







引言
《Semi-supervised Sequence Learning》
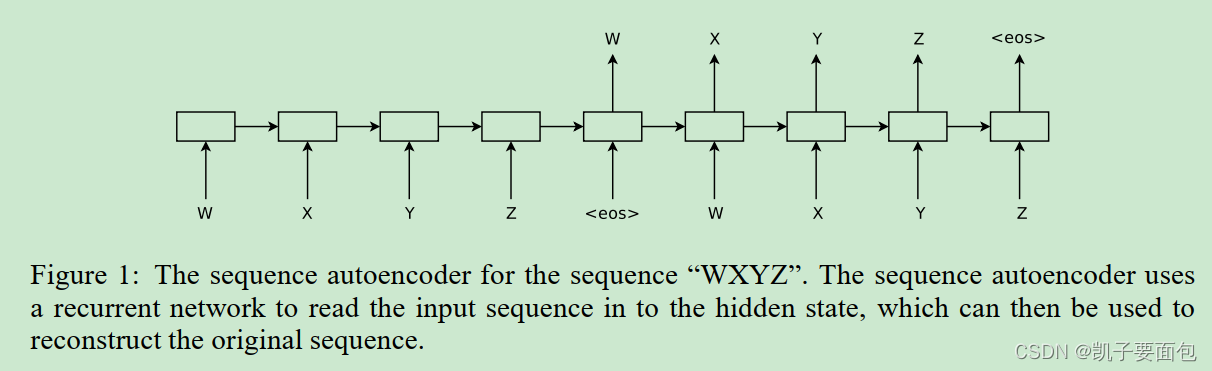
《Semi-supervised Sequence Learning》论文中提出了两种预训练方法,来提升LSTM模型的泛化能力。一种预训练方法,作者称为“sequence autoencoder”,本质就是一种“seq2seq”模型结构,encoder采用RNN,将输入转换成一个向量,decoder使用LSTM,并且将encoder得到的向量,作为decoder输入的初始向量, decoder的任务是做语言模型任务, 目标是恢复原始输入。注意,encoder的输入与decoder的输入一样。另外一种预训练方法称为“recurrent language model”,本质就是“sequence autoencoder”不要encoder部分。
《Deep contextualized word representations》
论文中提出了EMLO(Embedding From Language Models)预训练方法——试图解决word embedding 是“context independent”的问题,采用了前向、后向两个多层级的LSTM模型做语言模型任务,前向、后向LSTM共享Embedding层与Softmax层参数,其它参数各自独立。然后采用“拼接隐向量”的形式,使得编码向量时,考虑前向与后向的信息。虽然方式很粗暴,但却提供了综合前、后上下文的一种思路。
Bert、GPT与ELMo的异同
三者都是2018年发表的,在这里对三者的异同进行简单的记录。

- 在水平方向上,ELMo中每层的‘Lstm’指的是LSTM层中的一个单元,同理Bert与GPT中的’Trm’指的是同一个《Attention is all your need》——Transformer单元。其中 Bert只使用了Encoder部分;GPT只使用了Decoder部分。
- ELMO 与 GPT 本质上是做 “unidirectional Language model”, 而BERT 是做“bidirectional language model”。
- fine-tuning approach 是指在目标任务中,模型的所有参数都会调整,包括Embedding层。而feature-based approach 应该是从输入序列中抽取特征,然后基于下游任务,对这些特征进行不同的线性组合,得到最终结果,即预训练涉及的参数在下游任务时,冻结不变,仅调整下游任务的相关参数—— 对feature-based approach 使用的不是很多,仅就文字资料的理解做个记录。
BERT
pretraining & fine-tuning
BERT 是一种 pretraining & fine-tuning 方法,在 pretraining 阶段,做MLM(Mask Language Model)与 NSP(Next Sentence Prediction)任务——也可以做其它任务,比如类似GPT2的Cuasul Language Model。在 fine-tuning 阶段,以预训练阶段的参数进行初始化,不同的下游任务,会有各自的模型层, 调整参数时,共享层与任务特有层的所有参数一起调整。
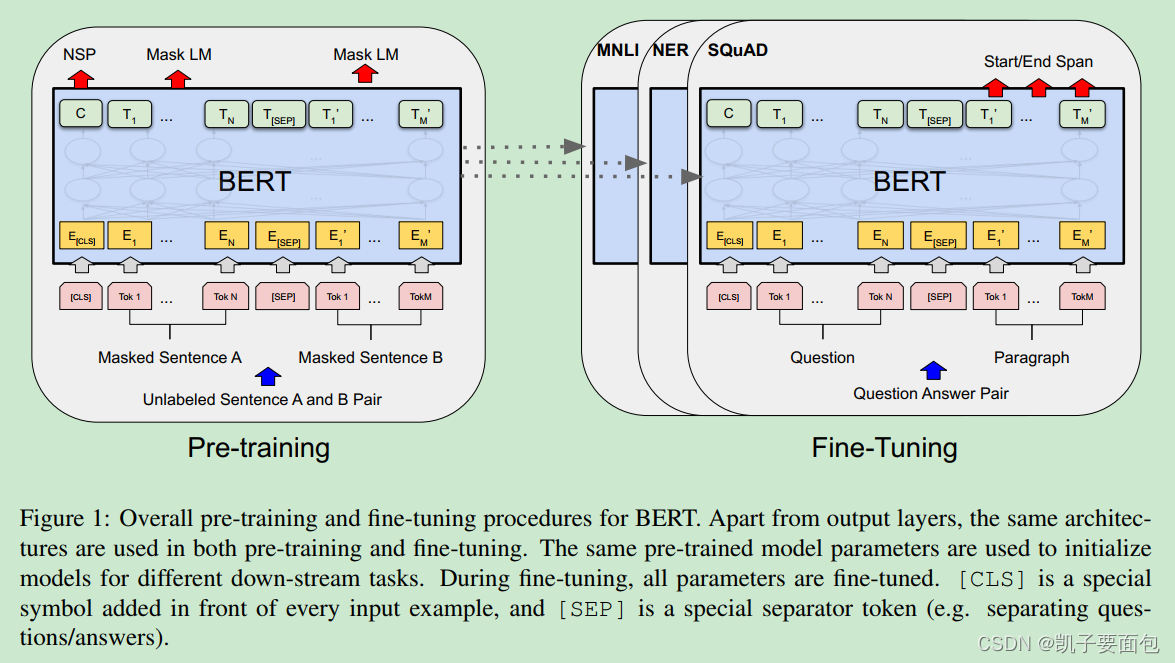
BERT Input

- 序列中每个词的输入包含三部分信息,Token的嵌入、位置编码、所属句子位置编码,这三种嵌入之和为每个词的输入表示;三种嵌入向量都是随机初始化,然后模型自动学习得到的
- 特殊标识‘CLS’标识classification,经过多层编码后,特殊标识符’CLS’会包含sentence-level的编码信息,该信息可用于分类任务
- 特殊标识‘SEP’标识两个句子之间的分割,会作为一个特殊标识符进行编码
1.3 两个预训练任务
