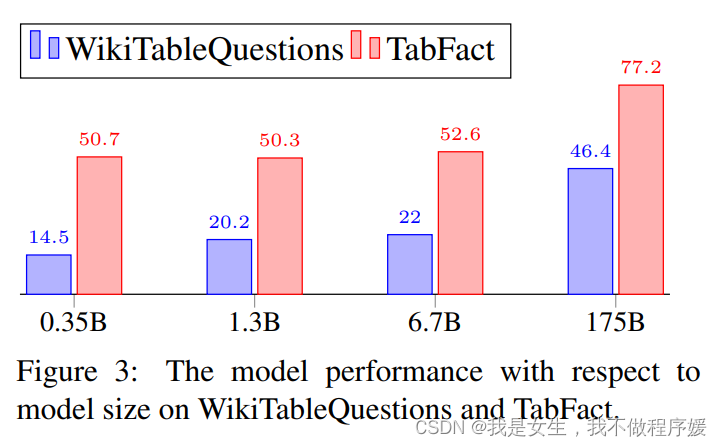
Impact of Number of Shots : not sensitive, 1-shot 到2-shot有性能提升,但再增加则鲜有提升。
Quality Evaluation of Reasoning Chains :人工抽取推理链,证明预测结果是基于正确推理路径而非猜测。
Impact of Table Size:highly sensitive, 预测性能随着表增大单调下降,超过1000 tokens时退化为随机猜测。
Limitation
- 性能非最优
- costly,只有在大size下表现才较好。














 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









