






1. 双射基础
双射的定义
双射是指一个函数同时具有单射(一对一)和满射(映上)的性质。让我们逐步解析:
1. 单射(Injection)
- 定义:对于任意 y y y 在像集中,至多只有一个 x x x 与之对应
- 数学表达:若 f ( x 1 ) = f ( x 2 ) f(x_1) = f(x_2) f(x1)=f(x2),则必有 x 1 = x 2 x_1 = x_2 x1=x2
- 直观理解:输入不同,输出一定不同
例如,对于线性变换
T
A
T_A
TA:
若
A
x
1
=
A
x
2
,则
x
1
=
x
2
\text{若 } Ax_1 = Ax_2 \text{,则 } x_1 = x_2
若 Ax1=Ax2,则 x1=x2
2. 满射(Surjection)
- 定义:对于任意 y y y 在像集中,至少有一个 x x x 与之对应
- 数学表达:对于任意 y y y 在值域中,存在 x x x 使得 f ( x ) = y f(x) = y f(x)=y
- 直观理解:目标空间中的每个元素都能被"射到"
对于线性变换
T
A
T_A
TA:
对任意向量
b
,方程
A
x
=
b
总有解
\text{对任意向量 } b \text{,方程 } Ax = b \text{ 总有解}
对任意向量 b,方程 Ax=b 总有解
3. 双射(Bijection)
- 定义:既是单射又是满射的函数
- 数学表达:对于任意 y y y 在像集中,恰好有一个 x x x 与之对应
- 直观理解:一一对应关系
可逆矩阵与双射的关系
当矩阵 A A A 可逆时,线性变换 T A T_A TA 是双射,这意味着:
-
唯一性:每个输出都对应唯一的输入
A x = b 有唯一解 Ax = b \text{ 有唯一解} Ax=b 有唯一解 -
存在性:每个可能的输出都能通过某个输入得到
对任意向量 b ,存在向量 x 使得 A x = b \text{对任意向量 } b \text{,存在向量 } x \text{ 使得 } Ax = b 对任意向量 b,存在向量 x 使得 Ax=b -
可逆性:可以通过 A − 1 A^{-1} A−1 还原原始输入
x = A − 1 ( A x ) x = A^{-1}(Ax) x=A−1(Ax)
图解说明
考虑一个简单的2×2可逆矩阵变换:
A = [ 2 0 0 3 ] A = \begin{bmatrix} 2 & 0 \\ 0 & 3 \end{bmatrix} A=[2003]
这个变换:
- 将x轴上的单位向量拉伸为2倍
- 将y轴上的单位向量拉伸为3倍
- 是一个双射变换,因为:
- 每个输出点对应唯一的输入点(单射)
- 平面上的每个点都能通过某个输入点得到(满射)
理解双射对于理解线性变换和可逆矩阵非常重要,它保证了我们可以:
4. 唯一地确定输入
5. 完整地覆盖输出空间
6. 可以进行逆变换
这也解释了为什么可逆矩阵在线性代数中如此重要 - 它们代表了完全可逆的线性变换。
2. 双射及其对应的矩阵变换 图文结合讲解
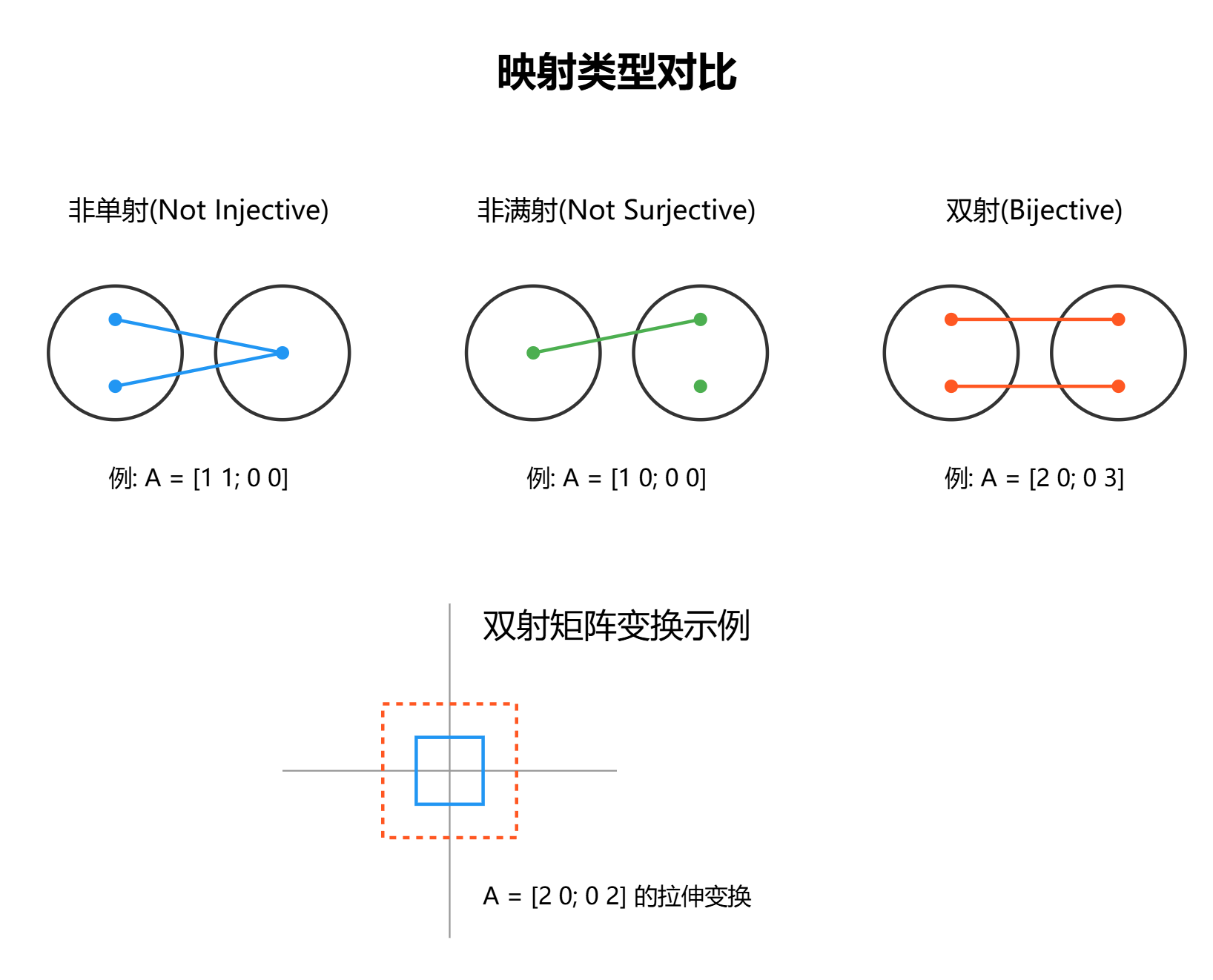
让我们详细解释上图中展示的各种映射类型:
1. 非单射(Not Injective)
- 左侧展示了两个不同的输入点映射到同一个输出点
- 矩阵示例 A = [ 1 1 0 0 ] A = \begin{bmatrix} 1 & 1 \\ 0 & 0 \end{bmatrix} A=[1010] 将不同向量映射到同一个向量
- 这种映射有"多对一"的特征
- 信息在变换过程中丢失,无法唯一还原
2. 非满射(Not Surjective)
- 目标空间中有些点无法通过映射得到
- 矩阵示例 A = [ 1 0 0 0 ] A = \begin{bmatrix} 1 & 0 \\ 0 & 0 \end{bmatrix} A=[1000] 的值域不是整个目标空间
- 变换后的空间"覆盖不完全"
- 某些输出值无法通过任何输入得到
3. 双射(Bijective)
- 每个输入都对应唯一的输出,每个输出也对应唯一的输入
- 矩阵示例 A = [ 2 0 0 3 ] A = \begin{bmatrix} 2 & 0 \\ 0 & 3 \end{bmatrix} A=[2003] 是一个可逆矩阵
- 完美的"一一对应"关系
- 信息完全保留,可以双向转换
4. 双射矩阵变换示例
图中下方展示了一个具体的双射变换例子:
- 原始正方形(蓝色实线)经过变换后变成更大的正方形(橙色虚线)
- 变换矩阵 A = [ 2 0 0 2 ] A = \begin{bmatrix} 2 & 0 \\ 0 & 2 \end{bmatrix} A=[2002] 将每个点沿x和y方向同时拉伸为2倍
