







如有错误,恳请指出。
这篇博客是一篇归纳总结性的博客,对几篇MLP结构文章进行汇总。
1. Cycle-MLP
出发点:结合层级结构来适应可变的图像尺寸,减少计算复杂度
Cycle FC block大体结构上与MLP-Mixer类似,继承了Channel FC的优点,可以接受任意尺度的大小处理接受任意分辨率的输入,同时改进了Spatial FC进行空间全局上下文聚合消耗计算量大的缺点,提出了阶梯式风格进行采样。这样,可以在保持计算复杂度的同时一定程度上扩大感受野。
- CycleMLP的Block结构:
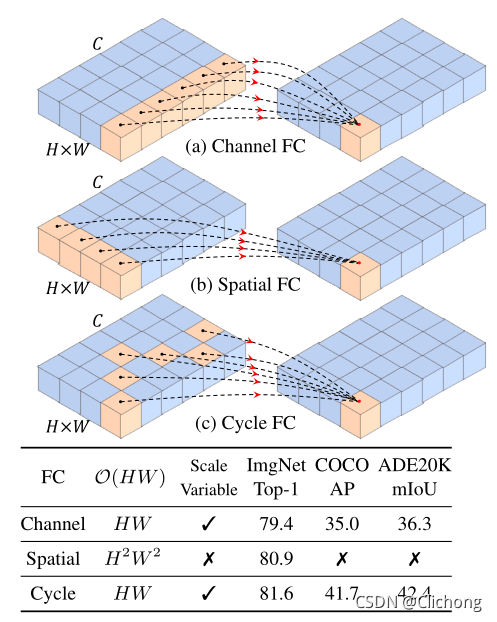
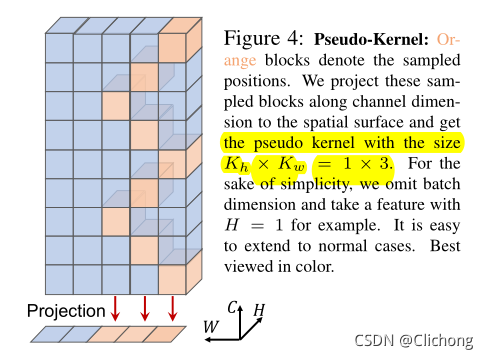
