







HBase的安装与配置
注意:先做好hadoop集成配置后再来进行
HBase是Apache的Hadoop项目的子项目。HBase是一个分布式的、面向列的开源数据库。HBase在Hadoop之上提供了类似于Bigtable的能力。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
1、创建用户
分别在四台节点机上创建用户hbase,密码都为123456,uid和gid与hadoop用户的相同,因为Hadoop没设gid,因此是随机分配的,所以先进行查看
(如果做过Hadoop用户的集成之后,可以直接用Hadoop用户去完成)
[root@node1 ~]# cat /etc/group
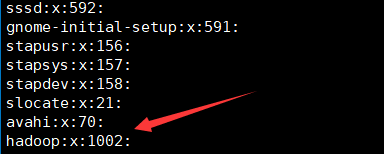
因此执行命令
[root@node1 ~]# useradd -u 660 -g 1002 -o hbase
上面的仅作参考,之后依然用Hadoop用户进行搭建
2、分别修改四台节点机的环境变量。
(Hadoop配置时已经完成)
3、下载hbase软件包。
4、使用WinSCP上传hbase软件包到node1节点机的root目录下

5、解压文件,安装文件。
[root@node1 ~]# tar xzvf hbase-1.1.5-bin.tar.gz
[root@node1 ~]# mv hbase-1.1.5 /home/hadoop/
6、Hbase配置文件(主要三个)
主要有:hbase-env.sh、hbase-site.xml、regionservers,配置文件在/home/hadoop/hbase-1.1.5/conf/目录下。
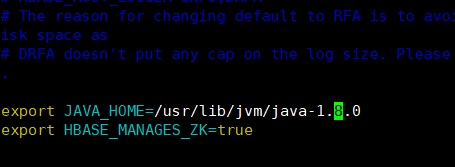
1)修改hbase-env.sh文件,主要设置jdk路径和设置由hbase自动启动zookeeper。
[root@node1 ~]# cd /home/hadoop/hbase-1.1.5/conf
[root@node1 conf]# vim hbase-env.sh
直接后面添加,java的版本要跟自己安装的一样
2)修改hbase-site.xml文件,将文件中的<configuration></configuration>修改为如下内容。
<configuration>
<property>
<name>hbase.master</name> #指明master节点
<value>node1:60000</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<property>
<name>hbase.rootdir</name> #指明数据位置
<value>hdfs://node1:9000/hbase-1.1.5</value> #该值hdfs://node1:9000与
#hadoop的core-site.xml配置相同
</property>
<property>
<name>hbase.cluster.distributed</name> #指明是否配置成为集群模式
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> #指明zookeeper安装节点
<value>node2,node3,node4</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
#指明zookeeper数据存储目录
<value>/home/hadoop/hbase-1.1.5/tmp/zookeeper</value>
</property>
</configuration>
3)修改配置文件regionservers,添加slave节点的机器名或IP地址。

7、修改“/home/hbase/”文件用户主/组属性。
[root@node1 conf]# chown -R hadoop:hadoop /home/hadoop
8、将配置好的hbase系统复制到其他三个节点机上。
[root@node1 ~]# cd /home/hadoop/
[root@node1 hadoop]# scp -r hbase-1.1.5 hadoop@node2:/home/hadoop/
[root@node1 hadoop]# scp -r hbase-1.1.5 hadoop@node3:/home/hadoop/
[root@node1 hadoop]# scp -r hbase-1.1.5 hadoop@node4:/home/hadoop/
9、分别登录node2、node3、node4节点机,修改 “/home/hbase/”文件用户主/组属性。
[root@node2 ~]# chown -R hadoop:hadoop /home/hadoop
[root@node3 ~]# chown -R hadoop:hadoop /home/hadoop
[root@node4 ~]# chown -R hadoop:hadoop /home/hadoop
HBase管理与HBase Shell
Hbase是分布式数据库,运行在hadoop环境上,HBase Shell是HBase提高的操作命令。
HBase Shell的主要命令包括:create 创建表,describe 查看表的结构,enable/disable 表激活/取消,drop 删除表,get/put 表读/写。本实训主要完成HBase数据库服务的启动、停止,HBase数据库的管理操作。
1、启动hbase服务。
(开启hbase前需要先开启hadoop)
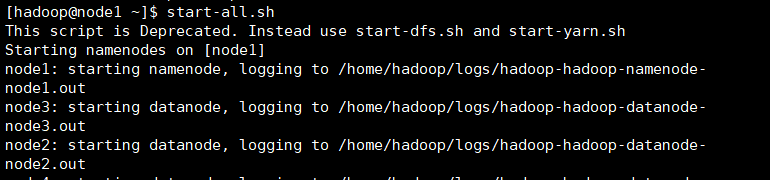

