






培训通知
Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。
我们在阅读文献时,经常会看到竞争风险模型,今天我们就来讲讲,是什么和怎么用,一篇文章就带你搞定!以医学顶刊《BMJ》的一篇文章队列研究为例。

本公众号回复“ 原文”即可获得R语言代码,文献等资料 |
这篇文章使用竞争风险模型来分析数据,那么何为竞争风险模型呢?
通常,我们在进行生存分析的时候,只会有关心一个结局变量。但当数据中有两种结局变量的时候应该怎么办呢?不妨看看竞争风险模型。今天让我们从定义与数据的角度来了解竞争风险模型。
一、定义
竞争风险分析是一种特殊类型的生存分析,旨在正确估计存在竞争事件时事件的边际概率。
描述生存过程的传统方法,例如 Kaplan Meier 乘积极限法(也称为Kaplan Meier估计器),其设计目的不是为了适应同一事件的多个原因的竞争性质,因此在分析特定原因事件的边际概率时,它们往往会产生不准确的估计。
因此,竞争风险模型有相应的分析方法,即累积发生率函数(Cumulative Incidence Function ,CIF),通过估计特定事件的边际概率作为其特定原因概率和总体生存概率的函数来解决此特定问题。
简单来说:一般的生存分析用 Kaplan Meier 乘积极限法,竞争风险分析用累积发生率函数CIF。
该方法结合了KM乘积极限方法的思想和竞争因果路径的思想,为一组受试者的多个竞争事件的生存体验提供了更可解释的估计。与许多分析一样,竞争风险分析包括一种非参数方法,该方法涉及使用修改的卡方检验来比较各组之间的 CIF 曲线,以及一种基于子分布风险函数对 CIF 进行建模的参数方法。
1.什么是“竞争事件”和“竞争风险”?
例如,在标准生存数据中,受试者在随访期间应该只经历一种类型的事件(如乳腺癌死亡);然而,在现实生活中,受试者可能会经历不止一种类型的特定事件(如,如果死亡率具有研究意义,那么我们的观察结果——肿瘤科的老年患者,可能会死于心脏病或乳腺癌,甚至交通事故)。
当这些不同类型的事件只能发生其中一种时,我们将这些事件称为“竞争事件”,从某种意义上说,它们相互竞争以传递感兴趣的事件,并且一种类型的事件的发生将阻止其他事件的发生。因此,我们将这些事件的概率称为“竞争风险”,从某种意义上说,每个竞争事件的概率都受到其他竞争事件的某种调节,这有一个适合描述由多种类型决定的生存过程的解释的事件。
以下有更多的实例中能用到竞争风险:
研究乳腺癌癌症特异性死亡时,其他死亡原因(例如死于心脏病)与乳腺癌癌症特异性死亡形成竞争关系
士兵可能会在战斗或交通事故中死亡
研究谵妄与痴呆症发病率时,患者死亡与痴呆症发病率
2. 为什么我们不应该使用Kaplan Meier估计器?
与标准生存分析一样,竞争事件数据的分析目标是估计一段时间内许多可能事件中一个事件的概率,从而允许受试者在竞争事件中失败。在上面的例子中,我们可能想要估计一段时间内的乳腺癌死亡率,并想知道在调整或不调整协变量的情况下,两个或多个治疗组之间的乳腺癌死亡率是否存在差异。
在标准生存分析中,这些问题可以通过使用 Kaplan Meier 乘积极限法来获得随时间变化的事件概率,并使用 Cox 比例风险模型来预测该概率来回答。
同样,在竞争事件数据中,典型的方法涉及使用 KM 估计器来单独估计每种类型事件的概率,同时将除了因失访或退出而被审查的其他竞争事件视为被审查。这种估计事件概率的方法称为特定原因风险函数,其数学表达式为:
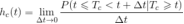
随机变量 Tc 表示事件类型 c 发生故障的时间,因此,假定事件 c 在时间 t 之前未发生故障,则特定原因的危险函数 hc(t) 给出事件类型 c 在时间 t 时的瞬时故障率。
相应地,有一个基于 Cox 比例风险模型的特定原因风险模型,其公式为:
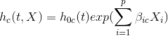
事件类型 c 在时间 t 的比例风险模型允许协变量的影响因事件类型而异,如下标 beta 系数所示。
