







1. 前言
deepseek-R1采用了两种方式微调,一种较为传统的有监督SFT微调方式;第二种为强化学习的方式微调(GPRO)。基于此,本文采用最新的基于强化学习的微调方式对VLM-R1进行微调。
2. 强化学习微调的关键
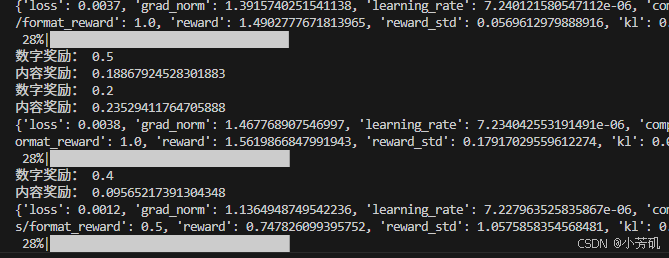
强化学习微调的关键在于奖励函数的设计,因此,本人设计了营养健康方面的奖励函数:
2.1 内容的奖励机制,值得注意的是我是模改vlm里面IOU候选框的奖励机制,为了更适配下游我的任务,我把原来的奖励机制改为数量奖励和内容名称奖励。
def content_reward(completions, solution, **kwargs):
contents = [completion[0]["content"] for completion in completions]
rewards = []
current_time = datetime.now().strftime("%d-%H-%M-%S-%f")
answer_tag_pattern = r'<answer>(.*?)</answer>'
# bbox_pattern = r'\[(\s*-?\d*\.?\d+\s*),\s*(\s*-?\d*\.?\d+\s*),\s*(\s*-?\d*\.?\d+\s*),\s*(\s*-?\d*\.?\d+\s*)\]'
bbox_pattern = r'\[(\d+),\s*(\d+),\s*(\d+),\s*(\d+)]'
for content, sol in zip(contents, solution):
reward = 0.0
# Try symbolic verification first
try:
content_answer_match = re.search(answer_tag_pattern, content, re.DOTALL)
if content_answer_match:
content_answer = content_answer_match.group(1).strip()
has_numbers = bool(re.search(r'\d', sol))
if has_numbers:
# For numeric answers, use exact matching
reward_num = numeric_reward(content_answer, sol)
print("数字奖励:", reward_num)
content_answer = remove_numbers(content_answer)
sol = remove_numbers(sol)
reward_content = ratio(content_answer, sol)
print("内容奖励:", reward_content)
reward = reward_content + reward_num
# bbox_match = re.search(bbox_pattern, content_answer)
# if bbox_match:
# bbox = [int(bbox_match.group(1)), int(bbox_match.group(2)), int(bbox_match.group(3)), int(bbox_match.group(4))]
# if iou(bbox, sol) > 0.5:
# reward = 1.0
except Exception:
pass # Continue to next verification method if this fails
rewards.append(reward)
if os.getenv("DEBUG_MODE") == "true":
log_path = os.getenv("LOG_PATH")
# local_rank = int(os.getenv("LOCAL_RANK", 0))
with open(log_path, "a", encoding='utf-8') as f:
f.write(f"------------- {current_time} Accuracy reward: {reward} -------------\n")
f.write(f"Content: {content}\n")
f.write(f"Solution: {sol}\n")
return rewards
2.2format奖励机制
def format_reward(completions, **kwargs):
"""Reward function that checks if the completion has a specific format."""
pattern = r"<think>.*?</think>\s*<answer>.*?</answer>"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.fullmatch(pattern, content, re.DOTALL) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]
3.数据集的爬取
我这里爬取了4200条营养学的数据,我这里展示下爬虫的完整过程:
import requests
from bs4 import BeautifulSoup
import time
import csv
# 设置请求头模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://www.boohee.com/'
}
def scrape_food_group(food_items, group_id):
for page_id in range(1, 11):
url = f'https://www.xxxxx.com/food/group/{group_id}?page={page_id}'
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
food_list = soup.find('ul', class_='food-list')
if food_list:
for item in food_list.find_all('li'):
name = item.find('h4').get_text(strip=True) if item.find('h4') else 'N/A'
heat = item.find('p').get_text(strip=True) if item.find('p') else 'N/A'
img = item.find('img')['src'] if item.find('img') else 'N/A'
food_items.append({
'name': name,
'heat': heat.split(":")[1],
'image': img,
})
return food_items
def save_to_csv(data, filename='boohee_food.csv'):
if not data:
return
keys = data[0].keys()
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=keys)
writer.writeheader()
writer.writerows(data)
if __name__ == '__main__':
all_foods = []
food_items = []
for group_id in range(1, 10):
print(f"Scraping group {group_id}...")
foods = scrape_food_group(food_items, group_id)
all_foods.extend(foods)
time.sleep(2)
save_to_csv(all_foods)
print(f"Done! Saved {len(all_foods)} food items to boohee_food.csv")
爬取好需要构建和训练集一样格式的格式,在这里我们默认的格式输入是:

