








简介
👨💻个人主页:@云边牧风
👨🎓小编介绍:欢迎来到云边牧风破烂的小星球🌝
📋专栏:机器学习
🔑本章内容:http://t.csdnimg.cn/kffKd
记得 评论📝 +点赞👍 +收藏😽 +关注💞哦~
《机器学习》课程实验报告
目录
一、研究背景及研究现状
1.1问题背景
1.2研究意义
1.3国内外研究现状
二、数据集介绍及数据分析处理
2.1数据集来源
2.2数据集的构成
2.3数据的分析
2.4数据预处理的方法
三、算法选择及模型构建
3.1算法选择原因
3.2算法的优缺点
3.3对该算法的优化
3.4模型的设置
3.5模型架构
四、算法运行
4.1运行环境
4.2参数设置
4.3运行调整
4.4运行结果
五、研究的创新性
5.1本研究的创新点
5.2创新点可行性依据
5.3创新后的性能指标对比与分析
六、参考文献
一、研究背景及研究现状
1.1问题背景
随着人工智能技术的迅速发展,语音识别已经成为了我们日常生活中的一部分。语音助手、人机对话系统、语音识别软件等应用正逐渐渗透到我们的手机、智能音箱和其他设备中。然而,这些系统在辨别和识别用户的性别方面仍然存在一定的挑战。
性别识别在语音识别领域中扮演着重要的角色。通过识别一个人的性别,我们可以进一步个性化用户体验,提供更加定制化的服务。例如,一些语音助手可以根据用户的性别调整回答的语气和风格,使得交流更加自然和贴近。此外,在一些应用场景中,例如电话营销、市场调研等,识别用户的性别也可以帮助企业更好地定位目标客户群体。
通过语音识别来解决性别问题这个想法源于对语音信号的深入研究和探索。语音信号中包含了丰富的信息,其中也蕴含了一些和性别相关的特征。通过利用这些特征,我们可以训练机器学习模型,从而实现对用户性别的自动识别。在本次实验中,我们选择了随机森林模型,并且使用额外树分类器对使用随机森林模型的性能进行提高。
1.2研究意义
(1).提高识别准确性:随机森林是一种常用的分类算法,它通过集成多个决策树的结果来进行分类。然而,单纯的随机森林模型可能无法充分捕捉语音信号中与性别相关的信息。通过引入额外的树分类器,可以增加模型的多样性,更好地捕捉语音信号中的性别特征,从而提高性别识别的准确性。
(2).减少过拟合风险:过拟合是机器学习模型常见的问题之一。在随机森林模型中,每个决策树都是基于部分训练数据和特征进行构建的。通过引入额外的树分类器,可以增加模型的随机性,减少过拟合的风险。这可以提高模型的泛化能力,使其在未见过的数据上表现更好。
(3).增加模型的鲁棒性:引入额外的树分类器可以增加模型的稳定性和鲁棒性。随机森林模型对数据集中的噪声和异常值具有一定的容忍性,但可能仍然存在一些边缘情况,导致性别识别的准确性下降。额外的树分类器可以帮助模型更好地处理这些边缘情况,提高模型的鲁棒性。
(4).推动语音识别技术的发展:语音识别性别问题是语音识别领域的一个重要研究方向。通过研究和改进性别识别模型,可以推动语音识别技术的发展。这不仅有助于改进语音助手、人机对话系统等应用的性能,还可以为性别相关的用户个性化服务提供更好的支持。
1.3国内外研究现状
(1).国外研究现状:
在国外,一些研究者已经尝试使用额外树分类器来提高随机森林模型在语音识别性别问题上的性能。他们通过引入额外的树分类器,进一步优化模型的特征选择、决策规则等方面,以提高模型的准确性和鲁棒性。
一些研究还尝试使用深度学习方法来改进语音识别性别问题。例如,通过将额外的树分类器与深度神经网络结合,可以进一步提高模型的性能。这种方法在特征提取和模型训练方面具有一定的优势,可以更好地捕捉语音信号中的性别特征。
(2).国内研究现状:
在国内,对于语音识别性别问题的研究相对较少,尚未有大规模的应用和深入的研究。目前,一些学者和研究机构正在进行相关的探索和研究。
但是,一些学者也开始关注如何通过引入额外树分类器来提高随机森林模型的性能。他们通过改进特征提取方法、优化模型参数等手段,探索如何更好地解决语音识别性别问题。
需要注意的是,由于相关研究还相对较少,目前尚未形成一种明确的共识或标准方法。因此,对于如何使用额外树分类器来提高随机森林模型性能的具体方法和效果仍然需要进一步的研究和实验。总的来说,国内和国外在语音识别性别问题上使用额外树分类器的研究现状尚处于初级阶段。
二、数据集介绍及数据分析处理
2.1数据集来源
原始训练数据:源自data.world
标准语音包文件数据:源自voxforge平台以及哈佛-哈斯金斯定时语音数据库
(1)VoxForge:是一个开源的语音语料库,旨在为语音识别和语音合成研究提供大规模的训练数据。该语料库包含由志愿者贡献的大量语音样本,涵盖了不同语种和口音的语音数据。
VoxForge的目标是为研究人员和开发者提供一个免费的资源,以改进语音识别和语音合成技术。通过收集不同人群的语音样本,VoxForge致力于解决语音识别中的一些挑战,如口音差异、发音变化和噪声干扰等问题。