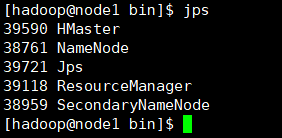
2、检查运行结果
Master节点机的进程如下所示:(若出现节点少HRegionServer,考虑时间没有同步,先进行同步配置,参考同专栏《网络时间协议》)也可以手动去虚拟机设置那里直接选择与物理主机时间同步选项
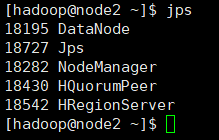
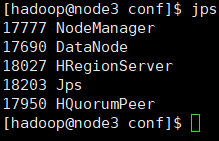
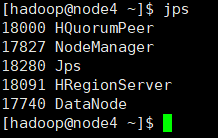
3、停止hbase服务。(暂不操作)
stop-hbase.sh
4、登录hbase的 web界面。

5、启动hbase shell(进行以下一系列数据库操作)

6、建立表scores,两个列簇:grade和course。
hbase(main):001:0> create 'scores','grade','course'
#以下为输出
0 row(s) in 1.4890 seconds
=> Hbase::Table - scores
7、查看当前hbase中的表。
hbase(main):002:0> list
#以下为输出
TABLE
scores
1 row(s) in 0.0260 seconds
=> ["scores"]
8、添加6条纪录。
1)记录1:jie,grade:143cloud。操作命令如下:
hbase(main):003:0> put 'scores','jie','grade:','143cloud'
#以下为输出
0 row(s) in 0.1760 seconds
2)记录2:jie,course:math,85。操作命令如下:
hbase(main):004:0> put 'scores','jie','course:math','85'
#以下为输出
0 row(s) in 0.0180 seconds
3)记录3:jie,course:cloud,92。操作命令如下:
hbase(main):005:0> put 'scores','jie','course:cloud','92'
#以下为输出
0 row(s) in 0.0190 seconds
4)记录4:shi,grade:133soft。操作命令如下:
hbase(main):006:0> put 'scores','shi','grade:','133soft'
#以下为输出
0 row(s) in 0.0160 seconds
5)记录5:shi,grade:math,86。操作命令如下:
hbase(main):007:0> put 'scores','shi','course:math','86'
#以下为输出
0 row(s) in 0.0140 seconds
6)记录6:shi,grade:cloud,90。操作命令如下:
hbase(main):008:0> put 'scores','shi','course:cloud','90'
#以下为输出
0 row(s) in 0.0110 seconds
9、
1)读取jie的记录。
hbase(main):009:0> get 'scores','jie'

2)读取jie的班级。
hbase(main):010:0> get 'scores','jie','grade'

10、查看整个表记录。
hbase(main):011:0> scan 'scores'
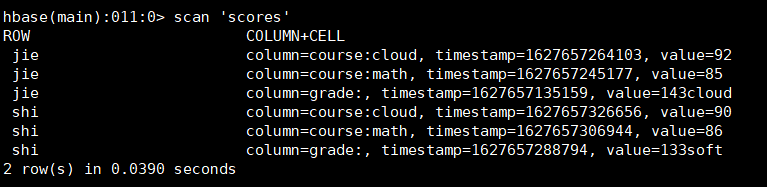
11、按列查看表记录。
hbase(main):012:0> scan 'scores',{COLUMNS=>'course'}

12、增加新的列簇。
hbase(main):013:0> alter 'scores',NAME=>'age'
13、查看表结构。
hbase(main):014:0> describe 'scores'

14、删除指定记录。
delete 'scores','shi','grade'
15、删除列簇,删除表
alter 'scores',NAME=>'age',METHOD=>'delete' #删除列簇
disable 'scores' #删除表
drop 'scores' #删除表
















 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