预训练的损失函数是两个任务的损失函数之和。
任务1:使用Masked Language Model做“完型填空”。
- 随机遮掩掉原句子中15%的token。
- 80%被遮掩的部分使用特殊标识 ‘[MASK]'代替、10%被遮掩的部分随机使用另一个词代替、剩下10%被遮掩的部分使用原单词。
- 虽然Masked Language Model在编码时,实现了真正意义上的双向,但也有一个明显的缺点,就是引起了pre-training与Fine-tuning的不匹配,因为在下游的Fine-tuning任务中,输入是没有 ‘[MASK]'标识符的,通过随机替换1.5%比例(15%乘以10%)的被遮掩词,引入噪声,减轻这种Mismatch的不良影响。另外MLM还有一个缺点,就是在预测时,假设‘[MASK]'部分是相互独立地。
- 在预测时,仅预测‘[MASK]'部分, 而非全部序列。
任务2:给定句对A与B,判断句子B是否是句子A的下一句。
- 50%的概率,标签为ISNEXT,50%的概率标签为NOTNEXT。
- 类似Ski-Gram中的负采样思想。
- 为了弥补语言模型不能捕获句间关系,新增NSP任务,目的是为了服务句对类型的下游任务,如语义相似性。
1.4 Fine-tuning阶段:下游任务

- a)、b)是分类任务,比如a)任务处理句对是否具有相近的意思,b)是单句分类任务,比如影评数据,解决下游的分类任务,只需要提取顶层的特殊标识符’[CLS]'对应的隐向量,将该隐向量接一个全连接层,将隐向量映射到K维,K为类别数,再接Softmax,即可进行分类。
- c)任务:给出一个问题Question,并且给出一个段落Paragraph,然后从段落中标出答案的具体位置。需要学习一个开始向量S,维度和输出隐向量维度相同,然后和所有的隐向量做点积,取值最大的词作为开始位置;另外再学一个结束向量E,做同样的运算,得到结束位置。附加一个条件,结束位置一定要大于开始位置。
- d)任务:加一层分类网络,对每个输出隐向量都做一次判断。
- 这些任务,都只需要新增少量的参数,然后在特定数据集上进行训练即可。从实验结果来看,即便是很小的数据集,也能取得不错的效果。
在BERT论文中指出,预训练模型有两种使用策略,Fine-Tuning & Feature-Based。二者的主要区别在于:在Fine-Tuning策略下,预训练模型的所有参数会根据下游任务进行微调,即预训练模型中的所有参数是trainable,并且根据下游特定任务新增的网络层级中的(相对pre-train过程)的少量参数也是trainable;而在Feature-Based策略中,预训练模型中的所有参数是被冻结的,即non-trainable。
Part2-BERT实战
BERT主要使用了transformer中的encoder,然后接自定义头,自定义头根据下游任务确定。自定义头的输入为encoder最后一层输出的隐向量,下面列出带注解的transformer的pytorch实现:
import numpy as np
import torch
from torch import nn
# hyper parameter
d_model = 512
num_heads = 8
num_layers = 6
depth = d_model // num_heads
d_ff = 2048
def get_sinusoid_encoding_table(num_positions, embedding_dim):
"""
create position embedding table
:param num_positions: the number of positions
:param embedding_dim: the dimension for each position
:return: tensor.shape == (num_position, embedding_dim)
"""
