







本文主要对于医学影像上的图像分割模型进行调研以及经验总结,以基础框架进行分类:
- mamba
- transformer
其中以mamba相关的图像分割模型有:VM-Unet,Manba-Unet,BRAU-Net++,MDD-Unet,EGE-Unet,U-Mamba
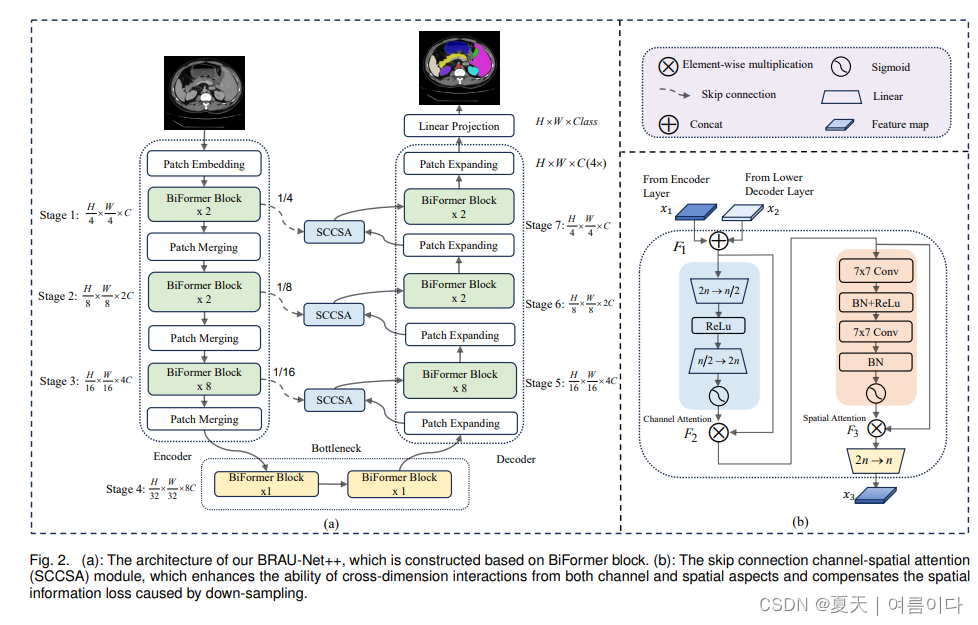
2024.01.01_BRAU-Net++
Paper:BRAU-Net++: U-Shaped Hybrid CNN-Transformer Network for Medical Image Segmentation
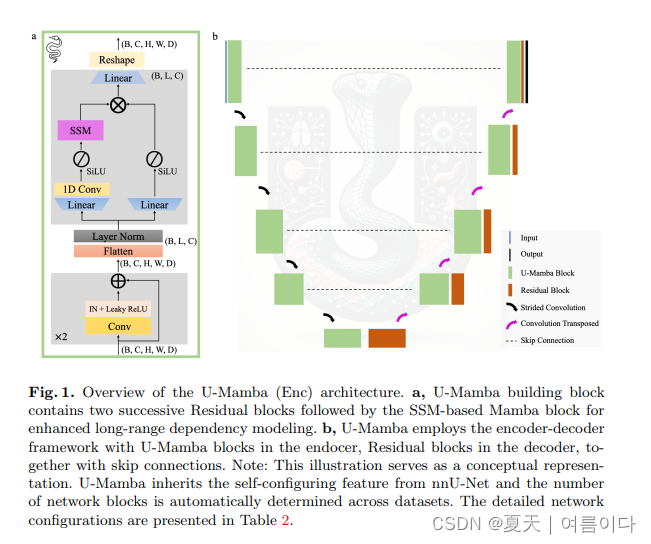
2024.01.09_U-Mamba
Paper:U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
受状态空间序列模型(SSM)这一新的深度序列模型家族的启发,该模型以其处理长序列的强大能力而闻名,论文设计了一个混合 CNN-SSM 模块,它将卷积层的局部特征提取能力与以下能力集成在一起: 用于捕获远程依赖性的 SSM。 此外,U-Mamba 具有自我配置机制,无需人工干预即可自动适应各种数据集。

