






在结局是定量数据的回归分析研究中,除了我们常见的线性影响因素研究,还有一种较为经典的分析策略——多模型控制混杂!
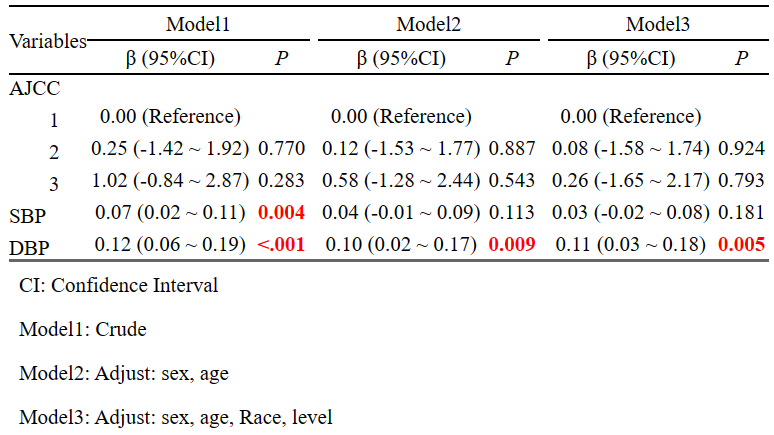
即重点研究某个/多个焦点因素与结局之间的关系,并通过3-5个模型逐步调整协变量数量来探讨暴露与结局的关联,在论文中通常如下图所示,仅列出不同模型中焦点暴露的回归结果,更加清晰简洁,一目了然!
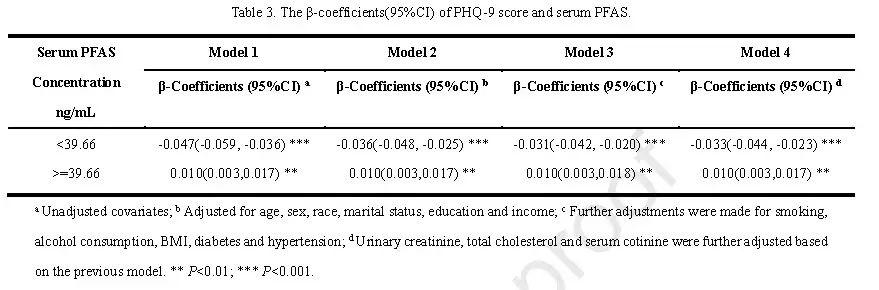
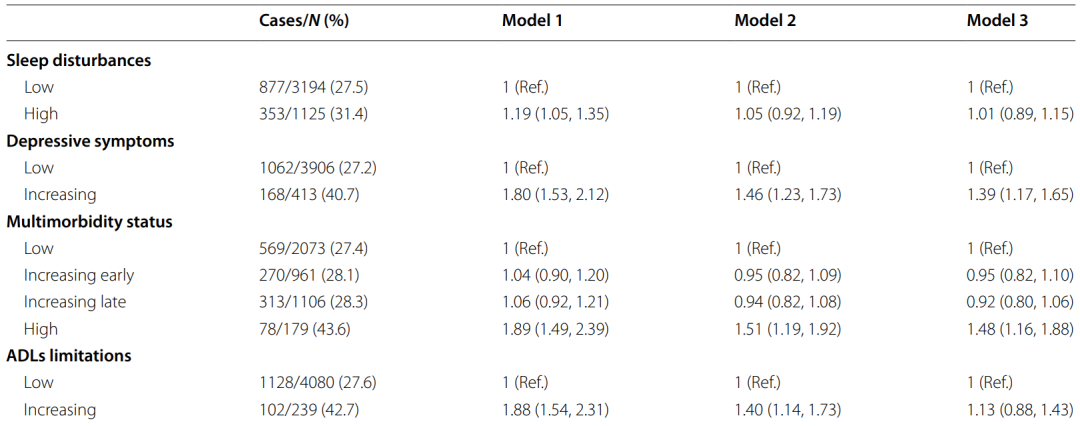
但是使用SPSS或R语言完成各个模型的分析、再进行数据的整理汇总、绘制规范三线表,往往需要花费一定的时间!因此,这里为大家推荐一个统计分析小工具——风暴统计,可以超快速完成多模型线性回归的分析!