使用这些方法,人们可以单独估计每一项竞争事件的失败率。例如,在我们的乳腺癌死亡率示例中,当乳腺癌死亡是感兴趣的事件时,除了传统的审查观察之外,心脏病发作和所有其他原因导致的死亡也应该被视为审查。这将使我们能够估计乳腺癌死亡率的特定原因风险,并继续拟合乳腺癌死亡率的特定原因风险模型。当心脏病发作引起的死亡成为关注事件时,同样的程序也可以适用。
针对具体原因的方法的一个主要警告是,它仍然假设对那些实际上没有受到审查但在竞争事件中失败的受试者进行独立审查,就像标准审查制度(例如失访)一样。假设这个假设成立,当关注乳腺癌的特定原因死亡率时,那么在时间 t 时任何被审查的受试者都会有相同的乳腺癌死亡率,无论审查的原因是 CVD 还是其他死因,或失访。这个假设相当于说竞争事件是独立的,这是KM类型的分析有效的基础。
但是,无法明确测试任何给定数据集是否满足此假设。例如,我们永远无法确定一个死于心脏病的受试者如果没有死于心脏病,是否会死于乳腺癌,因为对于死于心脏病的受试者来说,死于癌症的可能性是无法观察到的。因此,特定原因风险函数的估计没有提供信息解释,因为它严重依赖于独立性审查假设。
3.解决办法是什么?
迄今为止,分析竞争事件数据的最流行的替代方法称为累积发生率函数 (CIF),它估计每个竞争事件的边际概率。
(边际概率定义为受试者实际发生感兴趣事件的概率,无论他们是否在其他竞争事件中受到审查或失败。)
在最简单的情况下,当只有一个感兴趣的事件时,CIF 应等于(1-KM)估计值。然而,当存在竞争事件时,每个竞争事件的边际概率可以根据 CIF 进行估计,CIF 是从我们之前讨论的特定原因危害中得出的。根据定义,边际概率不假设竞争事件的独立性,并且它的解释与临床医生在成本效益分析中更相关,在成本效益分析中,风险概率用于评估治疗效用。
3.1累积发生函数(CIF)
正如我们之前提到的,当没有竞争事件时,CIF 相当于 1-KM 估计器。当存在竞争事件时,CIF 与 1-KM 估计器的不同之处在于,它使用总体生存函数 S(t),该函数除了感兴趣的事件之外还对竞争事件的失败进行计数,而 1-KM 估计器使用事件类型特定的生存函数 Sc(t),它将竞争事件的失败视为已审查。
通过使用总体生存函数,CIF 无需对竞争事件的审查独立性做出无法验证的假设。由于 S(t) 始终小于 Sc(t),因此在竞争事件数据中,CIF 始终小于 1-KM 估计值,这意味着 1-KM 往往会高估感兴趣的事件类型的失败概率。
另一个优点是,根据定义,每个竞争事件的 CIF 是 S(t) 的一小部分,因此所有竞争事件的每个单独危险的总和应等于总体危险。 CIF的这一特性使得剖析整体危险成为可能,从而具有更实用的解释。
3.2 非参数分析
Gray (1988) 提出了一种非参数检验来比较两个或多个 CIF。该检验类似于比较 KM 曲线的对数秩检验,使用修改后的卡方检验统计量。该检验不需要独立审查假设。
参考文献:https://www.jstor.org/stable/2241622
3.3 参数分析
Fine 和 Gray (1999) 提出了比例风险模型,旨在通过将 CIF 曲线视为次分布函数,对带有协变量的 CIF 进行建模。次分布函数类似于 Cox 比例风险模型,不同之处在于它对从 CIF 派生的风险函数(称为次分布风险)进行建模。
https://www.jstor.org/stable/2670170
该模型满足所建模的亚群风险的比例风险假设,这意味着一般风险比公式与 Cox 模型基本相同,除了 Cox 模型中的系数 beta 被 Fine 和 Gray 中的 gamma 替换为细微的外观差异外。因此,我们应该以与 Cox 模型估计的 beta 类似的方式解释 gamma,只不过它估计存在竞争事件时某些协变量的影响。Fine 和 Gray 模型还可以扩展以允许依赖于时间的协变量。
二、数据与R语言代码
本公众号回复“ 原文 ”即可获得R语言代码,文献等资料 |
我们使用R语言自带的casebase包中的“bmtcrr”数据进行分析