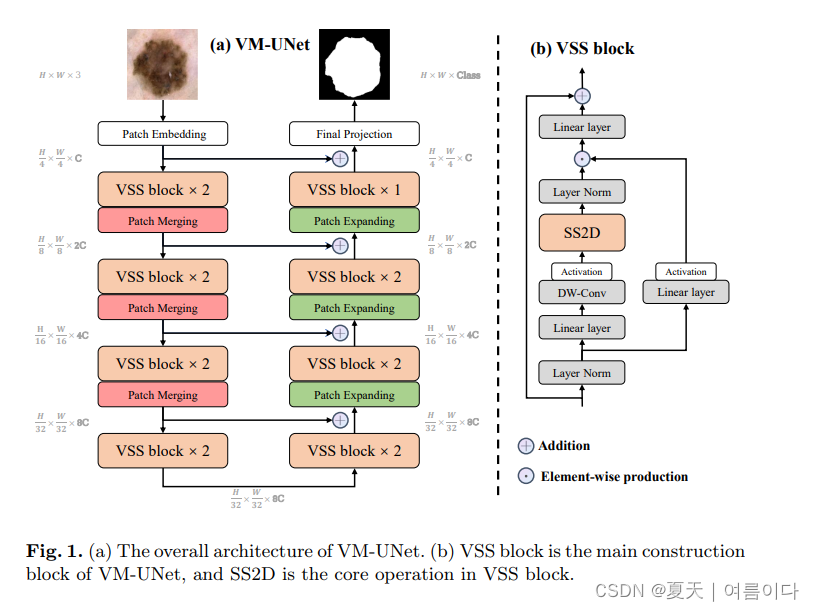
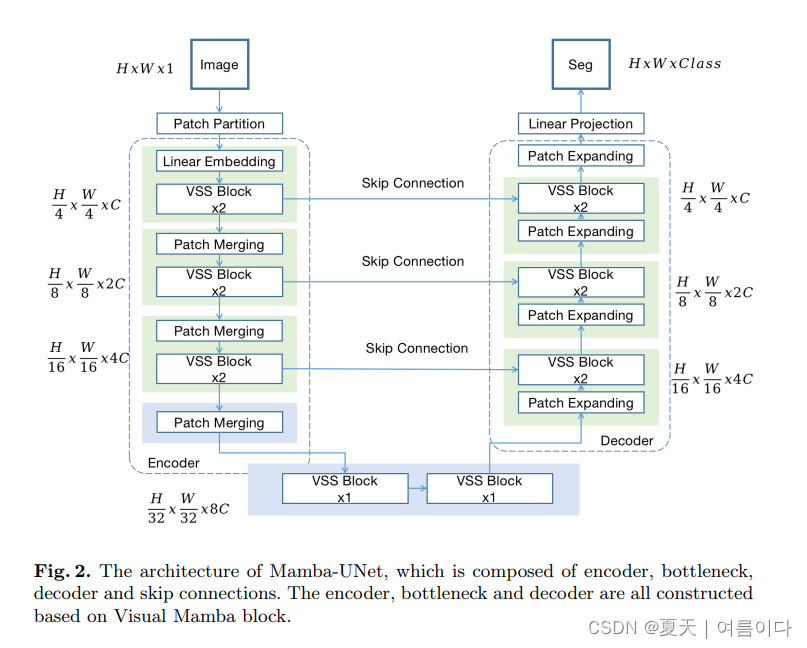
2024.02.04_VM-UNet
Paper:VM-UNet: Vision Mamba UNet for Medical Image Segmentation2402.02491.pdf (arxiv.org)
论文框架包含了:Patch Embedding layer, an encoder, a decoder, a Final Projection layer, and skip connections.
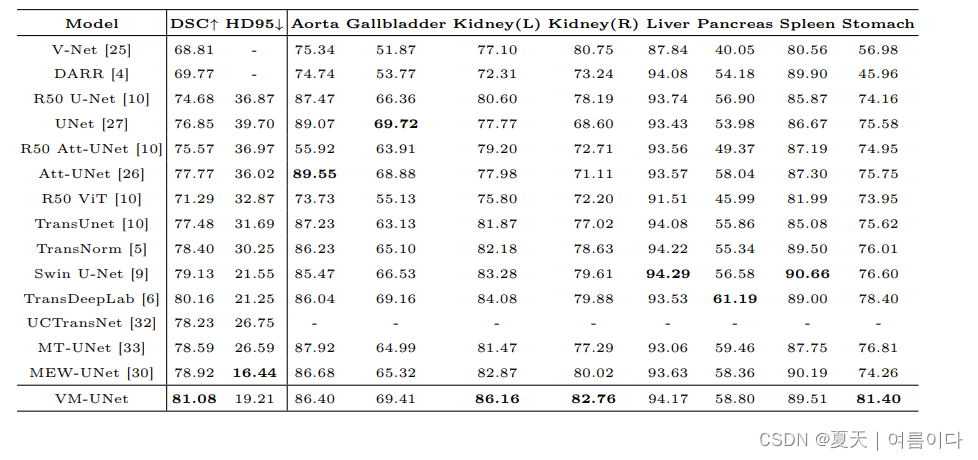
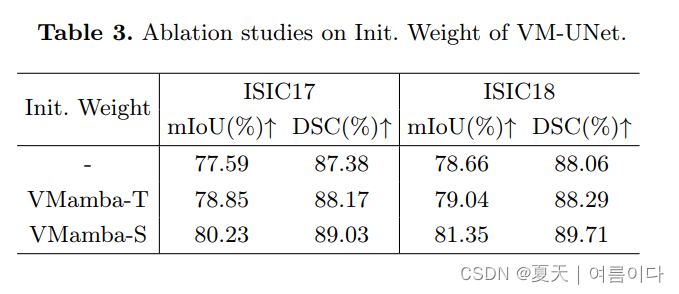
结果
2024.02.05_Swin-UMamba:基于Mamba和ImageNet预训练的医学图像分割模型
Paper:Swin-UMamba: Mamba-based UNet with ImageNet-based pretraining
Code:JiarunLiu/Swin-UMamba: Swin-UMamba: Mamba-based UNet with ImageNet-based pretraining (github.com)
总结
- 相比较于U-Mamba,Swin-UMamba在三种医学图像分割任务指标上可以取得平均3.58%的提升。
- 该篇工作通过实验验证了ImageNet预训练对基于Mamba的医学图像分割模型起到非常重要的作用,在迭代次数不变的情况下最高可为Swin-UMamba带来13.08%的DSC提升。
- 提出了一种变体网络Swin-UMamba,其仅需要相比于U-Mamba不到1/2的网络参数量和约1/3的FLOPs就能够实现与Swin-UMamba相近的性能。