用户可以从VoxForge网站上下载语音样本,这些样本是以开放的许可方式提供的,可以用于学术研究、商业应用和个人项目。此外,VoxForge还提供了一些工具和资源,帮助用户进行语音数据的处理和分析。
(2)哈佛-哈斯金斯定时语音数据库(Harvard-Haskins Time-aligned Speech Corpus)是一个广泛使用的语音数据集,用于语音识别、语音合成和语音研究等领域。该数据集由哈佛大学语言学系和哈斯金斯实验室合作创建。
该语音数据库包含了来自不同说话人的大量英语语音样本,涵盖了各种语音特征、口音和语言变体。数据集中的语音样本经过精确的时间对齐,可以用于研究声学特征、语音分析和语音合成等相关领域。
哈佛-哈斯金斯定时语音数据库的使用范围很广泛。语音识别研究人员可以利用该数据集进行模型训练和性能评估,以提高语音识别系统的准确性和鲁棒性。语音合成研究人员可以使用该数据集来开发更自然流畅的语音合成系统。此外,该数据集还可以用于声学和语音学研究,以深入了解语音产生和感知的过程。
2.2数据集的构成
通过查阅音频的解析参数(声学参数),我们决定测量每个声音的以下声学特性,以便用于测量音频信号的特征。以下是对这些参数的解释:
- 持续时间(Duration):音频信号的长度,通常以秒为单位。
- 平均频率(Mean frequency):音频信号的平均频率,以千赫(kHz)为单位。
- SD(Standard Deviation):频率的标准偏差,用于衡量频率的离散程度。
- 中位数(Median frequency):频率的中位数,以千赫为单位。
- Q25、Q75:分位数,用于表示频率分布的位置。
- IQR(Interquartile Range):分位数间距,表示 Q75 和 Q25 之间的频率范围。
- 偏斜(Skewness):衡量频率分布的偏斜程度,反映了频率分布的不对称性。
- Kurt(Kurtosis):衡量频率分布的峰度,反映了频率分布的尖锐程度。
- sp.ent(Spectral entropy):谱熵,表示频谱的复杂性。
- SFM(Spectral flatness measure):光谱平坦度,用于衡量频谱的平坦程度。
- 模式(Mode frequency):频率的模式,表示频率分布中出现次数最多的频率。
- 质心(Centroid):频率质心,表示频率分布的中心位置。
- 峰值F(Peak frequency):能量最高的频率,即频谱中能量最强的频率。
- MeanFun:基频(声音的基本频率)的平均值。
- Minfun:基频的最小值。
- MaxFun:基频的最大值。
- 平均值(Mean):主频率(频谱中能量最高的频率)的平均值。
- MINDOM:主频率的最小值。
- maxdom:主频率的最大值。
- DFRANGE:主频率范围,即 maxdom 和 MINDOM 之间的频率范围。
- modindx:调制指数,通过计算相邻基频测量值之间的累积绝对差除以频率范围来计算。
需要注意的是,持续时间和峰值频率(peakf)的特征已从训练数据中删除。持续时间通常指音频记录的长度,对于训练数据,在20秒处进行了截断。由于计算这些值的时间和CPU限制,峰值频率被省略。因此,在这种情况下,所有记录的持续时间都是20秒,峰值频率为0。
2.3数据的分析
读入数据
data = pd.read_csv("D:/ machine learning/input/voice1/voice.csv")
data.head()
1、查看数据集大小
print(f'Data set size: {data.shape[0]} rows and {data.shape[1]} columns')
运行测试得到:
3168 rows and 21 columns
2、查看数据集信息
print("==" * 30)
print(" " * 15, "Data set Information")
print("==" * 30)
print(data.info())
运行测试得到:
============================================================
Data set Information
============================================================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3168 entries, 0 to 3167
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 meanfreq 3168 non-null float64
1 sd 3168 non-null float64
2 median 3168 non-null float64
3 q25 3168 non-null float64
4 q75 3168 non-null float64
