







1、用案例引出条件概率
用类似抽签的案例
换句话来说就是先抢和后抢的概率如何。
讨论:
有人说先抢第一个人中的概率是1/47,第二个人抢的概率是1/46,依次下来,越后面的人概率是越大的。这是错的,为什么呢,因为在每一次抽的情况下我都要考虑,前一个人不中概率是多少,然后才能轮到下一个人抢是不是,算一下概率。
我们总共进行了n轮事件, A n − 1 A_{{\rm{n}} - 1} An−1代表“第n-1轮不中”
事件 B n B_{\rm{n}} Bn代表“第n轮抽中”
假设在第5轮我一定想要100元,可能性多大?
就是要列出当n=5时,发生的概率,那么要算n=5的前提,必须就是n=1、2、3、4都不中。
∴ P ( A 1 ‾ A 1 ‾ A 1 ‾ A 1 ‾ B 5 ) = P ( A 1 ‾ ) ⋅ P ( A 2 ‾ ∣ A 1 ‾ ) ⋅ P ( A 3 ‾ ∣ A 2 ‾ A 1 ‾ ) ⋅ P ( A 4 ‾ ∣ A 3 ‾ A 2 ‾ A 1 ‾ ) ⋅ P ( A 5 ‾ ∣ A 4 ‾ A 3 ‾ A 2 ‾ A 1 ‾ ) P(\overline {A_1 } \overline {A_1 } \overline {A_1 } \overline {A_1 } B_5 ) = P(\overline {A_1 } ) \cdot P(\overline {A_2 } |\overline {A_1 } ) \cdot P(\overline {A_3 } |\overline {A_2 } \overline {A_1 } ) \cdot P(\overline {A_4 } |\overline {A_3 } \overline {A_2 } \overline {A_1 } ) \cdot P(\overline {A_5 } |\overline {A_4 } \overline {A_3 } \overline {A_2 } \overline {A_1 } ) P(A1A1A1A1B5)=P(A1)⋅P(A2∣A1)⋅P(A3∣A2A1)⋅P(A4∣A3A2A1)⋅P(A5∣A4A3A2A1)
∴ P ( A 1 ‾ ) = 46 47 P(\overline {A_1 } ) = {{46} \over {47}} P(A1)=4746
当A1抽完之后,那么就还剩下46个,除去1个中的,那么A2不中的概率就是45/46
P ( A 2 ‾ ∣ A 1 ‾ ) = 45 46 P(\overline {A_2 } |\overline {A_1 } ) = {{45} \over {46}} P(A2∣A1)=4645
以此类推
P ( A 3 ‾ ∣ A 2 ‾ A 1 ‾ ) = 44 45 P(\overline {A_3 } |\overline {A_2 } \overline {A_1 } ) = {{44} \over {45}} P(A3∣A2A1)=4544
P ( A 4 ‾ ∣ A 3 ‾ A 2 ‾ A 1 ‾ ) = 43 44 P(\overline {A_4 } |\overline {A_3 } \overline {A_2 } \overline {A_1 } ) = {{43} \over {44}} P(A4∣A3A2A1)=4443
那么最后
P ( A 5 ‾ ∣ A 4 ‾ A 3 ‾ A 2 ‾ A 1 ‾ ) = 1 43 P(\overline {A_5 } |\overline {A_4 } \overline {A_3 } \overline {A_2 } \overline {A_1 } ) = {1 \over {43}} P(A5∣A4A3A2A1)=431
就是说无论抽多少此可以发现,相乘之后,中间的都会被约掉仍然是1/47,所以无需纠结。
2、条件概率引出贝叶斯
以硬币为例正面为X,反面为Y
A=“至少有一次为X”
B=“两次都为同一面”
列出样本空间,S为总的样本空间
S={XX,XY,YX,YY}
A={XY,XX,YX}
B={XX,YY}
那么A发生的条件下B发生的概率是多少?