def cal_angle(position, d_idx):
""" calculate angle value of each position in single dimension pos. """
return position / np.power(10000, 2 * (d_idx // 2) / embedding_dim)
def get_pos_angle_vec(position):
""" calculate all angle value of each position in every dimension. """
return [cal_angle(position, d_idx) for d_idx in range(embedding_dim)]
sinusoid_table = np.array([get_pos_angle_vec(position) for position in range(num_positions)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2])
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
return torch.FloatTensor(sinusoid_table)
def get_attn_pad_mask(seq_q, seq_k):
"""
mask position which value is padded.
in the encoder, seq_q and seq_k is same, so the len_q and len_k is equal;
in the decoder, when the attention is done on self, the seq_q and seq_k is also same, however, when calculate
attention between encoder_layer_outputs and first_sub_later encoder_layer's output, the seq_q is decoder outputs and
seq_k. seq_v is encoder outputs.
"""
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# PAD index is 0
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
return pad_attn_mask.expand(batch_size, len_q, len_k)
def get_attn_subsequence_mask(seq):
""" when calculate decoder self attention, the current position can only look before. """
attn_shape = (seq.size(0), seq.size(1), seq.size(1))
subsequence_mask = np.triu(np.ones(attn_shape), k=1)
return torch.from_numpy(subsequence_mask).byte()
class ScaledDotProductAttention(nn.Module):
"""
the core of MultiHeadAttention. firstly calculating scores of K and Q, then scaled scores; secondly masking
some score based on attention mask; finally softmax score, multiply score and V to create context vectors.