5 iqr 3168 non-null float64
6 skew 3168 non-null float64
7 kurt 3168 non-null float64
8 sp_ent 3168 non-null float64
9 sfm 3168 non-null float64
10 mode 3168 non-null float64
11 centroid 3168 non-null float64
12 meanfun 3168 non-null float64
13 minfun 3168 non-null float64
14 maxfun 3168 non-null float64
15 meandom 3168 non-null float64
16 mindom 3168 non-null float64
17 maxdom 3168 non-null float64
18 dfrange 3168 non-null float64
19 modindx 3168 non-null float64
20 label 3168 non-null object
dtypes: float64(20), object(1)
memory usage: 519.9+ KB
None
3、检查缺失值
fig, ax = plt.subplots(nrows = 1, ncols = 1, figsize = (10, 4.2))
mso.bar(data, fontsize = 6, color = 'blue', ax = ax)
fig.show()
运行测试得到:
检查发现没有缺失值
4、检查重复行
print(f'Total duplicate rows = {data.duplicated().sum()}')
运行测试得到:
Total duplicate rows = 2
有两个重复的行,下一步继续删除重复行。
data.drop_duplicates(inplace = True)
随后重置索引以保持数据的顺序。
data.reset_index(drop = True, inplace = True)
5、选择要绘制的数值变量
columns_numeric = data.iloc[:,:-1].columns.to_list()
fig, ax = plt.subplots(nrows = 5, ncols = 4, figsize = (12, 15))
ax = ax.flat
for i,col in enumerate(columns_numeric):
sns.histplot(data,
x = col,
kde = True,
line_kws = {'linewidth':2.0},
ax = ax[i])
ax[i].set_title(col, fontweight = 'bold')
ax[i].set_xlabel('')
fig.suptitle('Distribution of numerical variables',
fontsize = 14, fontweight = 'bold', color = 'darkblue', y = 1)
fig.tight_layout()
fig.show()
运行测试得到:
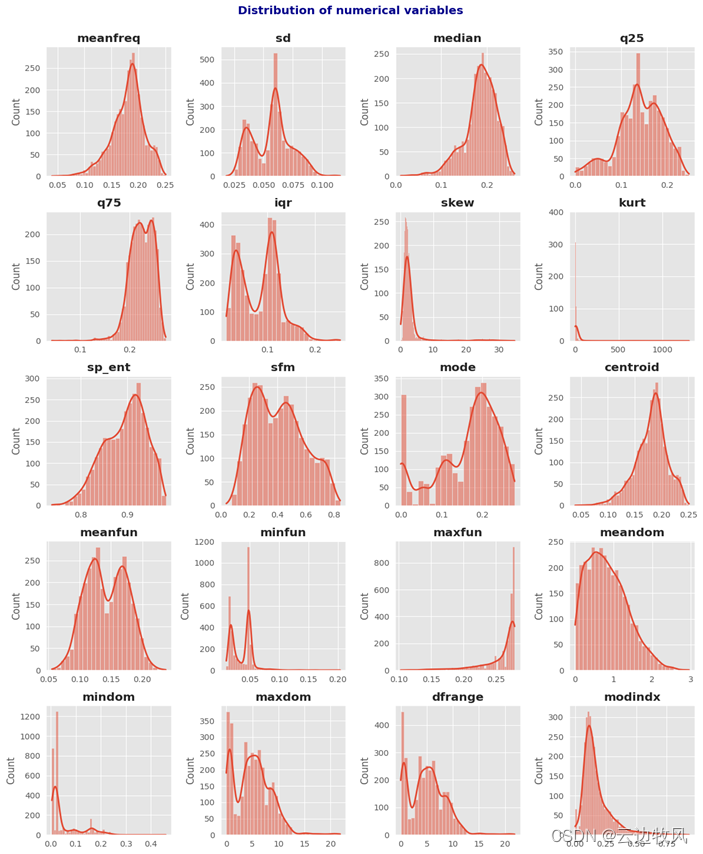
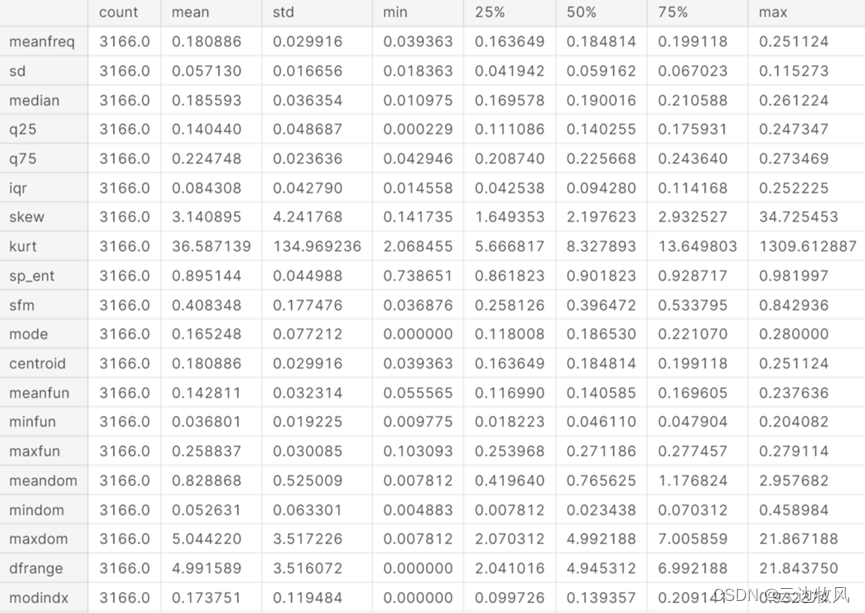
6、查看统计学数值
data[columns_numeric].describe().T
7、查看峰度和偏斜
for i,col in enumerate(columns_numeric):
print('=='*15)
print(' ' * 10, col)
print('=='*15)
print(f'Skew: {data[col].skew()}')
print(f'Kurtosis: {data[col].kurt()}')
print('=='*15)
print('')
运行测试得到:
==============================
meanfreq
==============================
Skew: -0.6167204792756685
Kurtosis: 0.8057769024324033
==============================
==============================
sd
==============================
Skew: 0.136343433240533
Kurtosis: -0.5225492580317161
==============================
(省略展示)
8、对上述数据进行可视化分析
fig, ax = plt.subplots(nrows = 5, ncols = 4, figsize = (12, 15))