Cycle FC本质上还是一个移动特征图的操作,Cycle FC block由三个并行的Cycle FC算子组成,三条支路并行:H 方向,W 方向,以及不移动特征图做通道方向映射
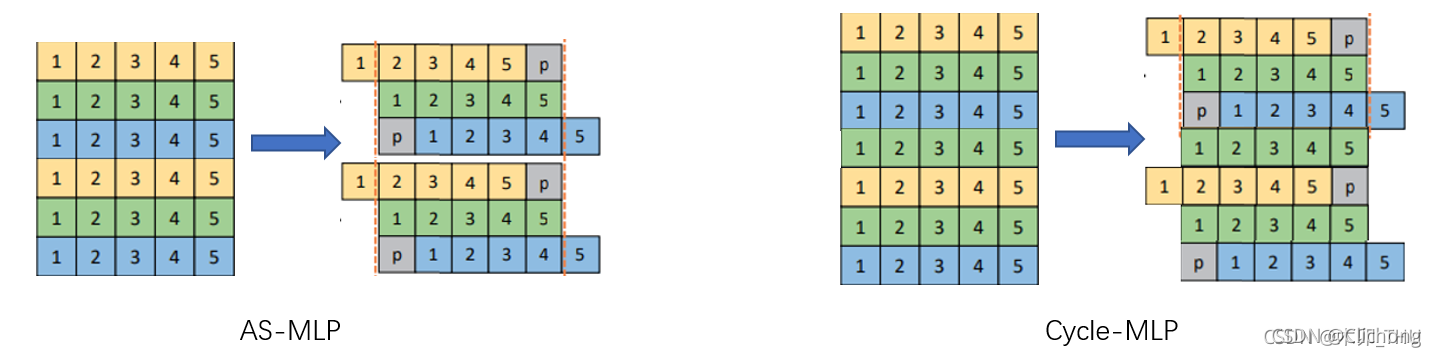
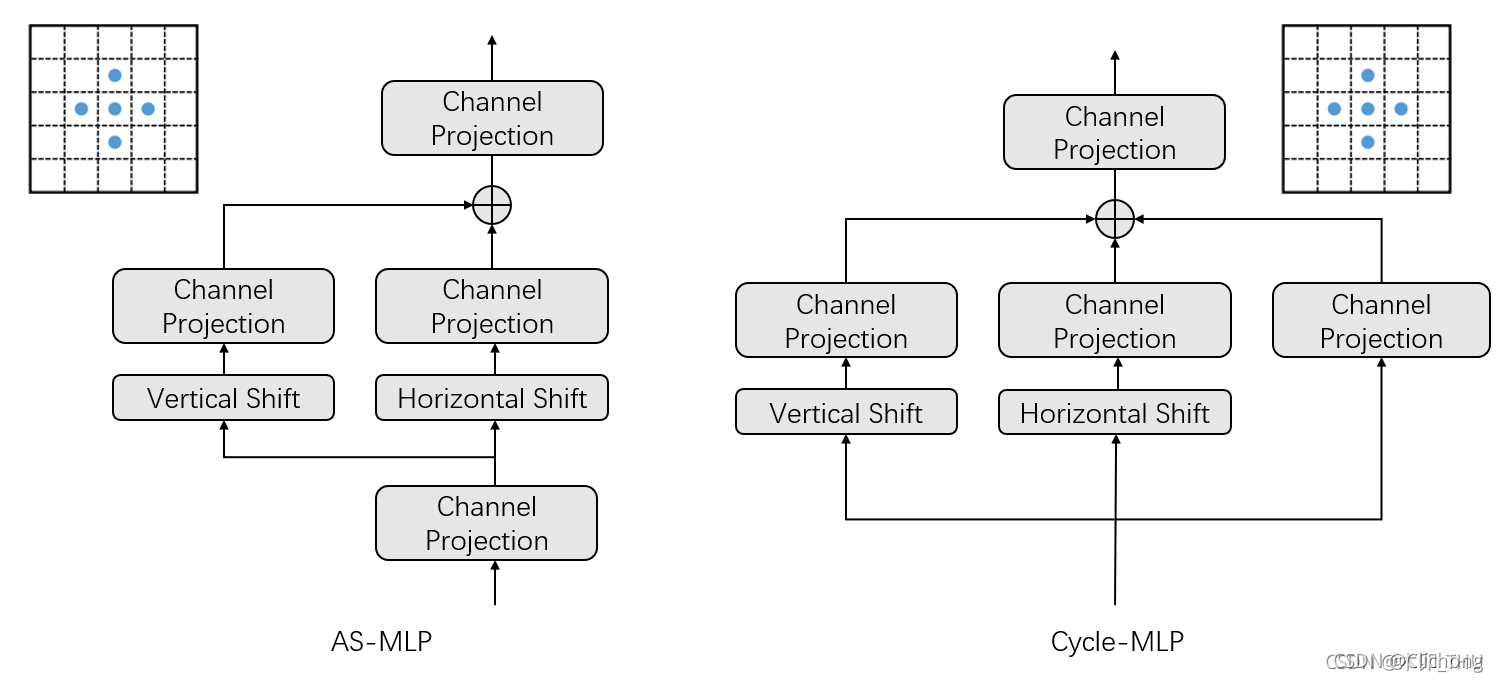
详细内容:
1.论文阅读笔记 | MLP系列——CycleMLP
2.CycleMLP网络详解
2. Hire-MLP
出发点:解决MLP-Mixer对输入图像尺寸敏感的问题,且平面化空域信息的效率较低
Hire-MLP提出了分层重排的思想来聚合局部和全局空间信息,同时对下游任务具有通用性。