



1. LLM与向量模型之间的联系
LLM依赖于向量模型来表示和处理语言数据,而向量模型提供了一种数学框架来实现这一点。
2. 具体操作步骤
2.1 下载离线安装包后使用安装脚本正常部署MaxKB

2.2 安装完后在安装目录下创建相应目录为数据持久化做准备
mkdir -p /opt/maxkb/model
2.3 下载向量模型放到/opt/maxkb/model下
向量模型下载地址
MaxKB默认使用的是 moka-ai/text2vec ,还可以使用其他的向量模型,我使用的是m3e-large。具体模型之间的对比见下图:

我放置的向量模型位置如下图所示:

2.4 修改MaxKB的compose文件
编辑 /opt/maxkb/docker-compose.yml 文件
version: "3.9"
services:
maxkb:
container_name: maxkb
hostname: maxkb
restart: always
image: ${MAXKB_IMAGE_REPOSITORY}/maxkb:${MAXKB_VERSION}
# 这里是我添加的模型参数,指定对应你的模型(注意是要写容器内的模型应用地址)
environment:
- MAXKB_EMBEDDING_MODEL_NAME=/opt/maxkb/model/embedding/m3e-large
#
ports:
- "${MAXKB_PORT}:8080"
healthcheck:
test: ["CMD", "curl", "-f", "localhost:8080"]
interval: 10s
timeout: 10s
retries: 120
volumes:
- /tmp:/tmp
- ${MAXKB_BASE}/maxkb/logs:/opt/maxkb/app/data/logs
# 这里我把向量模型持久化出来了
- ${MAXKB_BASE}/maxkb/model:/opt/maxkb/model/embedding
env_file:
- ${MAXKB_BASE}/maxkb/conf/maxkb.env
depends_on:
pgsql:
condition: service_healthy
networks:
- maxkb-network
entrypoint: ["docker-entrypoint.sh"]
command: "python /opt/maxkb/app/main.py start"
networks:
maxkb-network:
driver: bridge
ipam:
driver: default
2.5 重启MaxKb服务
kbctl stop && kbctl start
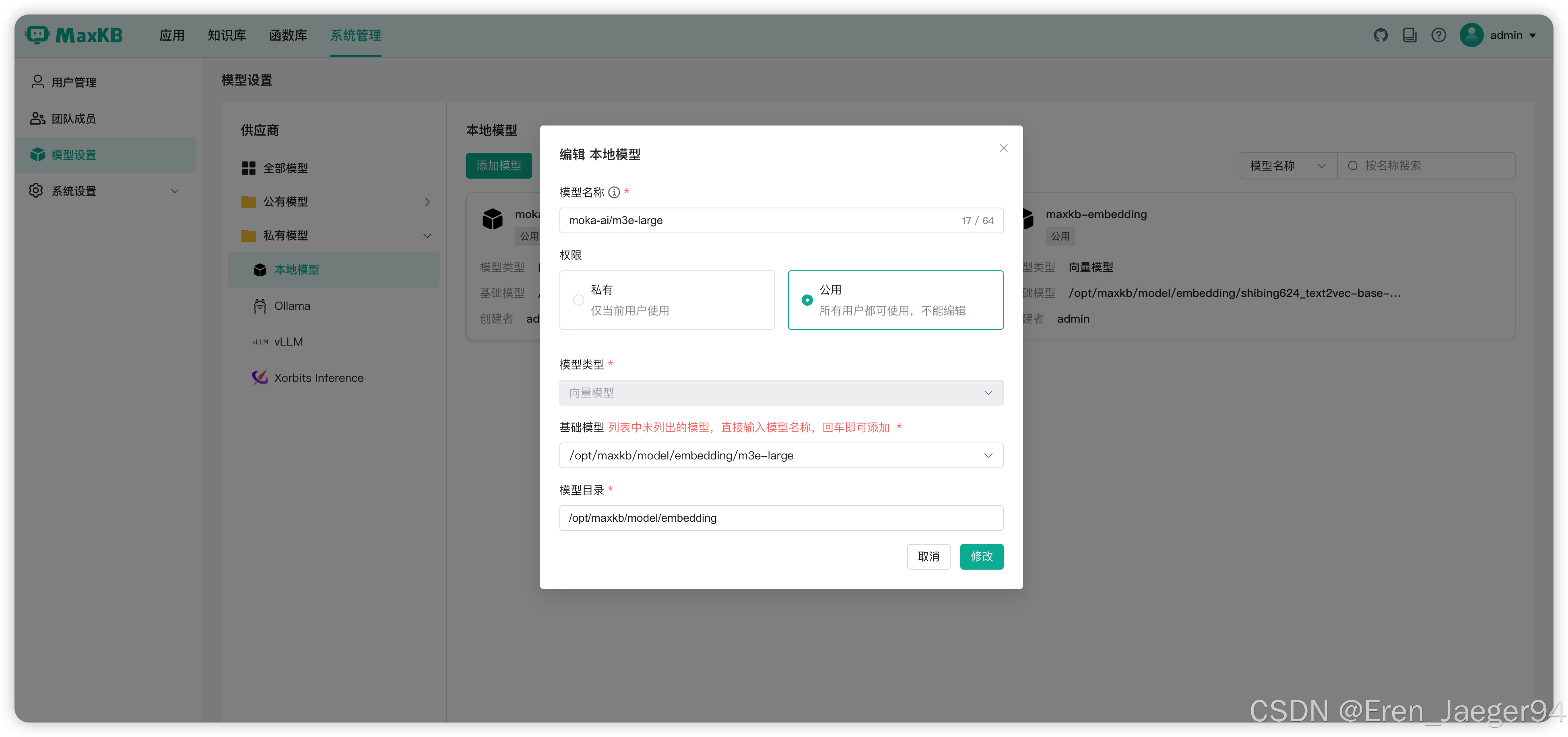
2.6 配置MaxKB离线向量模型
系统管理 > 模型设置 > 私有模型 > 添加模型 > 选择模型类型为向量模型

















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