查看前30行数据:
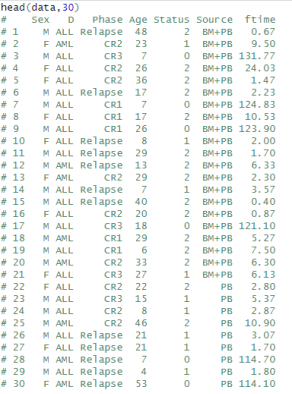
可以看到,数据中,结局由ftime(时间变量)与Status(状态)组成,而Status中,分别是
0:没有发生任何时间
1:疾病复发
2:发生其他事件(比如死亡)
由于死亡后无法观察到疾病是否复发,所以与状态1互为竞争事件。
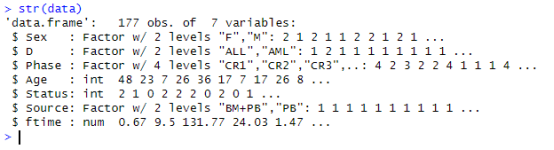
使用str()函数查看数据类型
我们选择移植干细胞来源Source作为单因素探究方向:
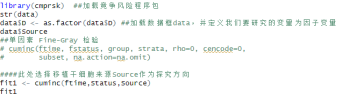
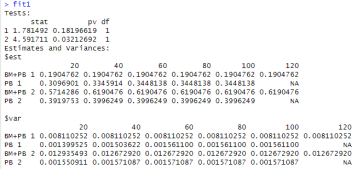
结果解读:
第一行中,统计量为1.781492,P值为0.18196619>0.05。表明在控制了状态2(发生其他事件)时,干细胞来源BM+PB与PB的累积发生率没有统计学差异。
第二行中统计量为4.591711 ,P值为0.03212692<0.05。,表明在控制了状态1(复发)的情况下,BM+PM与PB的其他事件竞争风险累计发生率有统计学差异。
$ets 中数据为各时间节点时的CIF值,例如接受BM+PB患者的复发CIF为0.1904762。
$var 中数据为各时间点时CIF值的方差
画图:

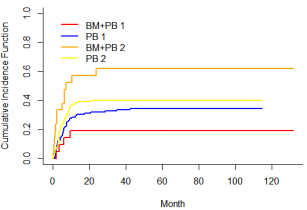
图中与结果中的fit1$ets数据相同,以图像的形式呈现
多因素代码:
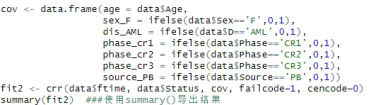
我们先把所有自变量都变成数字的形式后,使用data.frame组合成一个数据集。使用crr () 进行分析。指定failcode=1, cencode=0, 分别代表结局事件1与截尾0,其他默认为竞争风险事件2。
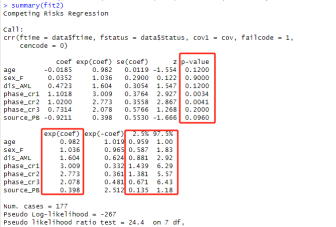
我们重点关注其中的p-value,表示该变量是否有统计学差异,exp(coef) 为风险比的值,2.5%与97.5%为95%置信区间。其中phase变量的P值小于0.05,表明在多因素模型中,该变量有统计学差异。即移植阶段是患者复发的独立影响因素。
参考文献:
https://www.jstor.org/stable/2241622
https://www.jstor.org/stable/2670170
https://www.publichealth.columbia.edu/research/population-health-methods/competing-risk-analysis
本公众号回复“ 原文 ”即可获得R语言代码,文献等资料 |
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: 二、数据分析服务 浙江中医药大学郑老师团队接单各项医学研究数据分析的服务,提供高质量统计分析报告。有兴趣了解一下详情: |















 4353
4353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