区域内重排(inner-region rearrangement)可以捕获空间区域内的局部信息,跨区域重排(the cross-region rearrangement)实现不同区域间的信息交流和获取全局语境,其将所有标记沿空间方向循环移位。
-
Hire-MLP Block结构:
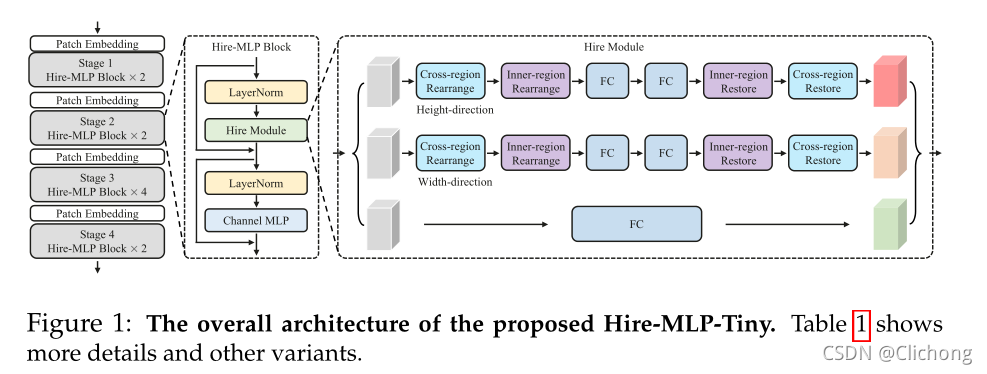
其中包含三条支路,分别是对于 H 方向的重排,W 方向的重排,以及通道方向的映射,最后三条支路的特征图直接加和即可获得最终的融合特征图。 -
Inner-Region与Cross-Region:
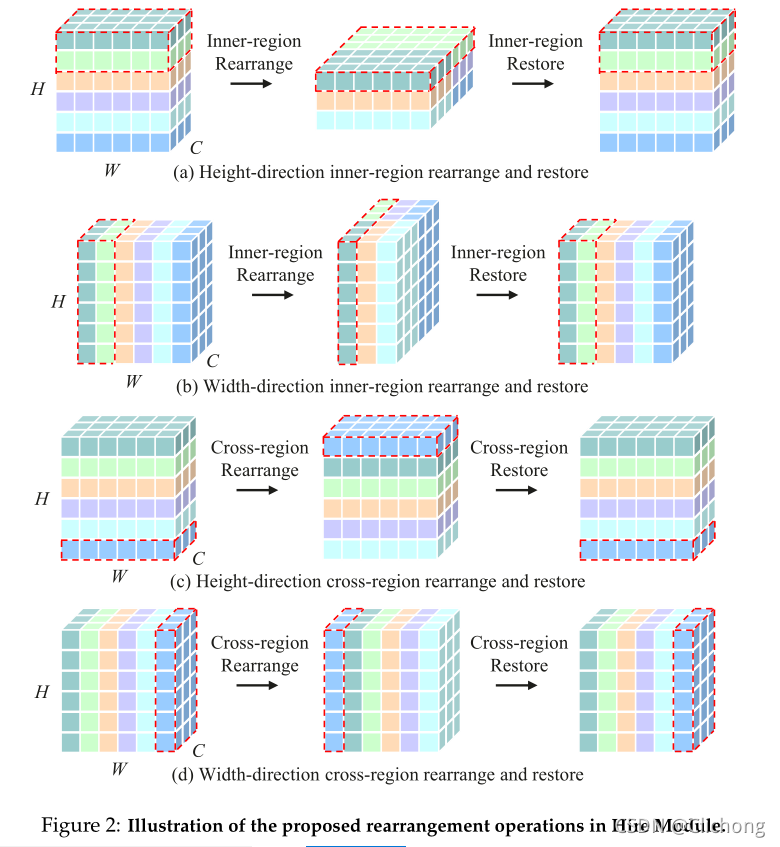
详细内容:Hire-MLP网络详解
3. Sparse-MLP
出发点:Self-Attention是否必须?MLP能否达到Sota的性能?
