







- 导入sklearn的决策树、红酒数据集、训练测试切分模块,以及画图的pandas模块
import pandas as pd
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
- 加载红酒数据集
wine=load_wine()
- 对红酒数据集的数据和类别进行连接操作(格式化)
da=pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
da
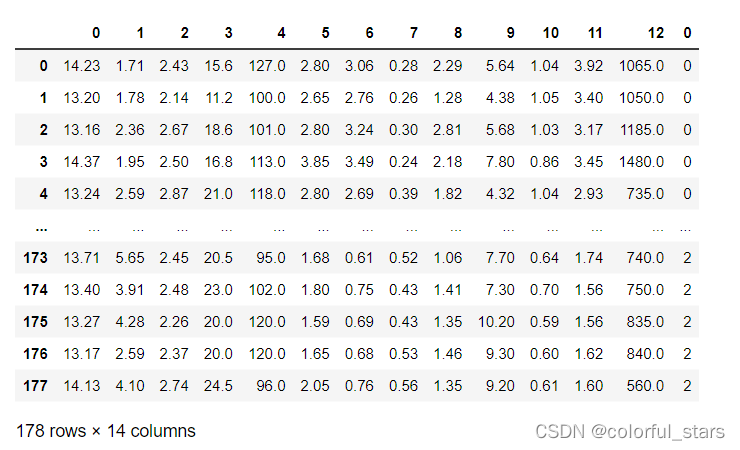
- 红酒的所有特征属性
wine.feature_names
[‘alcohol’,
‘malic_acid’,
‘ash’,
‘alcalinity_of_ash’,
‘magnesium’,
‘total_phenols’,
‘flavanoids’,
‘nonflavanoid_phenols’,
‘proanthocyanins’,
‘color_intensity’,
‘hue’,
‘od280/od315_of_diluted_wines’,
‘proline’]
- 红酒的类别
wine.target_names
array([‘class_0’, ‘class_1’, ‘class_2’], dtype=‘<U7’)
- 对红酒数据集进行拆分,30%作为测试集,
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
- 训练集和测试集的数据形状
Xtrain.shape
Xtest.shape
注意:Ytrain是红酒的类别数据
- 实例化决策树
clf=tree.DecisionTreeClassifier(criterion="entropy")#实例化
- 导入训练数据对模型进行训练
clf=clf.fit(Xtrain,Ytrain)
- 查看该模型在测试集上的评分
score=clf.score(Xtest,Ytest)
score
- 导入画图相关的包
import graphviz
from sklearn import tree
import matplotlib.pyplot as plt
font_name = 'SimSun'
# 设置 matplotlib 的默认字体
plt.rcParams['font.family'] = font_name
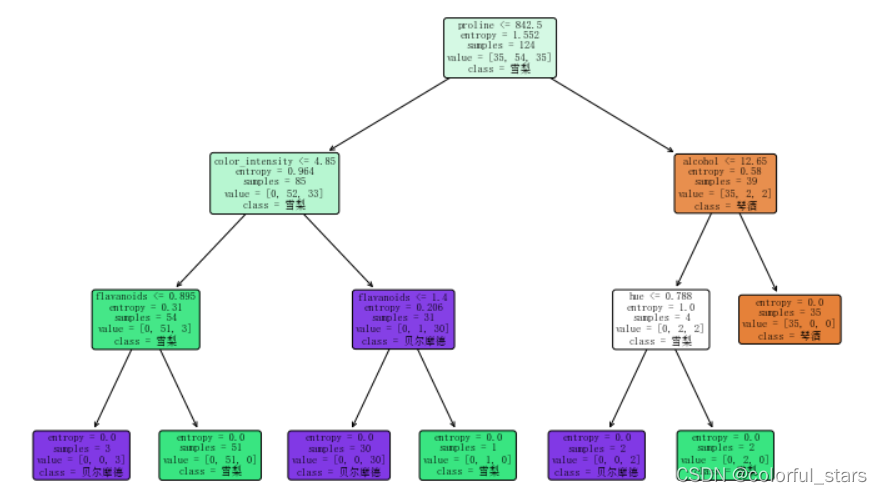
- 以图的方式展示当前模型下的决策树
dot_data = tree.export_graphviz(clf, feature_names=wine.feature_names, class_names=['琴酒', '雪梨', '贝尔摩德'], filled=True, rounded=True, out_file=None)
fig = plt.figure(figsize=(12, 8))
_ = tree.plot_tree(clf, feature_names=wine.feature_names, class_names=['琴酒', '雪梨', '贝尔摩德'], filled=True, rounded=True)
plt.show()
注意/;filled属性表示是否对方格进行填充
rounded表示,是否将矩形转变为圆角
13. 查看当前模型中,每个属性的重要性
clf.feature_importances_