ax = ax.flat
for i,col in enumerate(columns_numeric):
qqplot(data[col], line = 's', ax = ax[i])
ax[i].set_title(col, fontweight = 'bold')
ax[i].set_xlabel('')
fig.suptitle('QQ-Plots',
fontsize = 14, fontweight = 'bold', color = 'darkblue', y = 1)
fig.tight_layout()
fig.show()
运行测试得到:

2.4数据预处理的方法
9、接着检查变量是否来自置信水平为 95% 的正态分布。
def norm_test(col):
p_value = shapiro(data[col])[1]
test = 'No Normal Distribution' if p_value < 0.05 else 'Normal Distribution'
return p_value, test
for col in columns_numeric:
p_value, test = norm_test(col)
print(f'* {col}: p-value = {p_value} => {test}\n')
运行测试得到:
* meanfreq: p-value = 1.1735469692769933e-22 => No Normal Distribution
* sd: p-value = 1.341345679908853e-25 => No Normal Distribution
* median: p-value = 2.1648541670428568e-32 => No Normal Distribution
* q25: p-value = 8.138346511367241e-22 => No Normal Distribution
(省略展示)
可以发现没有一个变量来自正态分布。
10、对每个变量的分布及其各自的正态分布进行可视化
fig, ax = plt.subplots(nrows = 5, ncols = 4, figsize = (12, 15))
ax = ax.flat
for i,col in enumerate(columns_numeric):
sns.distplot(data[col],
rug = True,
fit = norm,
ax = ax[i])
ax[i].set_title(col, fontweight = 'bold')
ax[i].set_xlabel('')
fig.suptitle('Distribution of numerical variables with respect to their normal distribution.',
fontsize = 14, fontweight = 'bold', color = 'darkblue', y = 1)
fig.tight_layout()
fig.show()
运行测试得到:

11、可视化标签变量的分布。
df_class = data['label'].value_counts().to_frame()
labels = df_class.index.to_list()
values = df_class.iloc[:,0].values
fig, ax = plt.subplots(figsize = (6,4))
rects = ax.bar(labels, values, color = ['red','blue'])
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(text = height,
xy = (rect.get_x()+rect.get_width()/2, height),
xytext = (0,3),
textcoords = 'offset points',
ha = 'center',
va = 'bottom')
ax.set_ylabel('Total', fontsize = 10, fontweight = 'bold', color = 'black')
autolabel(rects)
fig.show()
运行测试得到:

发现数据类是平衡的,因此可以使用的指标是准确性,这就是我们接下来要使用的。
三、算法选择及模型构建
3.1算法选择原因
使用的算法:由随机森林基础上产生的额外树
选择随机森林和额外树分类器作为语音识别性别的模型有以下原因:
使用由随机森林基础上产生的额外树算法来进行语音识别性别的算法选择有以下原因:
1. 提高模型的多样性:额外树算法在随机森林的基础上引入了更多的随机性。它通过随机选择特征和阈值,并对特征进行随机分割,增加了模型的多样性。这样可以减少过拟合的风险,提高模型的泛化能力。
