






前期我们介绍过很多语音合成的模型,比如ChatTTS,微软语音合成大模型等,随着大模型的不断进步,其合成的声音基本跟真人没有多大的区别。本期介绍的是字节跳动自家发布的语音合成模型Seed-TTS。
Seed-TTS 推理包含四个功能模块:
- (1) 语音标记器从参考语音中学习标记信息。
- (2)自回归语言模型根据条件文本和语音生成语音标记。
- (3) 扩散变换器模型以从粗到细的方式生成语音标记的连续语音表示。
- (4) 声学声码器从扩散输出中生成更高质量的语音。
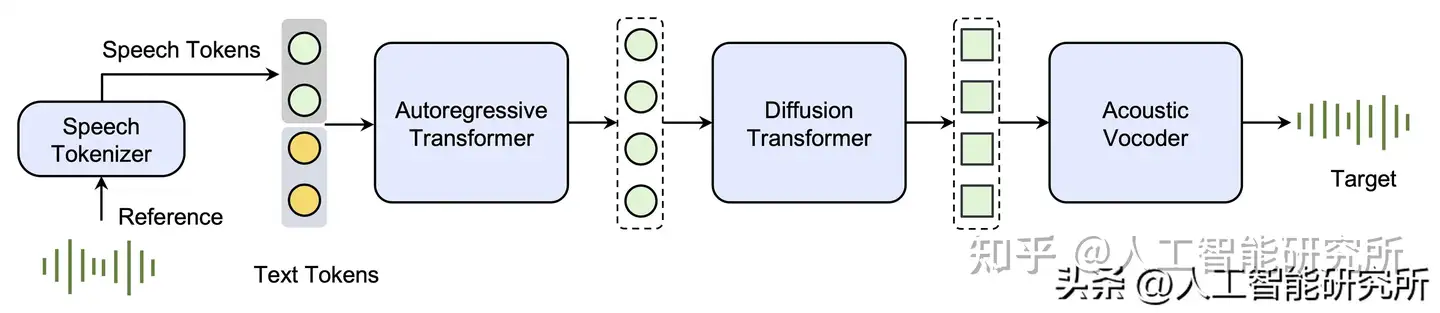
系统模型框架
Seed-TTS是一个大规模自回归文本转语音 (TTS) 模型,能够生成与人类语音几乎没有区别的语音。 Seed-TTS 作为语音生成的基础模型,在语音上下文学习方面表现十分出色,在说话者相似度和自然度方面的表现在客观和主观评估方面都与真实人类语音相匹配。 Seed-TTS 对各种语音属性(例如情感)提供卓越的可控性,并且能够为说话者生成高度表现力和多样化的语音。Seed-TTS 可以根据说话者的声音,模仿成另外一个语言的语音,且情感,音色等跟原始声音没有太大区别。

中英文转换
此外,Seed-TTS 使用了一种用于语音分解的自蒸馏方法,以及一种强化学习方法来增强模型的鲁棒性、说话人的相似性和可控性。Seed-TTS 模型的非自回归 (NAR) 变体,名为 Seed-TTSDiT,它采用完全基于扩散模型的架构。与之前基于 NAR 的 TTS 系统不同,Seed-TTSDiT 不依赖于预先估计的音素持续时间,并通过端到端处理执行语音生成。该变体在客观和主观评估中都达到了与基于语言模型的变体相当的性能,并展示了其在语音编辑中的有效性。且Seed-TTS 支持不同的情感输入,比如:高兴,生气,恐惧等情感。

不同情感的声音
且模型支持输入原始音频文件,并根据要求,输出不同情感的语音。
情感更换
不仅如此,模型支持修改语音文本的内容,并合成另外修改完成的语音。

修改语音内容
Seed-TTS还支持语音语速的调节,不仅如此,还支持多人说话的方式,这样一个长篇语音小说就可以完成了。当然模型也支持输入视频,把视频中的音频转换成另外一种语音。
https://bytedancespeech.github.io/seedtts_tech_report/
更多 transformer 教程,参考头条:人工智能更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:启示AI科技
动画详解transformer 在线教程



















 8393
8393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











