







**
运算符
**
a = 10
b = 20
print(a / b) #0.5
print(a // b) #0 取整运算 向下取整 即 只取整数部分
print(a % b) #10
print(a ** b) #100000000000000000000
**
Any 和 All
**
def all_number_gt_10(numbers):
if not numbers:
return False
for n in numbers:
if n < 10:
return False
return True
numbers = [10, 11, 15]
print(all_number_gt_10(numbers)) #true
def all_number_gt_10(numbers):
return not all(n < 10 for n in numbers) #true
all(seq)当所有seq内容都是真时返回true
any(seq)当存在seq内容是真返回true
**
try/while else
**
def doSomething():
print("start 1 ......")
flag = False
try:
print("try ......")
flag = True
except Exception as e:
print("catch ......")
return
if flag == True:
print("if ......")
**
try else
**
else只会在没有异常的时候执行,如果程序出错,进入except,就不会执行else
while else
else 当循环条件不满足的时候,就会执行else语句
def doSomething():
print("start ......")
try:
print("try ......")
1/0
except Exception as e:
print("except .......")
else:
print("else ......")
doSomething()
is 和==
a = 1
b = 1
print(a == b) T
print(a is b) T
c = d = [1, 2, 3]
e = [1, 2, 3]
print(c == e) T
print(c is d) T
print(c is e) F
基数值和字符串类型比较并没有差别
== 只是单纯的比较值,而 is 还会比较id(内存地址)是否相同
**
And 和 Or
**
print(True or False and False) True
print((True or False) and False) False
And的优先级高于Or
**
字符串操作
**
str = "learning python"
print(str.center(30, "-")) #-------learning python--------
print(str.ljust(30, "*")) #learning python***************
print(str.zfill(30)) #000000000000000learning python
30 指的是总宽度为三十
print(str.title()) # Learning Python
print(str.swapcase()) # LEARNING PYTHON
print(str.capitalize()) # Learning python
**
list
**
ll = [1, 2, 3, 4, 'a', 'b']
ll.append(1)
ll.append(['q','w'])
ll.append(*['q','w'])
print(ll) #[1, 2, 3, 4, 'a', 'b', 1, ['q', 'w']]
添加
append 是整体添加,添加在列表最后,所以*['q','w']会报错,*相当于将元素打散,不再是一个整体
ll.insert(3,'x')
ll.extend(2) #TypeError: ‘int’ object is not iterable
extend 是单个参入参数必须是可迭代的对象 2不可迭代 ‘a’可以迭代
ll.extend("abc") #相当于一次插入 ‘a’,‘b’,‘c’ 并不是 ‘abc’
**
删除
**
pop 和 remove
pop 传递的参数是索引值,默认最后一个索引,有返回值,返回索引指向的具体元素
remove 传递的参数是具体的元素,如果该元素不存在就会报错,没有返回值,
ll[2] = ‘c’ 直接修改值
**
查找
**
如果不存在会抛出异常
print(ll.index('x'))
print(ll.index('x', 5, 10))
**
枚举
**
for i, x in enumerate(ll, 10):
print(i,x)
输出:

for i in enumerate(ll):
print(i)
输出: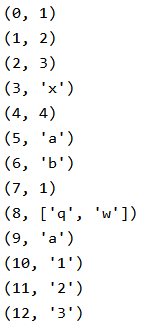
**
统计
**
print(ll.count(1))
输出 list中1的个数
**
浅拷贝和深拷贝
**
浅拷贝