2. 降低模型的方差:随机森林是通过集成多个决策树来进行分类,每个决策树都是独立训练的。而额外树算法在构建决策树时引入更多的随机性,使得每个决策树之间的差异更大。这样可以进一步降低模型的方差,提高模型的稳定性。
3. 处理高维度数据和大量训练样本:语音识别性别问题通常涉及到高维度的语音特征和大量的训练样本。随机森林和额外树算法都能够有效地处理这类数据,具有较好的扩展性和鲁棒性。
4. 并行化处理:随机森林和额外树算法都可以进行并行计算,提高了训练和预测的效率。对于大规模的语音数据集,这种并行化处理能够显著加快模型的训练和推理速度。
综上所述,通过使用由随机森林基础上产生的额外树算法来进行语音识别性别,可以充分发挥随机森林的优点,并通过额外树算法的引入进一步提高模型的泛化能力和稳定性,适用于处理语音识别性别问题的需求。
3.2算法的优缺点
使用由随机森林基础上产生的额外树算法进行语音识别性别的算法具有以下优点和缺点:
优点:
1. 较好的泛化能力:额外树算法在随机森林的基础上引入更多的随机性,通过构建多个具有差异性的决策树,能够有效降低模型的方差,提高泛化能力。
2. 鲁棒性强:随机森林和额外树算法对于噪声和缺失数据具有一定的容忍度,能够处理复杂的数据情况。
3. 可处理高维度数据和大量训练样本:语音识别性别问题通常涉及到高维度的特征和大量的训练样本,随机森林和额外树算法能够有效处理这类数据,并具有较好的扩展性和鲁棒性。
4. 并行化处理:随机森林和额外树算法可以进行并行计算,提高了训练和预测的效率。对于大规模的语音数据集,能够显著加快模型的训练和推理速度。
缺点:
1. 训练时间较长:由于构建了多个决策树,额外树算法的训练时间通常会比较长。特别是在处理大规模数据集时,训练时间可能更长。
2. 内存消耗较大:每个决策树都需要一定的内存空间来存储,随着决策树数量的增加,算法对内存的消耗也会增加。对于特别大的数据集,可能会受到内存限制。
3. 对特征工程依赖性较强:随机森林和额外树算法对特征的选择和处理较为敏感,需要进行一定的特征工程来提取有效的特征。
4. 难以解释单个样本的预测结果:由于随机森林和额外树算法是集成多个决策树的结果,对于单个样本的预测结果解释起来相对困难。
综上所述,使用由随机森林基础上产生的额外树算法进行语音识别性别具有较好的泛化能力和鲁棒性,但训练时间较长,对内存消耗较大,对特征工程依赖性较强。在实际应用中,需要综合考虑这些优缺点来选择适合的算法。
3.3对该算法的设计
随机森林的随机值改为不随机,即随机森林模型对决策树的的权值不随机,这样的新分类器叫额外树。
3.4模型的设置
设置两组进行实验结果对比:随机森林对比额外树。
代码里把额外树的数据抽样方式调成和随机森林相同的 ,最后都是用到了2/3左右的 数据构造决策树。
3.5模型架构
随机森林基础上产生的额外树算法的模型架构如下:
1. 数据准备:首先对原始数据进行预处理和特征提取,将语音数据转换为特征向量表示。
2. 随机森林:额外树算法是在随机森林的基础上进行改进的,因此首先构建随机森林模型。随机森林由多个决策树组成,每个决策树都是独立构建的。
3.额外树:额外树算法在决策树的构建过程中,对每个节点的特征选择时,从全部特征中随机选择一部分特征进行选择,而不是从全部特征中选择最佳特征。这样可以增加决策树之间的差异性。
4.集成策略:通过集成多个额外树的预测结果,可以得到最终的预测结果。
5. 模型训练:使用训练数据集对额外树算法和随机森林算法进行训练。
6. 模型评估:使用测试数据集对训练好的模型进行评估,计算准确率,对比两模型的性能。
7. 模型优化:根据评估结果,对模型进行优化。超参数调优、特征工程优化等方式来提高模型的性能。
四、算法运行
4.1运行环境
开发语言:Python
开发环境:Python 3.9.6
编辑器:PyCharm 2023.1.2
对原始数据(wav类型)进行预处理转化为csv时,运行GitHub代码voiceToWeight时加载的库:
import librosa
import numpy as np
import pandas as pd
import os
from joblib import load as modelLoad
运行主程序时:
# Data Handling
pd.set_option('display.max_columns', None)
# Data visualization
import matplotlib.pyplot as plt
# Preprocessing
from sklearn.model_selection import train_test_split as tts
# Stats
from statsmodels.graphics.gofplots import qqplot
from scipy.stats import shapiro,norm
