







# 1.导入
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验。
首先,使用训练数据进行学习,寻找最优的参数;
然后,使用测试数据评价训练得到模型的实际能力。
神经网络的“学习”是指从训练数据中自动获取最优权重参数的过程。
损失函数是表示神经网络性能“恶劣程度”的指标,即当前神经网络对监督数据(训练数据)多大程度上不拟合。简单来讲,就是损失函数值越小,代表权重参数越优。
损失函数可以使用任意函数,一般使用均方误差和交叉熵误差等。
# 2.交叉熵误差函数的介绍与实现
交叉熵误差函数的数学式如下图所示
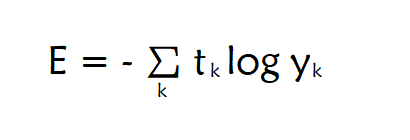
上图中yk表示神经网络的输出,tk表示正确解标签。比如在识别MNIST数据集的例子中,k的取值是0到9,yk表示一个图像的推理结果数组y中的y[k],tk表示这个图像的正确解标签t中的t[k]。(正确解标签按照one-hot形式表示,比如标签“2”用数组[0,0,1,0,0,0,0,0,0,0]表示。在one-hot形式下,实际上交叉熵误差函数就是对对应正确解标签的输出结果先取对数再取负)
单个数据的交叉熵误差函数的实现如下
# 单个数据的交叉熵误差的实现
def cross_entropy_error(y,t): # 入口参数为一个图像的推理结果,和该图像的正确解标签
delta = 1e-7 # 定义微小值delta(为防止出现np.log(0)导致负无穷大而无法计算)
return -np.sum(t*np.log(y+delta)) # y,t均为numpy数组
# np.log(y+delta)表示y数组每个元素加上微小值后取对数,得到一个新数组
# t*np.log(y+delta)表示将上述得到数组与t数组各个对应元素相乘,得到一个新数组
# -np.sum(t*np.log(y+delta))表示将上述得到数组中各元素求和并取负,得到最终的损失函数值
N个数据的平均交叉熵误差函数的数学式如下图所示
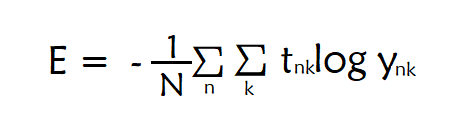
tnk表示第n个数据的正确解标签中第k个元素的值,ynk表示第n个数据的推理结果中第k个元素的值。
N个数据的平均交叉熵误差函数的实现如下
# mini-batch版交叉熵误差的实现
def cross_entropy_error(y,t): # 入口参数为批数量图像的推理结果,和批数量图像的正确解标签
if y.ndim == 1: # 当推理数组y的维度为1时(即只有一张图像时)
t = t.reshape(1,t.size) # 将标签数组t的形状修改为1*10
y = y.reshape(1,y.size) # 将推理数组y的形状修改为1*10
batch_size = y.shape[0] # 取出批数量(即y数组所囊括的图像数目)赋给batch_size
return -np.sum(t*np.log(y+1e-7))/batch_size # ...同单个数据交叉熵误差的解析相同
# -np.sum(t*np.log(y+1e-7))/batch_size表示将上述得到数组中各元素求和,再除以批数量batch_size再取负,得到批数据的平均交叉熵误差
# 本博客参考了《深度学习入门——基于Python的理论与实现》(斋藤康毅著,陆宇杰译),特在此声明。

















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