14. 将每个特征的重要性与其名字对应,更直观的展示
[*zip(wine.feature_names,clf.feature_importances_)]

由于以上模型在训练的时候可能不稳定,每次训练的分数不一,为了取得更稳定的训练效果,对数据集随机切分
clf=tree.DecisionTreeClassifier(criterion="entropy"
,random_state=0
,splitter="random")#实例化
clf=clf.fit(Xtrain,Ytrain)
score=clf.score(Xtest,Ytest)
score
此时得到更加稳定的训练结果
在一些情况下,训练的模型可能会过拟合,导致树的层数较高。或者决策树的叶子节点/中间节点的样本个数较少,导致训练的结果过拟合等情况。可通过限定树的最大高度和叶子节点/中间节点的最少样本数,来协调解决该问题。
clf=tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
,max_depth=3
,min_samples_leaf=5
,min_samples_split=5
)
clf=clf.fit(Xtrain,Ytrain)
dot_data = tree.export_graphviz(clf
, feature_names=wine.feature_names
, class_names=['琴酒', '雪梨', '贝尔摩德']
, filled=True
, rounded=True
, out_file=None
)
fig = plt.figure(figsize=(22, 18))
_ = tree.plot_tree(clf
, feature_names=wine.feature_names
, class_names=['琴酒', '雪梨', '贝尔摩德']
, filled=True
, rounded=True)
plt.show()
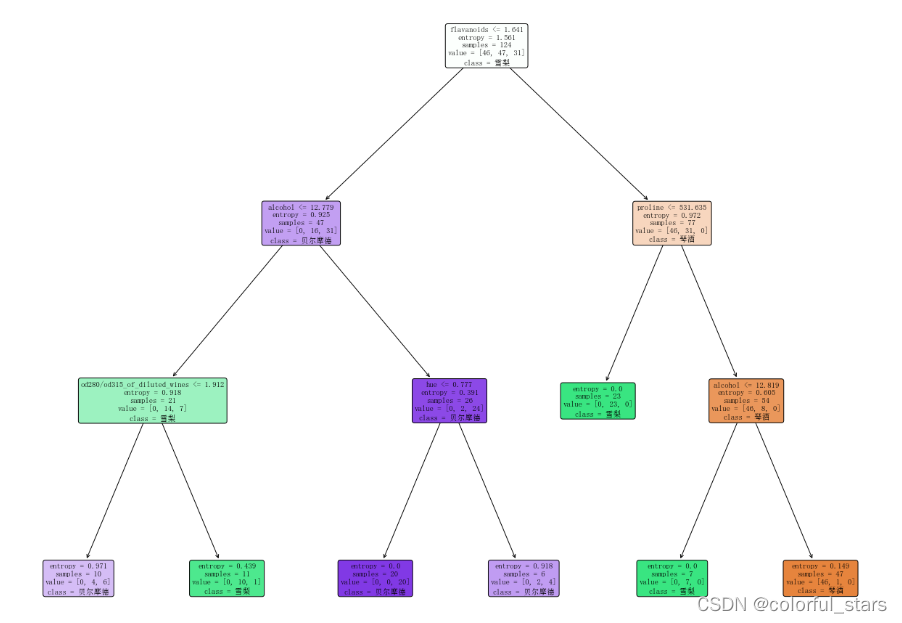
此时,模型可能相对于过拟合会有所改进
score=clf.score(Xtest,Ytest)
score















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