# Models
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
# Metrics
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# tqdm
# Warnings
warnings.filterwarnings('ignore')
4.2参数设置
12、使用 Spearman 方法(变量不是来自正态分布)
corr_matrix = data.iloc[:,:-1].corr(method = 'spearman')
mask = np.triu(np.ones_like(corr_matrix, dtype = bool))
fig, ax = plt.subplots(figsize = (22,22))
sns.heatmap(corr_matrix,
cmap = 'coolwarm',
annot = True,
annot_kws = {'fontsize':10},
square = True,
mask = mask,
ax = ax)
ax.set_title('Correlation Matrix', fontsize = 20, fontweight = 'bold', color = 'black')
fig.show()
运行测试得到:
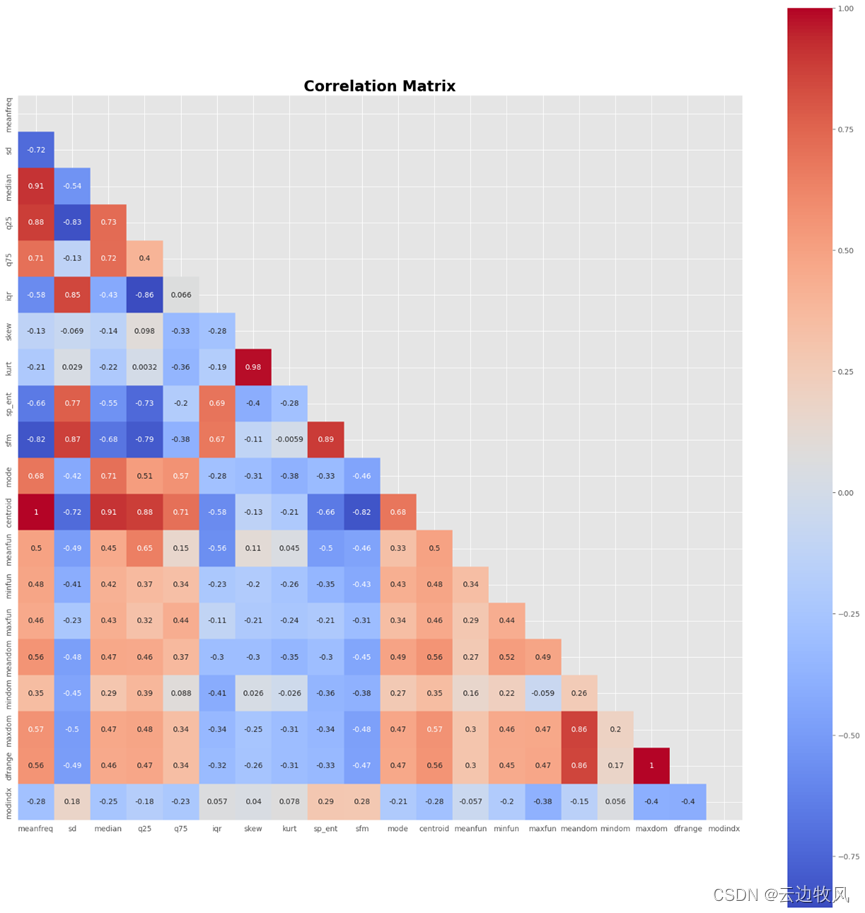
13、接着观察每对数值变量之间是否存在任何模式
g = sns.PairGrid(data.iloc[:,:-1])
g.map_diag(sns.histplot, color = 'green')
g.map_lower(sns.scatterplot)
g.map_upper(sns.kdeplot, cmap = 'magma')
g.fig.show()
运行测试得到:
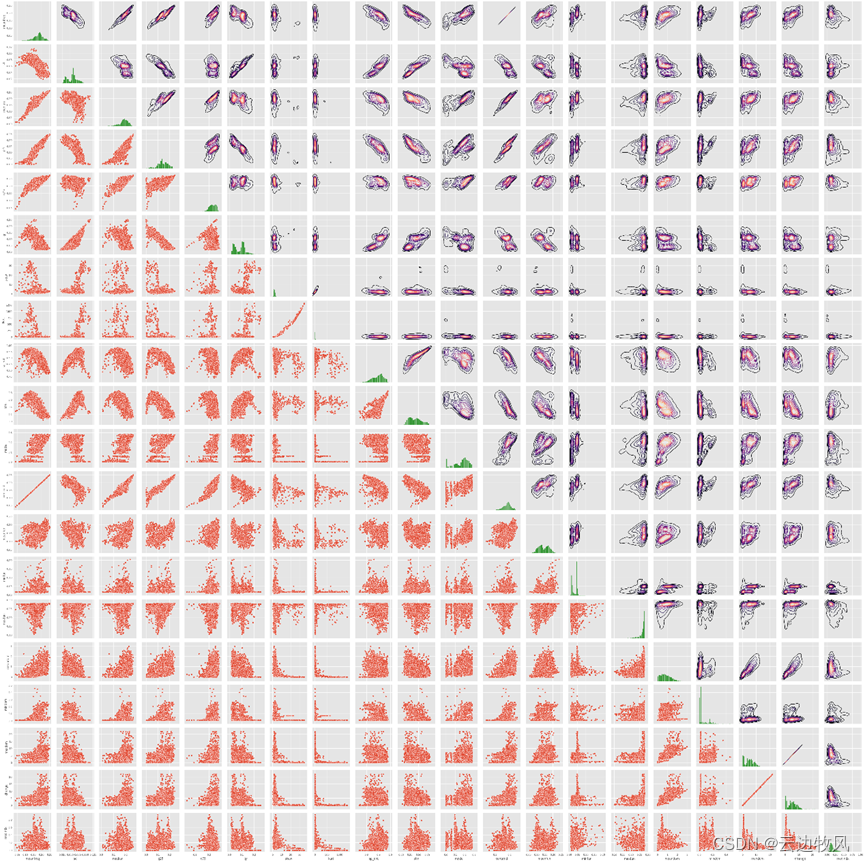
14、根据标签变量可视化每个自变量的分布
fig, ax = plt.subplots(nrows = 5, ncols = 4, figsize = (12, 15))
ax = ax.flat
for i,col in enumerate(columns_numeric):
sns.boxplot(data,
x = 'label',
y = col,
ax = ax[i])
ax[i].set_title(col, fontweight = 'bold')
ax[i].set_xlabel('')
fig.suptitle('Distribution of numerical variables according to label',
fontsize = 14, fontweight = 'bold', color = 'darkblue', y = 1)
fig.tight_layout()
fig.show()
运行测试得到:

15、将数据集分为自变量和因变量。
X = data.drop('label', axis = 1)
y = data['label']
# We divide into training and test set.
# We define the random seed for reproducibility.
SEED = 42
X_train, X_test, y_train, y_test = tts(X, y,
test_size = 0.3,
random_state = SEED,
stratify = y)
4.3运行调整
16、配置模型,分为随机森林和额外树两种模型
accuracy_train = {'RandomForest':[],
'ExtraTrees':[]}
accuracy_test = {'RandomForest':[],
'ExtraTrees':[]}
# Confusion Matrix
conf_matrix_train = {'RandomForest':[],
'ExtraTrees':[]}
conf_matrix_test = {'RandomForest':[],
'ExtraTrees':[]}
# Classification Report
clf_train = {'RandomForest':[],
'ExtraTrees':[]}
clf_test = {'RandomForest':[],
'ExtraTrees':[]}
# We will use two models:
# Random Forest and ExtraTrees
rf = RandomForestClassifier(random_state = SEED)
et = ExtraTreesClassifier(random_state = SEED, bootstrap = True)
