









由于ALS CP分解算法不能保证收敛到最小值,我们可以用正则项来解决。
《Some convergence results on the Regularized Alternating Least-Squares method for tensor decomposition》分析了如下的正则项约束Regularized Alternating Least-Squares (RALS),它惩罚了现在的因子矩阵和上一个迭代的因子矩阵的误差,是近端最小化方法,the proximal point modification of the GS (PGS) method。通过加入惩罚项来将使得函数严格凸,避免了当ALS没有critical point却会产生critical point的情况
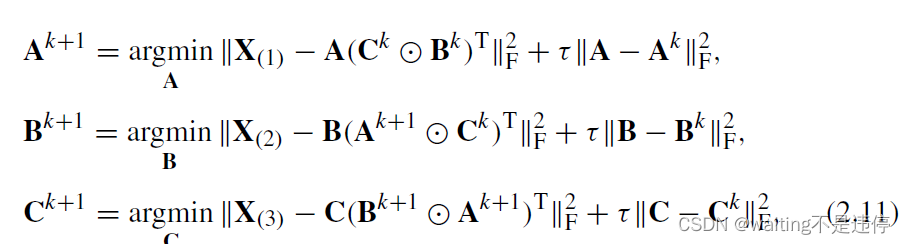
因此每一步的优化就变成如下问题:
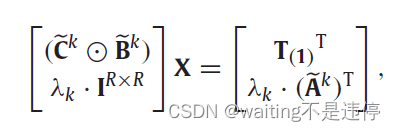
这个问题就变为吉洪诺夫Tikhonov正则化问题
第一个子问题的闭合解推导如下:
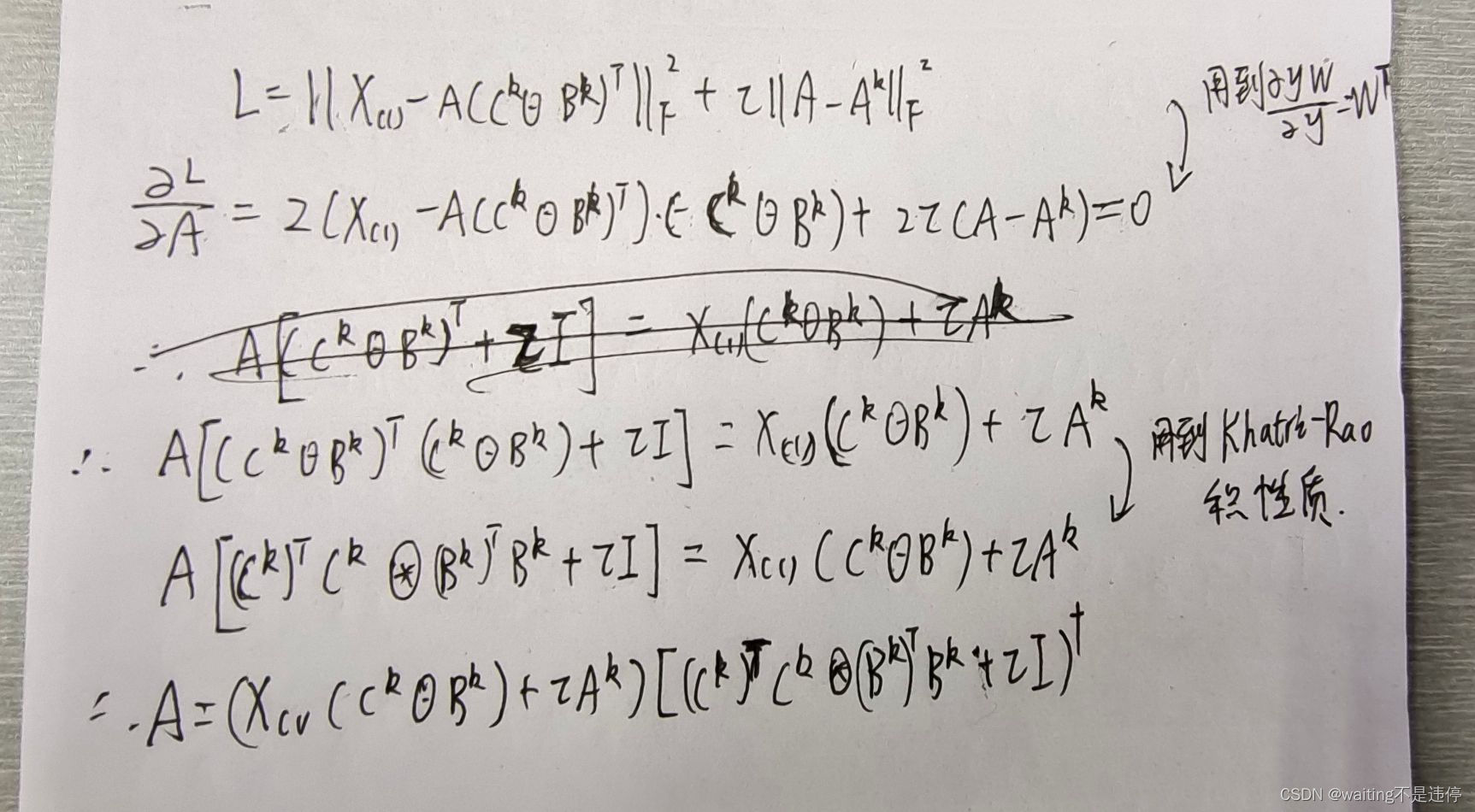
因此每一个子问题的解如下
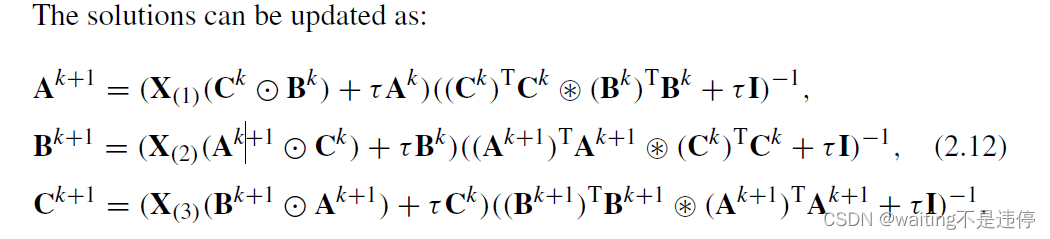
关于惩罚系数的取值,可以参考SWAMP REDUCING TECHNIQUE FOR TENSOR DECOMPOSITION,即一般和噪声水平成正比