风暴统计是由浙江中医药大学的郑卫军教授基于R语言开发的,不仅结果准确性有保障,并且全部实现菜单化操作,统计小白也可以轻松上手,结果可以直接输出为word三线表,避免了繁琐的整理工作!
下面我们通过一份实操数据,为大家详细介绍风暴统计平台进行多模型线性回归的操作步骤!

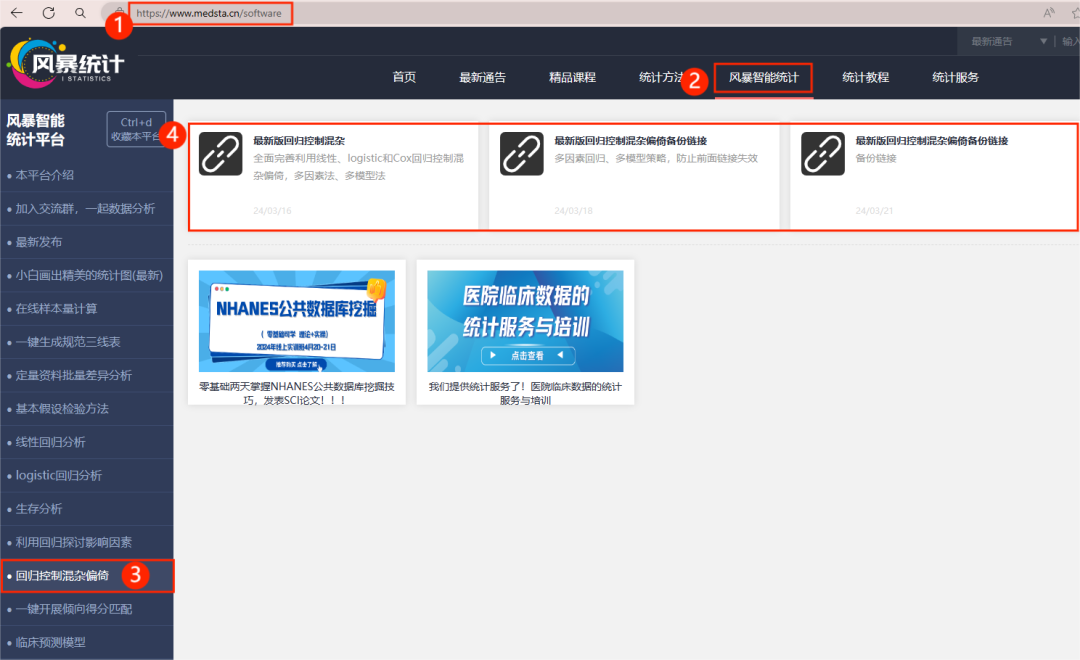
1. 进入风暴统计平台
首先,进入风暴统计平台,点击“风暴智能统计”—“回归控制混杂”—"最新版回归控制混杂"。
这里我们不再赘述数据的导入与整理过程,详细教程大家可以点击下方链接:
2. 多模型控制混杂
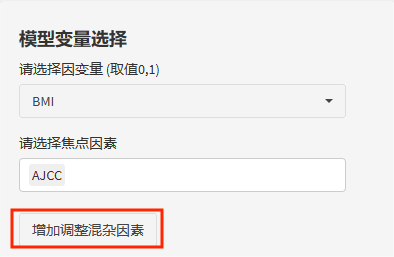
完成数据导入后,就可以直接来到"多模型线性回归策略"了。首先,在"模型变量选择"部分依次选入"因变量"与”焦点因素“。
线性回归的因变量只能是定量变量,焦点因素不限变量类型,定量或分类都可以,焦点因素可以是一个也可以是多个哦。
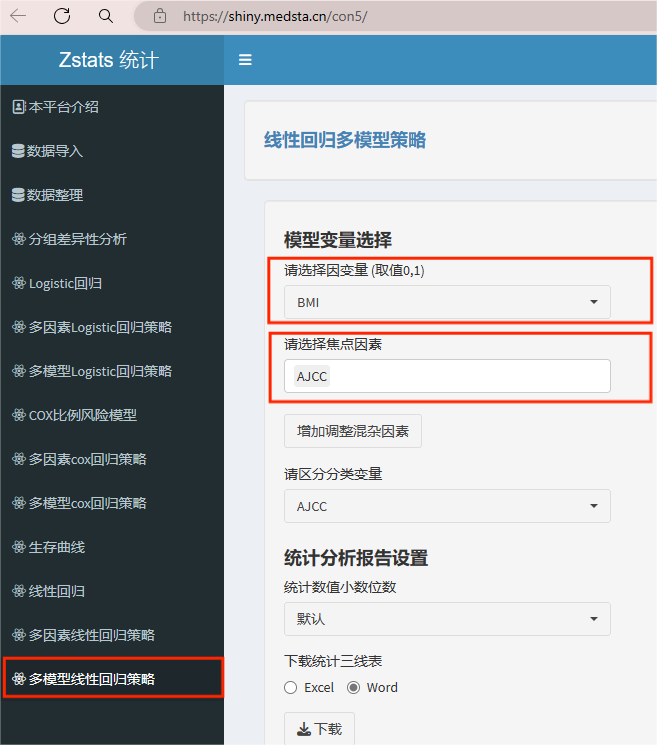
接着点击"增加调整混杂因素"。
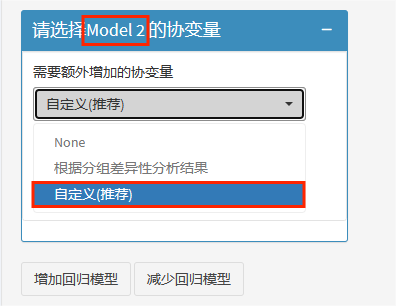
model1就是我们的单因素模型,因此我们直接开始选择model2的协变量,推荐使用自定义,多个模型逐个调整变量。
可能有同学会问,怎样确定我每个模型中要调整什么协变量呢?