转换代码如下:
'''数据格式:{
"id": 1,
"image": "Clevr_CoGenT_TrainA_R1/data/images/CLEVR_trainA_000001_16885.png",
"conversations": [
{"from": "human", "value": "<image>What number of purple metallic balls are there?"},
{"from": "gpt", "value": "0"}
]
}'''
import glob
import pandas as pd
from openpyxl import load_workbook
import os
import random
import json
import csv
questions = ["这道菜是怎么做的?", "图中的菜需要哪些食材?", "请问这道菜的配方是什么?", "这道菜的主要配料有哪些?", "图中的菜是怎么烹饪的?", "这道菜用了哪些原料?"]
file_path = "/www/VLM-R1/xiangha_recipes_list.csv"
results_list = []
with open(file_path, mode='r', encoding='utf-8') as file:
csv_reader = csv.reader(file)
for i, row in enumerate(csv_reader):
template = {
"id": 1,
"image": "",
"conversations": [
{"from": "human", "value": "<image>"},
{"from": "gpt", "value": ""}
]
}
if i == 0:
continue
else:
_, url1, answer, image_url, image_path = row
template["id"] = i
template["image"] = image_path
random_number = random.randint(0, len(questions)-1)
template["conversations"][0]["value"] += questions[random_number]
template["conversations"][1]["value"] = answer
results_list.append(template)
#########################################################################################
with open("/www/VLM-R1/datasets/own_datasets/own_data.json", "w", encoding="utf-8") as f:
json.dump(results_list, f, ensure_ascii=False, indent=4)
print("数据已经转化完毕!")
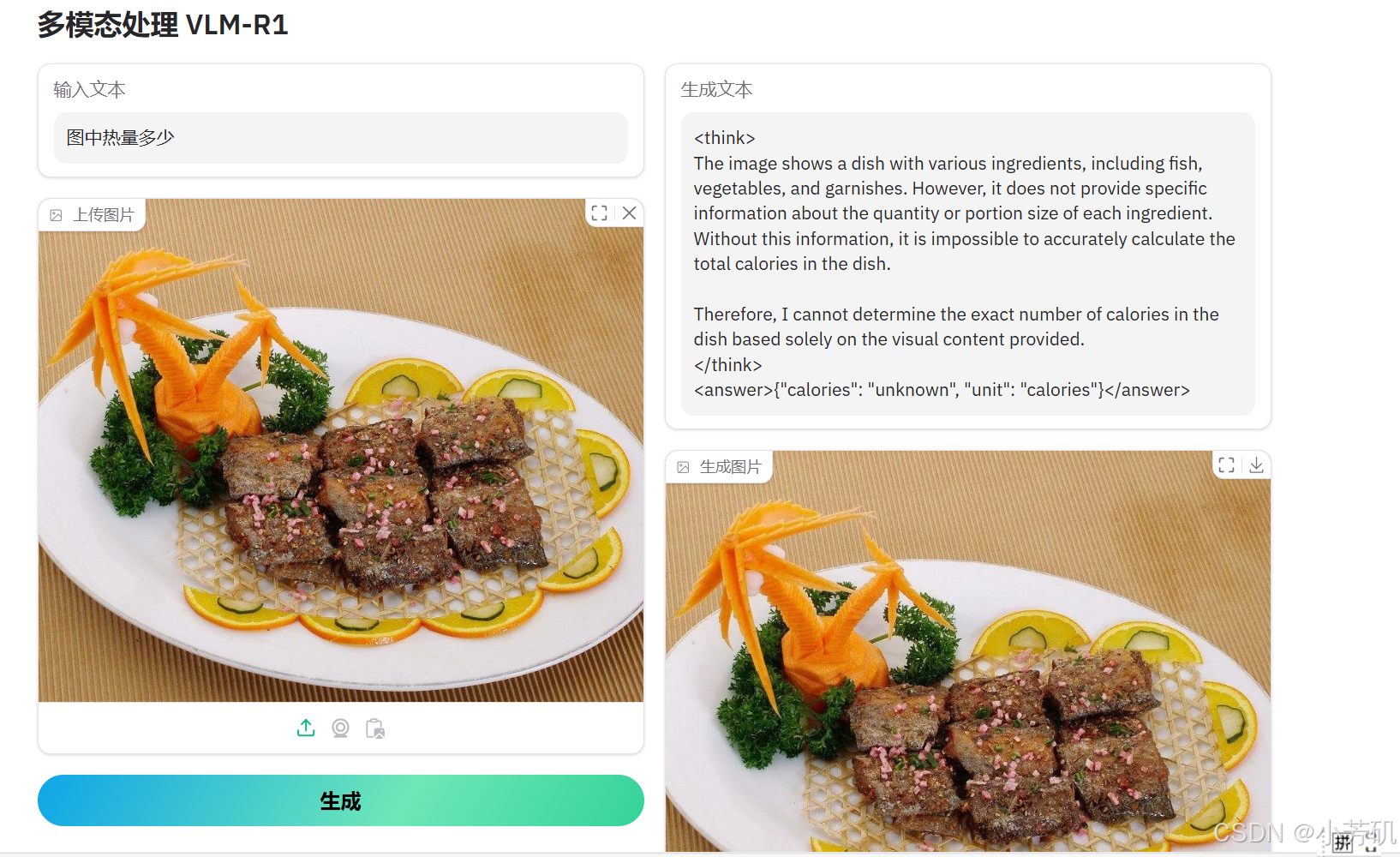
结果展示
没有微调之前
使用微调后的权重

(源码有偿提供)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