- 这是一个可逆变换,可以通过 A − 1 = [ 1 / 2 0 0 1 / 2 ] A^{-1} = \begin{bmatrix} 1/2 & 0 \\ 0 & 1/2 \end{bmatrix} A−1=[1/2001/2] 还原
实际应用意义
-
图像处理
- 可逆变换可以无损地处理和还原图像
- 非可逆变换可能导致图像信息丢失
-
数据压缩
- 双射变换保证数据可以完全还原
- 非双射变换可能用于有损压缩
-
机器学习
- 特征转换最好保持双射性质
- 避免信息丢失导致模型性能下降
-
密码学
- 加密算法需要是双射的
- 确保可以正确解密还原原始信息
理解双射对于掌握线性代数和矩阵变换至关重要,它不仅是一个数学概念,更是实际应用中保证信息完整性的重要工具。
3. 机器学习中的双射应用 - 生成对抗网络(GAN)案例
1. 案例背景
我们正在开发一个风格迁移系统,需要将照片转换为梵高画作风格:
- 输入:普通照片数据集(现实域 X)
- 输出:梵高风格图像(艺术域 Y)
- 要求:保持图像内容的同时实现风格转换
- 挑战:需要双向转换,既能从真实照片生成艺术风格,也能还原回原始照片
2. 为什么选用双射
在风格迁移中选用双射的原因:
-
可逆性需求
- 需要保证内容信息不丢失
- 能够从风格化图像恢复原始图像
- 数学表达:
F 2 ( F 1 ( x ) ) ≈ x 且 F 1 ( F 2 ( y ) ) ≈ y F_2(F_1(x)) \approx x \text{ 且 } F_1(F_2(y)) \approx y F2(F1(x))≈x 且 F1(F2(y))≈y
-
循环一致性
- 确保转换前后的图像保持一致性
- 避免模式崩溃问题
- 保证变换的可靠性:
cycle loss = ∣ ∣ F 2 ( F 1 ( x ) ) − x ∣ ∣ 1 + ∣ ∣ F 1 ( F 2 ( y ) ) − y ∣ ∣ 1 \text{cycle loss} = ||F_2(F_1(x)) - x||_1 + ||F_1(F_2(y)) - y||_1 cycle loss=∣∣F2(F1(x))−x∣∣1+∣∣F1(F2(y))−y∣∣1
-
信息保存
- 保留图像的关键特征和结构
- 确保转换的可控性
3. 使用双射的思路和技巧
- 网络架构设计
class CycleGAN:
def __init__(self):
# 生成器 G: X → Y
self.G = Generator()
# 生成器 F: Y → X
self.F = Generator()
# 判别器 D_Y: Y域判别器
self.D_Y = Discriminator()
# 判别器 D_X: X域判别器
self.D_X = Discriminator()
- 损失函数设计
def compute_cycle_loss(self, real_x, real_y):
# 前向循环一致性
fake_y = self.G(real_x)
cycle_x = self.F(fake_y)
forward_cycle_loss = tf.reduce_mean(tf.abs(real_x - cycle_x))
# 反向循环一致性
fake_x = self.F(real_y)
cycle_y = self.G(fake_x)
backward_cycle_loss = tf.reduce_mean(tf.abs(real_y - cycle_y))
# 总循环一致性损失
cycle_loss = forward_cycle_loss + backward_cycle_loss
return cycle_loss
4. 完整使用过程
- 数据预处理
def preprocess_image(image_path):
# 读取图像
image = tf.io.read_file(image_path)
image = tf.image.decode_jpeg(image)
# 标准化
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
# 调整大小
image = tf.image.resize(image, [256, 256])
return image
- 训练循环
def train_step(self, real_x, real_y):
with tf.GradientTape(persistent=True) as tape:
# 生成假样本
fake_y = self.G(real_x)
fake_x = self.F(real_y)
# 循环一致性
cycle_x = self.F(fake_y)
cycle_y = self.G(fake_x)