其实这个并没有严格的标准,通常情况下model1就是焦点因素与结局的单因素模型,最后一个model则是调整了全部的混杂因素,中间model可以自行决定。
这里我们model2先矫正性别与年龄,接着,继续点击"增加回归模型"。
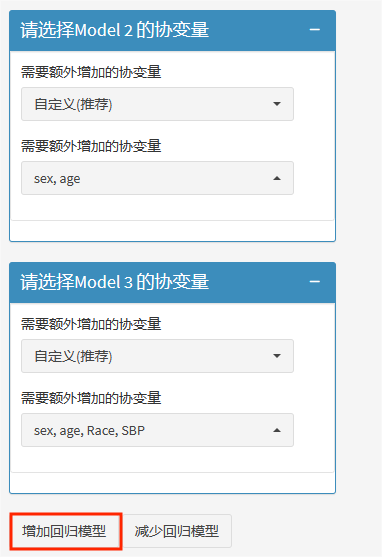
model2矫正的性别、年龄会自动顺延至model3。
另外,model3我们再额外矫正level和race。如需继续增加模型,可继续点击”增加回归模型“,最多可增至model5。
完成后,右侧就直接出现多模型的结果啦,包括脚注一应俱全!
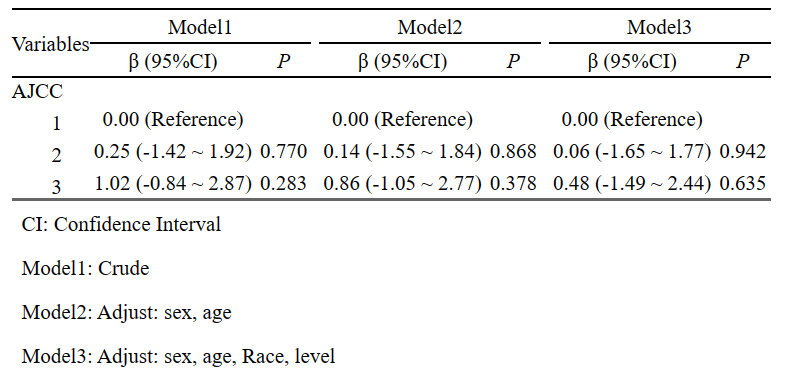
同样的,如果我们研究中有不止一个焦点因素,也可以同时选入,结果会显示全部的焦点因素,十分快捷!
3.下载结果
然后也可以选择小数位数,默认情况下,P值为3位小数,其他统计量为2位小数。指定小数位数后,P值与统计量的小数位数将会统一。调整完成后,下载最终的三线表结果!
如果您在风暴统计平台的使用过程中有任何的建议或疑问,可以加入我们的讨论群!群里郑老师与助教会在群内解答!
欢迎加入

统计机器人交流群















 7429
7429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