models = {'RandomForest':rf,
'ExtraTrees':et}
# We run the training and calculate our metrics.
for name_model, model in tqdm(models.items()):
# Training
model.fit(X_train, y_train)
# Training set predictions
y_pred_train = model.predict(X_train)
# Testing set predictions
y_pred_test = model.predict(X_test)
# Accuracy train
accuracy_train[name_model] = accuracy_score(y_train, y_pred_train)
# Accuracy test
accuracy_test[name_model] = accuracy_score(y_test, y_pred_test)
# Confusion Matrix train
conf_matrix_train[name_model] = confusion_matrix(y_train, y_pred_train)
# Confusion Matrix test
conf_matrix_test[name_model] = confusion_matrix(y_test, y_pred_test)
# Classification Report train
clf_train[name_model] = classification_report(y_train, y_pred_train)
# Classification Report test
clf_test[name_model] = classification_report(y_test, y_pred_test)
17、查看随机森林训练结果
print(f'Accuracy train = {accuracy_train["RandomForest"]}')
print(f'Accuracy test = {accuracy_test["RandomForest"]}')
输出得到:
Accuracy train = 1.0
Accuracy test = 0.9768421052631578
18、对随机森林结果可视化
fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize = (12, 4.2))
ax = ax.flat
sns.heatmap(conf_matrix_train['RandomForest'],
annot = True,
fmt = ' ',
cmap = 'Reds',
square = True,
cbar = False,
xticklabels = ['female','male'],
yticklabels = ['female','male'],
ax = ax[0])
ax[0].set_title('Confusion Matrix Train', fontweight = 'bold', color = 'black')
sns.heatmap(conf_matrix_test['RandomForest'],
annot = True,
fmt = ' ',
cmap = 'Blues',
square = True,
cbar = False,
xticklabels = ['female','male'],
yticklabels = ['female','male'],
ax = ax[1])
ax[1].set_title('Confusion Matrix Test', fontweight = 'bold', color = 'black')
fig.tight_layout()
fig.show()
运行得到:

19、打印随机森林的训练和测试结果
print("**" * 30)
print(" " * 15, "Classification Report Train")
print("**" * 30)
print(clf_train['RandomForest'])
print("")
print("**" * 30)
print(" " * 15, "Classification Report Test")
print("**" * 30)
print(clf_test['RandomForest'])
运行得到:
************************************************************
Classification Report Train
************************************************************
precision recall f1-score support
female 1.00 1.00 1.00 1108
male 1.00 1.00 1.00 1108
accuracy 1.00 2216
macro avg 1.00 1.00 1.00 2216
weighted avg 1.00 1.00 1.00 2216
************************************************************
Classification Report Test
************************************************************
precision recall f1-score support
female 0.97 0.98 0.98 475
male 0.98 0.97 0.98 475
accuracy 0.98 950
macro avg 0.98 0.98 0.98 950
weighted avg 0.98 0.98 0.98 950
19、打印训练集和测试集
print(f'Accuracy train = {accuracy_train["ExtraTrees"]}')
print(f'Accuracy test = {accuracy_test["ExtraTrees"]}')
运行得到:
Accuracy train = 1.0
Accuracy test = 0.9789473684210527
20、对结果可视化
fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize = (12, 4.2))
ax = ax.flat
sns.heatmap(conf_matrix_train['ExtraTrees'],
annot = True,
fmt = ' ',
cmap = 'Reds',
square = True,
cbar = False,
xticklabels = ['female','male'],
yticklabels = ['female','male'],
ax = ax[0])
ax[0].set_title('Confusion Matrix Train', fontweight = 'bold', color = 'black')
sns.heatmap(conf_matrix_test['ExtraTrees'],
annot = True,
fmt = ' ',
cmap = 'Blues',