利用DW卷积+Sparse-MLP模块替换了Token-mixing MLP。DW卷积可以减少计算量并且实现局部的信息交流,而Sparse-MLP在W与H通道轴上具有长距离依赖。其中分3个分支,其中两条在宽高维度上进行全连接处理,还有一条不作处理,将3条支路concat再作1x1的卷积降维。
- sMLPNet网络架构
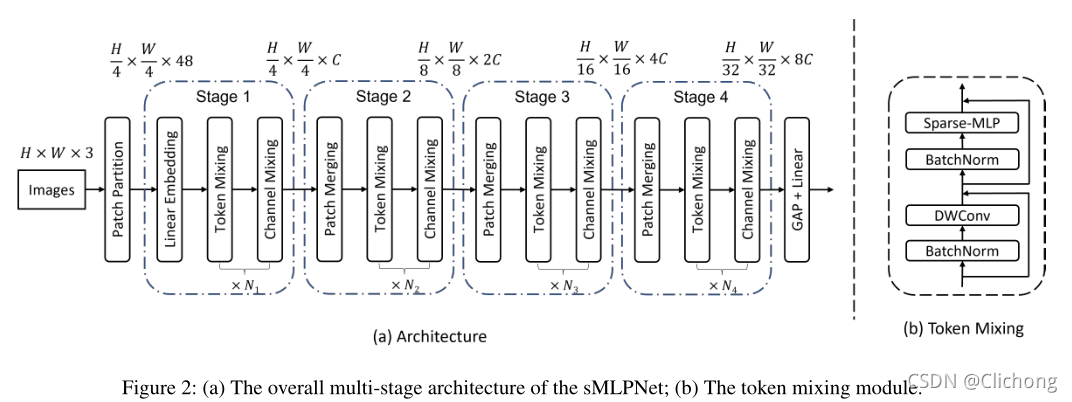
- Sparse-MLP Block结构:
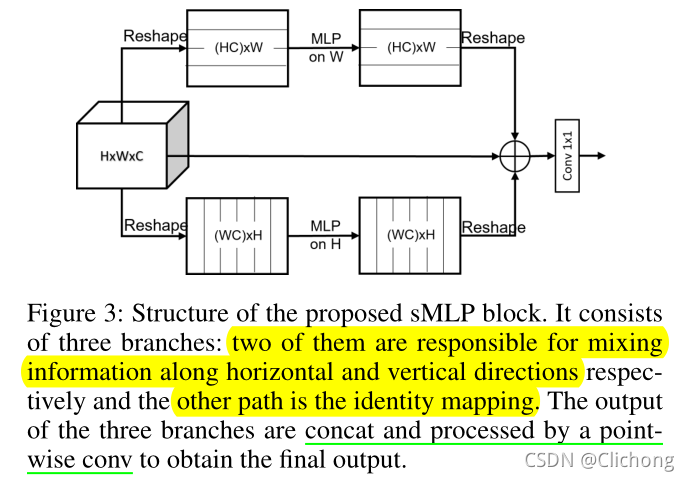
- 感受野示意图:
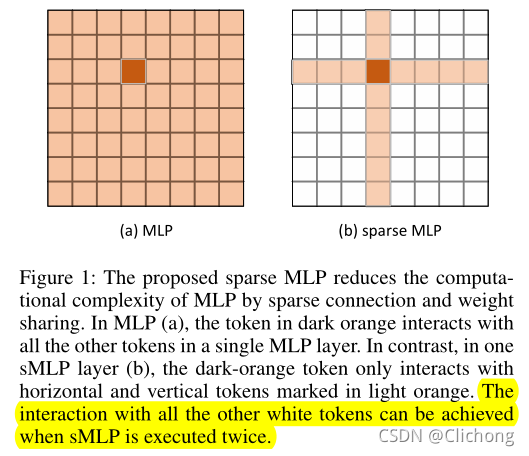
虽然在一层上看起来是十字形感受野,但是如果经过两个 Sparse-MLP 之后,其实能形成全局感受野,可以实现与所有其他白色令牌的交互。
详细内容:Sparse-MLP网络详解