2024.02.07_Mamba-UNet
Paper:Mamba-UNet: UNet-Like Pure Visual Mamba for Medical Image Segmentation2402.05079.pdf (arxiv.org)

在本论文中,简单介绍了之前论文的VSS块,编码器,解码器,Bottleneck & Skip Connetions
在本文中作者认为与典型的视觉转换器不同,VSS 模块了位置嵌入。视觉转换器不同,它没有 MLP 结构、所以就能在相同的深度预算内堆叠更密集的区块。
以transformer为框架的模型:LViT
2023.07.27_LViT
Paper:LViT: Language meets Vision Transformer in Medical Image SegmentationLViT:医学图像分割中的语言与视觉转换器的结合
2206.14718v4.pdf (arxiv.org)
深度学习在医学图像分割等方面得到了广泛的应用。然而,由于数据注释成本过高,无法获得足够的高质量标记数据,现有医学图像分割模型的性能受到限制,提出了一种新的文本增强医学图像分割模型LViT(语言与视觉转换器的结合)。在LViT模型中,结合了医学文本注释来弥补图像数据的质量不足。此外,文本信息可以指导在半监督学习中生成质量提高的伪标签。还提出了一种指数伪标签迭代机制(EPI),以帮助像素级注意力模块(PLAM)在半监督LViT设置中保留局部图像特征。在我们的模型中,LV(语言视觉)损失旨在直接使用文本信息监督未标记图像的训练。为了进行评估,构建了三个包含 X 射线和 CT 图像的多模态医学分割数据集(图像 + 文本)。实验结果表明,所提出的LViT在全监督和半监督环境下均具有优异的分割性能。代码和数据集可在 https://github.com/HUANGLIZI/LViT 上获得。
参考文献
【1】2024.01.18_VMamba: Visual State Space Model2401.10166.pdf (arxiv.org)

















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