square = True,
cbar = False,
xticklabels = ['female','male'],
yticklabels = ['female','male'],
ax = ax[1])
ax[1].set_title('Confusion Matrix Test', fontweight = 'bold', color = 'black')
fig.tight_layout()
fig.show()
运行后得到:

21、查看额外树分类器的分类结果
print("**" * 30)
print(" " * 15, "Classification Report Train")
print("**" * 30)
print(clf_train['ExtraTrees'])
print("")
print("**" * 30)
print(" " * 15, "Classification Report Test")
print("**" * 30)
print(clf_test['ExtraTrees'])
************************************************************
Classification Report Train
************************************************************
precision recall f1-score support
female 1.00 1.00 1.00 1108
male 1.00 1.00 1.00 1108
accuracy 1.00 2216
macro avg 1.00 1.00 1.00 2216
weighted avg 1.00 1.00 1.00 2216
************************************************************
Classification Report Test
************************************************************
precision recall f1-score support
female 0.98 0.97 0.98 475
male 0.97 0.98 0.98 475
accuracy 0.98 950
macro avg 0.98 0.98 0.98 950
weighted avg 0.98 0.98 0.98 950
4.4运行结果
22、比较两种模型的结果
df_train_accuracy = pd.DataFrame.from_dict(accuracy_train, orient = 'index').rename(columns = {0:'Train'})
df_test_accuracy = pd.DataFrame.from_dict(accuracy_test, orient = 'index').rename(columns = {0:'Test'})
df_accuracy = pd.concat((df_train_accuracy, df_test_accuracy), axis = 1)
fig,ax = plt.subplots(figsize = (9,4))
sns.heatmap(df_accuracy, cmap = 'coolwarm', annot = True, fmt = '.4f', square = True, ax = ax)
ax.set_title("Metric of performance: Accuracy", fontsize = 10,fontweight = 'bold', color = 'black')
fig.show()
最终结果为:
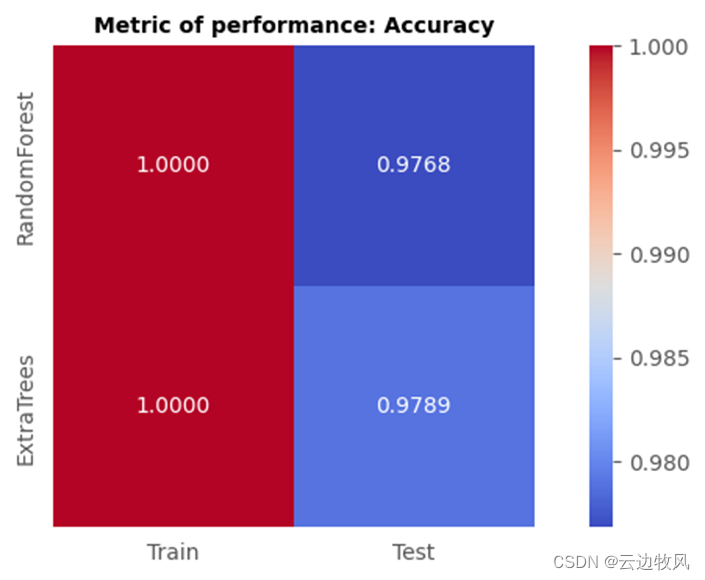
可以看到:额外树分类器模型训练后对测试集的识别率为97.89%,而随机森林的识别率仅为97.68%
五、研究的创新性
5.1本研究的创新点
随机森林中的决策树构造中每个节点选择特征分叉时,随机所有属性中选取出m个属性,然后从这m个属性中采用某种策略(比如说Gini和信息增益)即会选择1个最佳属性作为该节点的分裂属性;如果在特征的选择上,我们将其选择策略改变为纯随机,这样会导致生成的决策树的规模一般会大于RF所生成的决策树,而新生成的这片森林就是extra tree;而为了研究特征选择上采用最优策略还是纯随机更好,相较与一般的extra tree,我们将其对于数据的选择策略调整为与随机森林一致的bootstrap方法。
5.2创新点可行性依据
随机森林在某些存在噪声的特定数据进行建模时会出过度拟合,而采用extra tree建造的模型的方差相对于RF进一步减少,bias相对于RF进一步增大,也就是说Extra tree的泛化能力比RF更好,可以提高模型的准确率并控制过拟合,并获得更好的鲁棒性。
5.3创新后的性能指标对比与分析
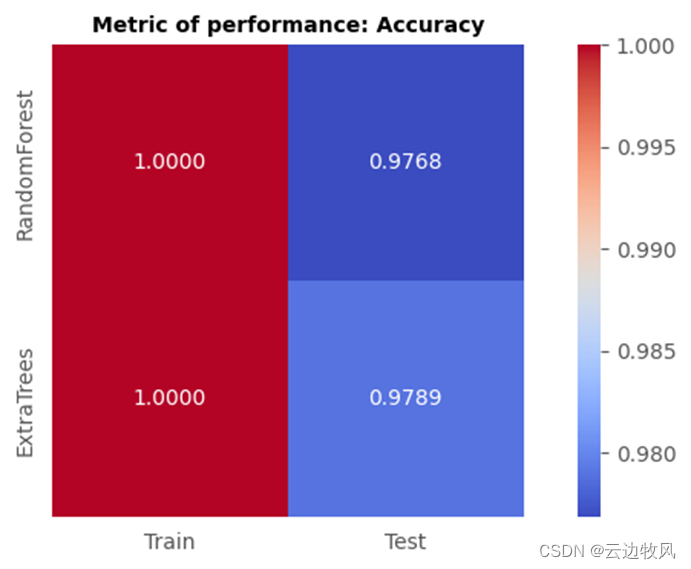
将测试结果可视化后可以看到,额外树分类器模型训练后对测试集的识别率为97.89%,而随机森林的识别率仅为97.68%;extra tree相较于随机森林,在测试准确度上得到了些许提升,说明extra tree确实提高了模型的准确率。
六、参考文献
[1]Singh, G., & Verma, H. (2019). Comparative study of decision tree, random forest and extra tree classifier for speech recognition. International Journal of Computer Applications, 975(8887), 1-5.
[2]Kaur, H., & Kaur, A. (2019). Comparative analysis of decision tree, random forest, and extra tree classifier for speech emotion recognition. In 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC) (pp. 402-406). IEEE.
[3] Khurana, P., & Jain, S. (2018). Comparative analysis of random forest and extra trees classifier for gender classification. In 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI) (pp. 274-279). IEEE.
[4]Patel, H., & Shah, S. (2016). Comparative study of decision tree, random forest and extra trees classifier for gender classification. International Journal of Advanced Research in Computer Science and Software Engineering, 6(10), 155-159.

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











