







问题:
给定一个整数数组,判断是否存在重复元素。
如果存在一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
示例 1:
输入: [1,2,3,1]
输出: true
示例 2:
输入: [1,2,3,4]
输出: false
示例 3:
输入: [1,1,1,3,3,4,3,2,4,2]
输出: true
来源:力扣(LeetCode)
思路:
在对数字从小到大排序之后,数组的重复元素一定出现在相邻位置中。
因此,我们可以扫描已排序的数组,每次判断相邻的两个元素是否相等,如果相等则说明存在重复的元素。
解:
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {//1
sort(nums.begin(), nums.end());//2
int n = nums.size();
for (int i = 0; i < n - 1; i++) {
if (nums[i] == nums[i + 1]) {
return true;
}
}
return false;
}
};
/*1:
vector是STL中的容器,需要包含#include<vector>;当预处理器发现#include 指令时,会查看后面的文件名并把文件的内容包含到当前文件中,即替换源文件中的#include指令。
这里是int类型的容器,nums为容器变量,注意这里是对容器变量的引用“&”
*/
/*2:
C++ 中的sort()排序函数用法
sort(first_pointer,first_pointer+n,cmp)
该函数可以给数组,或者链表list、向量排序。
实现原理:sort并不是简单的快速排序,它对普通的快速排序进行了优化,此外,它还结合了插入排序和推排序。系统会根据你的数据形式和数据量自动选择合适的排序方法,这并不是说它每次排序只选择一种方法,它是在一次完整排序中不同的情况选用不同方法,比如给一个数据量较大的数组排序,开始采用快速排序,分段递归,分段之后每一段的数据量达到一个较小值后它就不继续往下递归,而是选择插入排序,如果递归的太深,他会选择推排序。
此函数有3个参数:
参数1:第一个参数是数组的首地址,一般写上数组名就可以,因为数组名是一个指针常量。
参数2:第二个参数相对较好理解,即首地址加上数组的长度n(代表尾地址的下一地址)。
参数3:默认可以不填,如果不填sort会默认按数组升序排序。也就是1,2,3,4排序。也可以自定义一个排序函数,改排序方式为降序什么的,也就是4,3,2,1这样。
使用此函数需先包含:
#include <algorithm>
并且导出命名空间:using namespace std;
*/
纠错1:
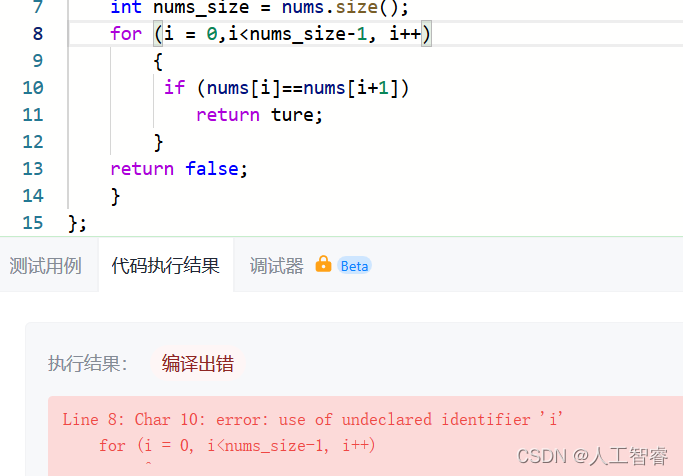
C++循环语句,括号内的参数用分号分隔开
应该为:
for (int i = 0; i < nums_size -1; i++)
{};
而注意sort函数括号内是逗号
实际上在for循环语句中,statement的每个部分都是一个单独的表达式语句。所以它们自然是由分号分隔的。 其部分定义为
for-init-statement;
condition;
expression
即使条件被视为陈述,因为除了所有条件之外,还有一个声明。此外,每个部分都可以包含表达式列表(以逗号分隔)或逗号运算符。因此,区分每个部分的唯一方法是使用分号。
请考虑以下for循环
for ( size_t i = 0, j = std::strlen( s ); i < j; i++, j-- ) std::swap( s[i], s[j] );
如果不使用分号,则很难写出类似的陈述,以便了解每个部分的结束或开始。
至于功能参数,那么你要处理一个列表。在C ++语法中,列表中的项目用逗号分隔,以区别于语句。
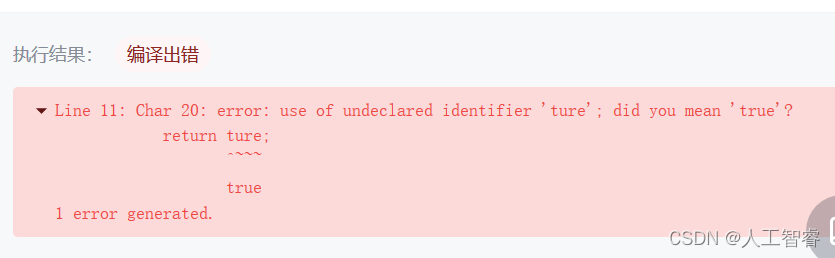
纠错2:
true 错写为 ture ,非常不应该!
 还有一些低级错误不应该犯,比如if中的判断是==而非=!
还有一些低级错误不应该犯,比如if中的判断是==而非=!
哈希表:
几个注意的点
- #include<unordered_set>,利用find() end()做判断
- for (int x : nums)
#include<unordered_set>
using namespace std;
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_set<int> s;
for (int x : nums)
{
if(s.find(x) != s.end())
return true;
s.insert(x);
}
return false;
}
};

















 7409
7409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