对比AB可以看出
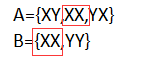
P(B|A)=1/3
S对比A、B,容易看出
P(A)=3/4,P(B)=1/2
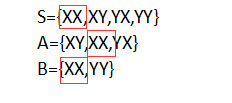
P(AB)=1/4
∴可以发现
P ( B ∣ A ) = P ( A B ) P ( A ) = 1 3 P(B|A) = {{P(AB)} \over {P(A)}} = {1 \over 3} P(B∣A)=P(A)P(AB)=31
∵
P
(
A
B
)
=
P
(
B
∣
A
)
P
(
A
)
P(AB) = P(B|A)P(A)
P(AB)=P(B∣A)P(A)
变形一下
P ( B A ) = P ( A ∣ B ) P ( B ) P(BA) = P(A|B)P(B) P(BA)=P(A∣B)P(B)
又∵
P ( B A ) = P ( A B ) P(BA) = P(AB) P(BA)=P(AB)
代入
P ( B ∣ A ) = P ( A B ) P ( A ) = 1 3 P(B|A) = {{P(AB)} \over {P(A)}} = {1 \over 3} P(B∣A)=P(A)P(AB)=31
∴
P
(
B
∣
A
)
=
P
(
A
∣
B
)
P
(
B
)
P
(
A
)
=
1
3
P(B|A) = {{P(A|B)P(B)} \over {P(A)}} = {1 \over 3}
P(B∣A)=P(A)P(A∣B)P(B)=31
也就是贝叶斯公式
3、朴素贝叶斯基本原理

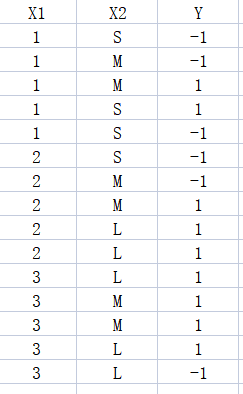
假设黑点为0,黄点为1,随便给一个点,判断P(X1,X2)的概率,若P1(X1,X2)>P0(X1,X2),那么给出的点就归类在1标签,反之也如此。
那么当P(X1,X2…Xn)为联合概率,也是如此。
就是说给定了的这些数据特征怎么样去计算它属于某一类别的联合概率是多少的问题。
4、训练数据
P
(
B
∣
A
)
=
P
(
A
∣
B
)
P
(
B
)
P
(
A
)
P(B|A) = {{P(A|B)P(B)} \over {P(A)}}
P(B∣A)=P(A)P(A∣B)P(B)
那么可以写成
P
(
y
i
∣
x
)
=
P
(
x
∣
y
i
)
P
(
y
i
)
P
(
x
)
P(y_i |x) = {{P(x|y_i )P(y_i )} \over {P(x)}}
P(yi∣x)=P(x)P(x∣yi)P(yi)
其中i表示分了多少类,比如分-1和1就是两类
P(AB)表示联合概率,如果两个是独立的,那么会等于P(A)·P(B)
那么就会得出
P
(
A
B
∣
y
)
=
P
(
A
∣
y
)
P
(
B
∣
y
)
P(AB|y) = P(A|y)P(B|y)
P(AB∣y)=P(A∣y)P(B∣y)
其中从x来看,可能是多维的特征向量,就是说x会为(x1,x2,x3,…xn),那么当它们独立,就会得出:
P
(
y
i
∣
x
1
,
x
1
,
x
1
,
.
.
.
,
x
n
)
=
P
(
x
1
∣
y
i
)
P
(
x
2
∣
y
i
)
P
(
x
3
∣
y
i
)
.
.
.