# 身份映射
same_x = self.F(real_x)
same_y = self.G(real_y)
# 计算各种损失
cycle_loss = self.compute_cycle_loss(real_x, real_y)
identity_loss = self.compute_identity_loss(real_x, real_y, same_x, same_y)
gen_loss = self.compute_generator_loss(fake_x, fake_y)
disc_loss = self.compute_discriminator_loss(real_x, real_y, fake_x, fake_y)
# 总损失
total_loss = cycle_loss + identity_loss + gen_loss + disc_loss
- 评估与预测
def generate_images(self, test_input):
prediction = self.G(test_input)
reconstruction = self.F(prediction)
plt.figure(figsize=(12, 4))
display_list = [test_input[0], prediction[0], reconstruction[0]]
title = ['Input Image', 'Generated Image', 'Reconstructed Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
5. 使用双射的注意事项
-
模型设计注意事项
- 确保生成器架构对称
- 使用跳跃连接保留细节信息
- 避免信息瓶颈
-
训练稳定性
- 使用渐进式训练策略
- 采用适当的学习率调度
- 监控循环一致性损失
- 数据质量控制
- 保证数据集质量均衡
- 去除异常样本
- 合理的数据增强
- 评估指标
- FID (Fréchet Inception Distance)
- SSIM (结构相似性)
- 循环一致性误差
- 常见问题处理
- 处理模式崩溃
- 解决训练不稳定
- 平衡各种损失权重
这个案例展示了双射在生成对抗网络中的应用,特别是在需要保持信息可逆性的场景中的重要性。通过合理的网络设计和训练策略,我们可以实现高质量的双向图像转换。
4. 机器学习中的双射应用 - 图像自编码器(AutoEncoder)案例
1. 案例背景
我们正在开发一个图像压缩和重建系统:
- 目标:将高维图像数据压缩到低维潜在空间,并能准确重建
- 输入:MNIST手写数字图像(28×28=784维)
- 输出:压缩后的潜在表示(32维)及重建图像
- 要求:保证压缩后的数据能完整重建原始图像
2. 为什么选用双射
-
信息保持
- 编码器将高维数据映射到低维空间: f : R 784 → R 32 f: \mathbb{R}^{784} \rightarrow \mathbb{R}^{32} f:R784→R32
- 解码器需要准确还原原始数据: g : R 32 → R 784 g: \mathbb{R}^{32} \rightarrow \mathbb{R}^{784} g:R32→R784
- 理想情况下: g ( f ( x ) ) ≈ x g(f(x)) \approx x g(f(x))≈x
-
可逆性要求
- 确保压缩不丢失关键信息
- 保证重建质量
- 数学表达: min ∣ ∣ x − g ( f ( x ) ) ∣ ∣ 2 \min ||x - g(f(x))||^2 min∣∣x−g(f(x))∣∣2
3. 使用双射的思路和技巧
- 网络架构设计
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 32)
)
# 解码器
self.decoder = nn.Sequential(
nn.Linear(32, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
4. 完整的使用过程
- 数据准备
# 加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(
root='./data',
train=True,
transform=transform,
download=True
)
train_loader = DataLoader(
train_dataset,
batch_size=128,
shuffle=True
)
- 模型训练
def train_autoencoder():
model = AutoEncoder().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(num_epochs):
