






文生图大模型已经火了很长一段时间了,而随着技术与模型算法的不断提升,文生视频模型也越来越多。今天就介绍一下字节跳动发布的MagicVideo-V2文生视频大模型。
文生图的大火对文本生成高保真视频的需求也不断增长,正是这种需求的增加,推动了该领域的重要研究。

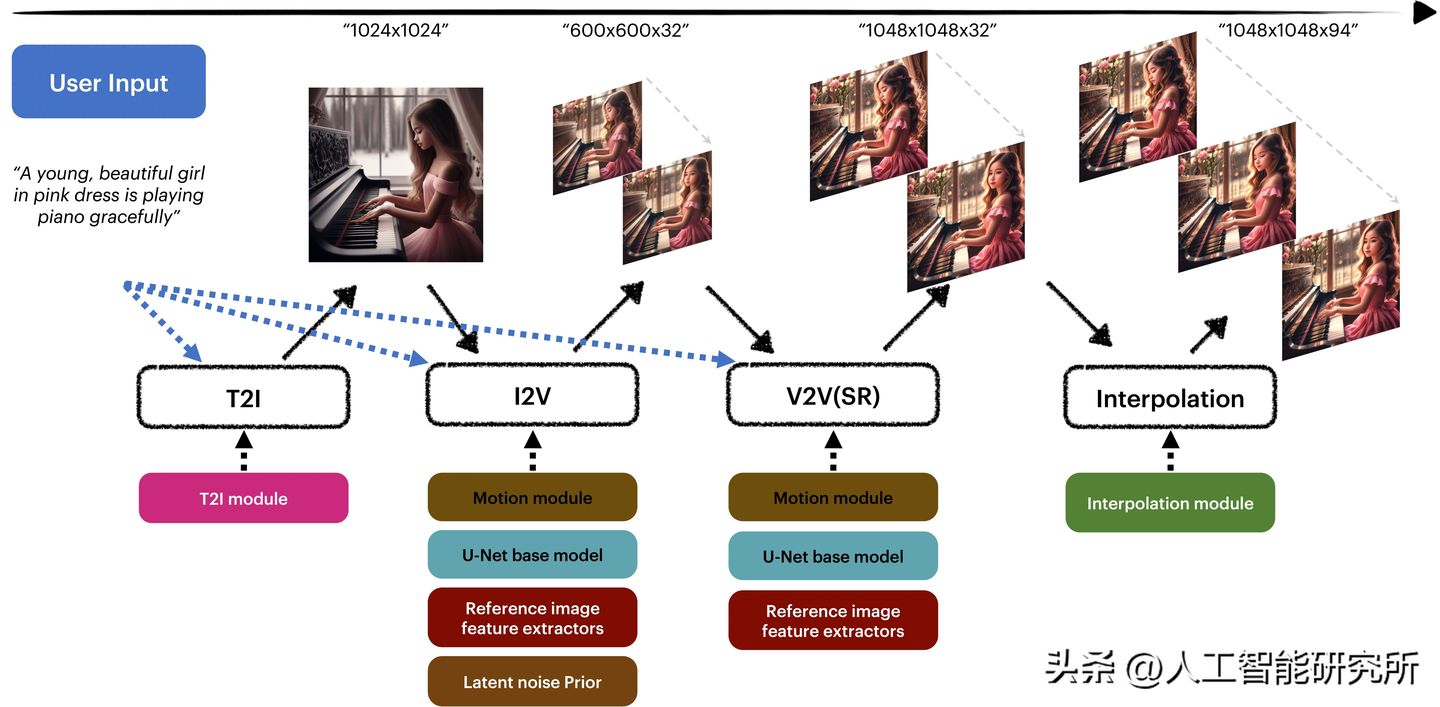
在这项工作中,字节跳动发布了MagicVideo-V2文生视频模型,此模型将文本到图像模型、视频运动生成器、参考图像嵌入模块和帧插值模块集成到一个端到端的视频生成管道中。

得益于这些架构设计,MagicVideo-V2可以生成美观、高分辨率的视频,具有高保真度和流畅度。通过大规模的用户评估,此模型的性能也超越了其他文本到视频模型的性能(如Runway、Pika 1.0、Morph、Moon Valley和Stable Video Diffusion。