有共享的内存地址,引用的对象都是一个,如果一方改变,会引起另一方的变化
深拷贝
深拷贝不会复制任何引用,而是将值赋值过来,值是相同的,但是id不是相同的,即不是一个对象,所以一方改变,不会影响到另一方的值
import copy
l2 = copy.deepcopy(ll)
字典
ll = {'name': 'albert', 'age': '18', 'gender': 'male'}
a = ll.fromkeys(ll, 'hello') # {'name': 'hello', 'age': 'hello', 'gender': 'hello'}
print(a)
必须是可迭代类型作为key
b = dict.fromkeys("name", 'll') # {'n': 'll', 'a': 'll', 'm': 'll', 'e': 'll'}
print(b)
删除元素
print(ll.pop('name')) #必须传递一个key,返回的是对应的value,删除不存在的key,会报keyserror的错误
print(ll.popitem()) #随机删除,返回k-v对,一般是最后一对
添加/修改元素
ll = {'name': 'albert', 'age': '18', 'gender': 'male'}
setdefault方法,至添加,不修改
ll.setdefault('name', 'jack') # name对应的值还是 albert
update方法,既添加也修改
ll.update({"name": "rose"})
查找元素
print(ll.get('age')) #找不到不报错
**
枚举
**
for i in enumerate(ll):
print(i)
#(0, 'name')
#(1, 'age')
#(2, 'gender')
**
拿到 keys
**
print(ll.items())
#dict_items([('name', 'albert'), ('age', '18'), ('gender', 'male')])
for k, v in ll.items():
print(k, v)
# name albert
# age 18
# gender male
**
集合
**
集合中的元素:
不可变、无序、不重复
cl1 = {'jack', 'tom', 'amy', 'rose'}
cl2 = {'jack', 'tom', 'jerry'}
print(cl1 & cl2) # 交集{'jack', 'tom'}
print(cl1 | cl2) # 并集
print(cl1 - cl2)
print(cl1 ^ cl2) #{'amy', 'rose','jerry'}
**
布尔类型
**
所有的数据都自带布尔值,None,0,空 三种情况下都是false
其余情况为true
**
元组
**
namedtuple
通过这种方法创建出来的p 和point都不是元组类型
from collections import namedtuple
point = namedtuple('p', ['x', 'y'])
p = point(1, 2)
print(p.x) # 1
print(p.y) # 2
创建空元组
t = ()
只有一个元素的时候,后面要加上逗号,否则不是元组类型
print(type((1))) #<class 'int'>
print(type((1,))) #<class 'tuple'>
元组也可以通过下标来进行访问
print(t(0:2))
元组不可以修改
删除元组
del t
双向列表
from collections import deque
d = deque("abcd")
d.append("s")
d.appendleft("z")
print(d) #deque(['z', 'a', 'b', 'c', 'd', 's'])
还有extend extendleft,pop popleft 等方法
**
文件操作
**
读取文件路径,要写双斜杠,\ 或者在前面加 r \ 就不会转义
f = open("E:\\PycharmProjects\\PythonLearning\\file\\a.txt", "r", encoding="utf-8")
f = open(r"E:\PycharmProjects\PythonLearning\file\a.txt", "r", encoding="utf-8")
光标移动3个字节读取,一个汉字占三个字节,所以汉字要是3的倍数移动,英文字母占一个字节
with open("E:\\PycharmProjects\\PythonLearning\\file\\a.txt", "rb") as f:
f.seek(3)
print(f.read().decode("utf-8"))
**
文件重命名和文件删除
**
import os
os.rename("a.txt","b.txt")
os.remove("c.txt")
**
迭代器
**
str,list,tuple,dict,set,file都是可迭代对象, 内置有iter方法
str = 'abc0' #可迭代对象
str_iter = str.__iter__() #迭代器对象
print(str_iter.__next__())
迭代器的优点
1.不依赖索引
2.迭代器更省内存
迭代器的缺点
1.迭代器只能向后,不能向前
2.无法使用len获取迭代器的长度 len( iter)会报错
**
生成器
**
生成器的本质就是迭代器
yield为我们提供了一种自定义的迭代器方式,可以在函数内使用yield,结果就是拿到一个生成器
yield可以像return一样用于返回值,return只能返回一次,yield可以返回多次
def test_yeild():
yield 1
yield 2
yield 3
print(test_yeild().__next__())
def eat(name):
print('[1] %s is ready for eating ' % name)
while (True):
food = yield
print('[2] %s starts to eat %s' % (name, food))
person1 = eat('Albert') 只执行之一步,什么也不输出,程序暂停在food = yield这一行
person1.__next__() #[1] Albert is ready for eating
person1.__next__() #[2] Albert starts to eat None yield是none,所以food是none
send方法,可以给yeild传值
def eat(name):
print('[1] %s is ready for eating ' % name)
while (True):
food = yield
print('[2] %s starts to eat %s' % (name, food))
person1 = eat('Albert')
person1.__next__() #[1] Albert is ready for eating
person1.send("大鱼大肉") #[2] Albert starts to eat 大鱼大肉
person1.__next__() #[2] Albert starts to eat None
**
匿名函数
**
匿名函数,冒号左边是参数,右边是返回值,不需要写return,直接返回值
f = lambda x, y: x ** y
print(f) # <function <lambda> at 0x02E5E930>
print(f(2, 3)) # 8
如果匿名函数没有返回值,那这个函数是没有意义的
f1 = lambda x, y: print("---------------------") # ---------------------
print(f1(2, 3)) # None
salaries = {
"james": 200000,
"rose": 1000000,
"jerry": 123000000}
def get(k):
return salaries[k]
print(max(salaries, key=get))
print(min(salaries, key=get))
print(max(salaries, key=lambda x: salaries[x]))
print(sorted(salaries, key=lambda x: salaries[x], reverse=True))
#['jerry', 'rose', 'james']
from functools import reduce
nums = [1, 2, 3, 5, 6]
new_nums = map(lambda x: x * 2, nums)
print(list(new_nums)) #[2, 4, 6, 10, 12]
new_nums = filter(lambda x: x > 3, nums)
print(list(new_nums)) #[5, 6]
new_nums = reduce(lambda x, y: x + y, nums)
print(new_nums) #17
计算1+2+3+。。+9
print(reduce(lambda x, y: y + x, range(1, 10)))
format 和 %
两者都可以用作对象属性格式化,都可以用作占位符,format实现功能更多
position = (100, 50)
print("the position is {}".format(position)) #the position is (100, 50)
print("the position is %s" %position) 报错
name = "Albert"
print(f"the name is {name}") #the name is Albert 注意字符串前面的f,f-string这种写法,只在3.6之后才有
^,<,> 分别是居中,左对齐,右对齐,默认是空格补充,可以指定一个字符补充
print("{:<10}".format('18'))
print("{:*^10}".format('18'))
print("{:**^10}".format('18')) #报错
print("{:.5f}".format(1.235654)) 保留5位
print("{:,}".format(12345687)) 千位分割 12,345,687
print("{:b}".format(18)) 转换成二进制
print("{:d}".format(18)) 十进制
print("{:o}".format(18)) 八进制
print("{:x}".format(18)) 十六进制
列表生成式
ll = []
for i in range(2000000):
ll.append(i)
ll = [i for i in range(2000000)]
使用列表生成式的方式,速度可以加快很多
ll = (i for i in range(100000000000000)) 改成小括号返回值是一个生成器print(ll.__next__()) 这样就可以防止数据量过大,造成程序运行缓慢















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