for batch_idx, (data, _) in enumerate(train_loader):
# 准备数据
data = data.view(data.size(0), -1).to(device)
# 前向传播
encoded, decoded = model(data)
loss = criterion(decoded, data)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], '
f'Loss: {loss.item():.4f}')
- 评估与可视化
def visualize_reconstruction(model, data):
model.eval()
with torch.no_grad():
# 获取原始图像和重建图像
encoded, decoded = model(data.view(data.size(0), -1))
# 可视化对比
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# 原始图像
ax = plt.subplot(2, n, i + 1)
plt.imshow(data[i].cpu().numpy().reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 重建图像
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded[i].cpu().numpy().reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
- 潜在空间分析
def analyze_latent_space(model, data, labels):
model.eval()
with torch.no_grad():
# 获取编码
encoded, _ = model(data.view(data.size(0), -1))
# 使用t-SNE可视化
tsne = TSNE(n_components=2)
encoded_tsne = tsne.fit_transform(encoded.cpu().numpy())
# 绘制散点图
plt.figure(figsize=(10, 10))
scatter = plt.scatter(encoded_tsne[:, 0], encoded_tsne[:, 1],
c=labels.cpu().numpy(), cmap='tab10')
plt.colorbar(scatter)
plt.show()
5. 使用双射的注意事项
-
架构设计注意事项
- 编码器和解码器应具有对称结构
- 避免过度压缩导致信息丢失
- 合理选择激活函数(ReLU, Sigmoid等)
-
训练策略
- 使用适当的学习率
- 注意梯度消失/爆炸问题
- 监控重建误差
-
评估指标
- 重建误差(MSE, MAE)
- 结构相似性(SSIM)
- 潜在空间的分布特性
-
常见问题及解决方案
- 过拟合:增加正则化
- 模糊重建:调整网络容量
- 训练不稳定:使用批归一化
-
应用建议
- 数据预处理很重要
- 根据任务调整潜在空间维度
- 考虑使用变分自编码器(VAE)改进
使用示例:
# 初始化模型
model = AutoEncoder()
model.to(device)
# 训练模型
train_autoencoder(model, train_loader, num_epochs=50)
# 可视化重建结果
sample_data = next(iter(train_loader))[0][:10]
visualize_reconstruction(model, sample_data)
# 分析潜在空间
full_data = torch.cat([data for data, _ in train_loader])
full_labels = torch.cat([labels for _, labels in train_loader])
analyze_latent_space(model, full_data, full_labels)
这个案例展示了如何在自编码器中应用双射原理,通过合理的架构设计和训练策略,实现高质量的图像压缩和重建。双射特性确保了信息的可逆性,这对于图像处理和特征学习任务至关重要。


















 4438
4438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