比如输入如下: 一个穿着粉色裙子的小女孩在弹钢琴 "A young, beautiful girl in a pink dress is playing piano gracefully." 模型会通过文生图大模型首先生成一张符合当前输入文本的图片,然后使用图片与文本描述利用图生成视频模型生成简单的视频,并使用视频到视频模型,对当前的视频进行超分辨率技术合成,让视频更加清晰,最后使用插帧模型,把视频进行插帧,让视频中的动作更加细腻。

输入如下: 钢铁侠飞过着火的城市 "Ironman flying over a burning city, very detailed surroundings, cities are blazing, shiny iron man suit, realistic, 4k ultra high defi."
输入如下: 一艘行驶在狂风海面上的大船 "Flying through an intense battle between pirate ships in a stormy ocean."
整体来看,MagicVideo-V2模型生成的视频超高清,且动作很丝滑,并没有卡帧的情况。且模型生成的视频动画都很优美。

总体来说,MagicVideo-V2模型的T2I模块创建一个1024×1024的图像,用于封装所描述的场景。随后,I2V模块对该静止图像进行动画处理,生成600×600×32帧的序列图片。V2V模块将这些帧增强到1048×048的分辨率,同时细化视频内容。最后,插值模块将序列扩展到94帧,得到1048×1048分辨率的视频,该视频具有高的分辨率与视频帧数。确保了视频的高质量与动作的运动丝滑性。

MagicVideo-V2模型由以下关键模块组成: •生成图像的文本到图像模型(T2I) 从给定的文本描述中,生成对应的图片。T2I模块以用户的文本提示为输入,生成1024×1024的图像作为视频生成的参考图像。参考图像有助于描述视频内容和视频风格。所提出的MagicVideo-V2与不同的T2I模型兼容。具体来说,在MagicVideo-V2中使用了字节跳动开发的基于扩散的T2I模型,该模型可以输出高分辨率的图像。

•使用文本提示和生成的图像到视频模型(I2V) 通过第一步得到的图片以及文本描述来生成对应的动态视频。I2V模块建立在SD1.5模型上,该模型利用人类反馈来提高模型的视觉质量以及内容的一致性。此模型部署了ControlNet模块,直接从参考图像中提取RGB信息,并将其应用于所有视频帧中。这些技术将视频帧与参考图像很好地对齐,以便模型以生成清晰丝滑的动作。 MagicVideo-V2模型采用图像-视频联合训练策略来训练I2V模块,其中图像被视为单帧视频。联合训练的动机是利用高质量内部图像数据集,提高生成视频帧的质量。图像数据集部分也可以很好地补偿缺乏多样性和数量的视频数据集。

•视频到视频模型(V2V) 对关键帧进行细化并执行超分辨率处理,以产生高分辨率视频。V2V模块具有与I2V模块类似的设计。它与I2V模块共享相同的模型主干和空间层。它的运动模块是使用高分辨率视频子集单独微调的,用于视频超分辨率。 这里还使用了图像外观编码器和ControlNet模块。事实证明,这是至关重要的,因为模型需要更高的分辨率来生成视频帧。

•视频帧插模型(VFI) 用于插值帧之间的关键帧,以平滑视频运动,并最终生成高分辨率、平滑、高度美观的视频。VFI模块使用内部训练的基于GAN的VFI模型。它采用了增强型可变形可分离卷积(EDSC)头,与基于VQ-GAN的架构配对使用,类似于自动编码器模型。为了进一步增强其稳定性和平滑性,MagicVideo-V2模型由使用了预训练的轻量级插值模型。 正是通过以上4个模型,使得MagicVideo-V2模型可以从输入文本中提出关键信息,并输出动作丝滑的漂亮视频。

在人类评估模型上,MagicVideo-V2模型达到了一定的效果,且与其他模型相比,MagicVideo-V2模型比其他模型相比,其效果也是超越了各个大模型。


https://magicvideov2.github.io/ MagicVideo-V2:Multi-Stage High-Aesthetic Video Generation
https://arxiv.org/abs/2401.04468
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:启示AI科技
微信中复制如下链接,打开,免费使用chatgpt
https://wx2.expostar.cn/qz/pages/manor/index?id=1137&share_from_id=79482&sid=24
动画详解transformer 动画教程

















 2240
2240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