在迭代过程中也可以对正则项进行一个衰减decaying操作

整个算法如下:

python写出来的代码如下:
import numpy as np
import tensorly as tl
import tqdm
from tensorly.decomposition._cp import initialize_cp
tl.set_backend('numpy')
a = np.array([[1,3,5,7,8],[8,4,6,2,10]])
b = np.array([[5,13,55,17,18],[58,14,46,12,1]])
c = np.array([[14,1,5,17,18],[58,14,46,12,1]])
X = np.einsum('i,j,k->ijk',a[0],b[0],c[0])
X += np.einsum('i,j,k->ijk',a[1],b[1],c[1])
X = X.astype(float)
def CP_RALS(X, r=1, max_iter=100, err=1e-10, tao = 0.5):
N = tl.ndim(X)
# random initialize
A = initialize_cp(X, r,init='svd',svd='numpy_svd').factors
# # random initialize
# A = []
# for n in range(N):
# A.append(tl.tensor(np.random.random((X.shape[n], r))))
for epoch in range(max_iter):
for n in range(N):
identity = np.eye(A[n].shape[1])
V = np.ones((r,r))
for i in range(N):
if i != n:
V = A[i].T@A[i] * V
A[n] = (tl.unfold(X,mode=n)@tl.tenalg.khatri_rao(A, skip_matrix=n) + tao*A[n])@np.linalg.pinv(V+tao*identity)
X_pred = tl.fold(A[0]@tl.tenalg.khatri_rao(A,skip_matrix = 0).T,mode=0,shape=X.shape)
error = tl.norm(X-X_pred)
print("epoch:",epoch,",error:",error)
if error<err:
break
return A
A = CP_RALS(X,r=2,max_iter=1000,tao = 0.8)
print("hi")














 2059
2059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