P
(
x
n
∣
y
i
)
P
(
x
)
P(y_i |x_1 ,x_1 ,x_1 ,...,x_n ) = {{P(x_1 |y_i )P(x_2 |y_i )P(x_3 |y_i )...P(x_n |y_i )} \over {P(x)}}
P(yi∣x1,x1,x1,...,xn)=P(x)P(x1∣yi)P(x2∣yi)P(x3∣yi)...P(xn∣yi)
那么假如给定数据判断=1的概率是多少时,然后再判断=-1的概率,算出来的概率都会除去P(x),所以就把P(x)忽略掉了,仅仅是需要比较大小,而并不是算特定的值。
P ( y i ∣ x 1 , x 1 , x 1 , . . . , x n ) = P ( x 1 ∣ y i ) P ( x 2 ∣ y i ) P ( x 3 ∣ y i ) . . . P ( x n ∣ y i ) P(y_i |x_1 ,x_1 ,x_1 ,...,x_n ) = P(x_1 |y_i )P(x_2 |y_i )P(x_3 |y_i )...P(x_n |y_i ) P(yi∣x1,x1,x1,...,xn)=P(x1∣yi)P(x2∣yi)P(x3∣yi)...P(xn∣yi)
例子:

对于当出现0的情况,如果出现某一个值为零,那么总体概率相乘也就会等于0,这是不切实际的,只可能无限接近于0,就会引入拉普拉斯修正。
先验修正:
P
(
y
)
=
∣
D
y
∣
+
1
∣
D
∣
+
N
P(y) = {{|D_y | + 1} \over {|D| + N}}
P(y)=∣D∣+N∣Dy∣+1
似然修正:
P
(
x
i
∣
y
)
=
∣
D
y
,
x
i
∣
+
1
∣
D
y
∣
+
N
i
P(x_i |y) = {{|D_{y,x_i } | + 1} \over {|D_y | + N_i }}
P(xi∣y)=∣Dy∣+Ni∣Dy,xi∣+1
N
i
{{N_i}}
Ni 表示第i个属性的可能取值

处理连续型数据
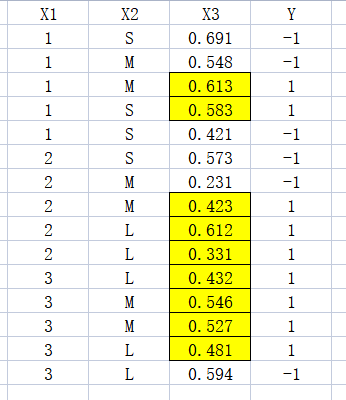
假设
P
(
y
=
1
∣
1
,
S
,
0.48
)
=
P
(
x
1
=
1
∣
y
=
1
)
P
(
x
2
=
S
∣
y
=
1
)
P
(
x
3
=
0.48
∣
y
=
1
)
P
(
y
=
1
)
P({\rm{y}} = 1|1,S,0.48) = P(x_1 = 1|y = 1)P(x_2 = S|y = 1)P(x_3 = 0.48|y = 1)P(y = 1)
P(y=1∣1,S,0.48)=P(x1=1∣y=1)P(x2=S∣y=1)P(x3=0.48∣y=1)P(y=1)
P
(
y
=
1
∣
1
,
S
,
0.48
)
=
P
(
x
1
=
1
∣
y
=
−
1
)
P
(
x
2
=
S
∣
y
=
−
1
)
P
(
x
3
=
0.48
∣
y
=
−
1
)
P
(
y
=
−
1
)
P({\rm{y}} = 1|1,S,0.48) = P(x_1 = 1|y = - 1)P(x_2 = S|y = - 1)P(x_3 = 0.48|y = - 1)P(y = - 1)
P(y=1∣1,S,0.48)=P(x1=1∣y=−1)P(x2=S∣y=−1)P(x3=0.48∣y=−1)P(y=−1)
那么主要是求x1=0.48的时候该怎么求?
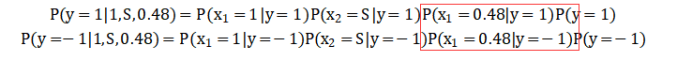
P
(
x
i
∣
y
)
=
1
2
π
σ
y
,
i
2
exp
(
−
(
x
i
−
μ
y
,
i
)
2
2
σ
y
,
i
2
)
P(x_i |y) = {1 \over {\sqrt {2\pi \mathop \sigma \nolimits_{y,i}^2 } }}\exp ( - {{\mathop {(x_i - \mu _{y,i} )}\nolimits^2 } \over {2\sigma _{y,i}^2 }})
P(xi∣y)=2πσy,i21exp(−2σy,i2(xi−μy,i)2)
其中方差: σ y , i 2 \mathop \sigma \nolimits_{y,i}^2 σy,i2
均值: μ y , i {\mu _{y,i} } μy,i
就是将X1=0.48代入公式,然后根据y=1的值或者y=-1条件下的值求均值和方差,再代入公式得出结果。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