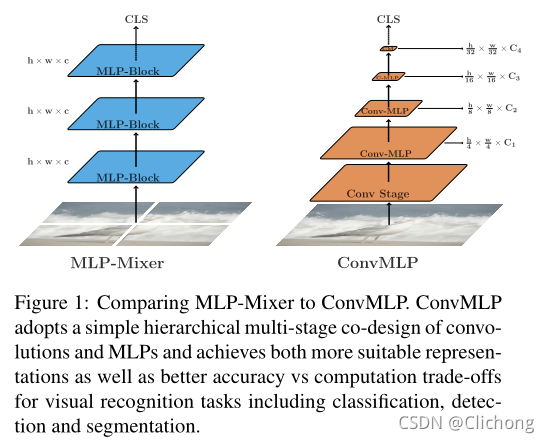
4. ConvMLP
出发点:固定维数的输入会限制下游任务且全连接层的计算量较大,用卷积来解决问题
ConvMLP是一格分层卷积的MLP骨干,用于视觉识别与卷积和MLP层的共同设计。其使用3 × 3DW卷积来替换Token-mixing MLP,以引入局部性特征。同时,使用了Convolutional Tokenizer替换Patch Embedding并提高了性能,然后在Conv Stage采用全卷积来增加空间内的信息交互。
- ConvMLP Block结构:

- 详细参数结构
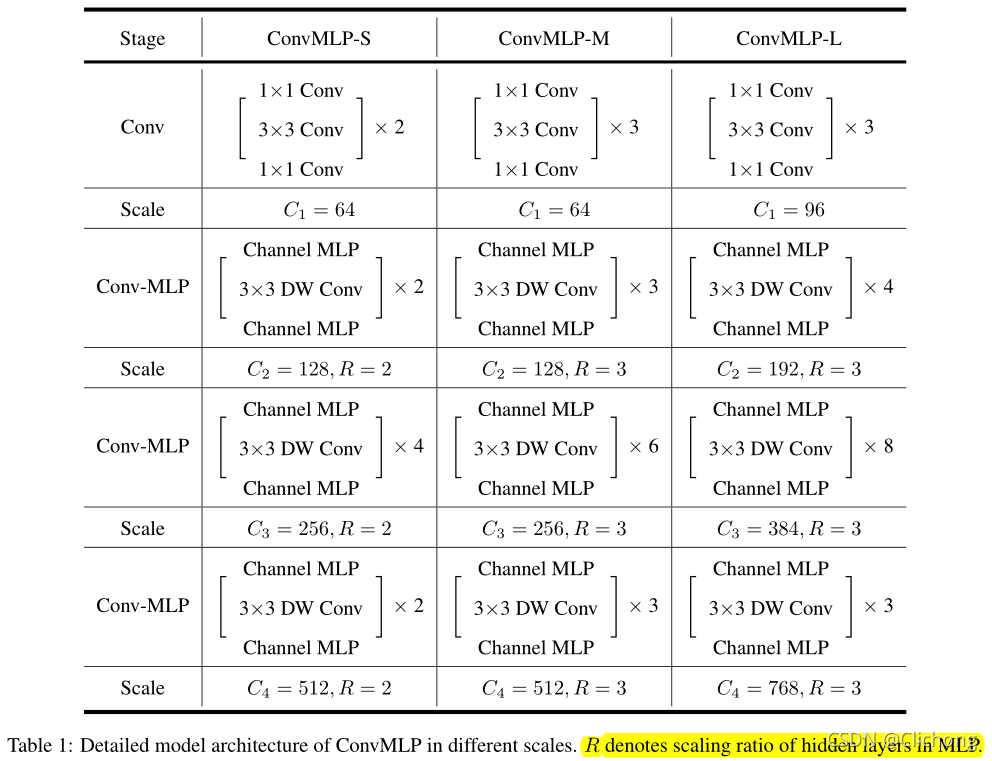
详细内容:ConvMLP 网络详解



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