"""
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
@staticmethod
def forward(Q, K, V, attn_mask):
"""
:param Q: (batch_size, num_heads, seq_q, depth_q)
:param K: (batch_size, num_heads, seq_k, depth_k == depth_q)
:param V: (batch_size, num_heads, seq_v==seq_k, depth_v)
:param attn_mask: (batch_size, num_heads, seq_q, seq_k)
:return: context vector: (batch_size, num_heads, seq_q, depth_v)
"""
# (batch_size, num_heads, seq_q, seq_k)
score = torch.matmul(Q, K.transpose(-1, -2))
score = score / np.sqrt(K.size(-1))
if attn_mask is not None:
score.masked_fill_(attn_mask, -1e9)
attn = torch.softmax(score, dim=-1)
# (batch_size, num_heads, seq_q, depth_v)
context = torch.matmul(score, V)
return context, attn
class MultiHeadAttention(nn.Module):
""""
MultiHeadAttention is running parallel. In the transformer, the MultiHeadAttention will be called three times.
including calculate encoder's self attention, decoder's self attention, attention between encoder and decoder.
"""
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.WQ = nn.Linear(d_model, d_model, bias=False) # project inputs into Query space
self.WK = nn.Linear(d_model, d_model, bias=False) # project inputs into Key space
self.WV = nn.Linear(d_model, d_model, bias=False) # project inputs into Value space
self.fc = nn.Linear(d_model, d_model, bias=False) # project concatenated heads into new space
def forward(self, input_q, input_k, input_v, attn_mask):
batch_size = input_q.size(0)
# project inputs -> (B, S, D_new) -> (B, S, H, Depth) -> (B, H, S, Depth)
Q = self.WQ(input_q).view(batch_size, -1, num_heads, depth).transpose(1, 2)
K = self.WK(input_k).view(batch_size, -1, num_heads, depth).transpose(1, 2)
V = self.WK(input_v).view(batch_size, -1, num_heads, depth).transpose(1, 2)
# (B, seq_len, seq_len) -> (B, 1, seq_len, seq_len) -> (B, H, seq_len, seq_len)
attn_mask = attn_mask.unsqueeze(1).repeat(1, num_heads, 1, 1)
# context.shape: (batch_size, num_heads, seq_q, depth_v)
# attn.shape: (batch_size, num_heads, seq_q, seq_k)
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
# (batch_size, num_heads, seq_q, depth_v) -> (B, seq_q, H, depth) -> (B, seq_q, d_model)
context = context.transpose(1, 2).reshape(batch_size, -1, d_model)
# (B, seq_q, d_model) -> (B, seq_len, d_model)
output = self.fc(context)
return nn.LayerNorm(d_model)(output + input_q), attn
class PosWiseFeedForward(nn.Module):
""" position-wise feed forward network. """
def __init__(self):
super(PosWiseFeedForward, self).__init__()
self.proj = nn.Sequential(
nn.Linear(d_model, d_ff, bias=True),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=True)
)
def forward(self, x):
return nn.LayerNorm(d_model)(x + self.proj(x))
class EncoderLayer(nn.Module):
""" consist of MultiHeadAttention and PosWiseFeedFroward. """
def __init__(self):
super(EncoderLayer, self).__init__()
self.attn_layer = MultiHeadAttention()
self.ff_layer = PosWiseFeedForward()
def forward(self, x, attn_mask):
"""
encoder has only self attention, so inputs for multi-head attention is all same.
:param x: (batch_size, src_len, d_model)
:param attn_mask: (batch_size, src_len, src_len)
"""
# outputs.shape: (batch_size, src_len ,d_model)
# attn.shape: (batch_size, num_heads, src_len, src_len)
outputs, attn = self.attn_layer(x, x, x, attn_mask)
outputs = self.ff_layer(outputs)
return outputs, attn
class Encoder(nn.Module):
""" consist of stacked encoder layer and word_embedding layer and position embedding layer. """
def __init__(self, source_vocab_size, max_length=256):
super(Encoder, self).__init__()
self.position_embedding = nn.Embedding.from_pretrained(
get_sinusoid_encoding_table(max_length, d_model), freeze=True)
self.word_embedding = nn.Embedding(source_vocab_size, d_model)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(num_layers)])
def forward(self, x):
"""
x -> embedding(position + word) -> each_encoder_layer
:param x: (batch_size, src_len)
:return: (batch_size, src_len, d_model)
"""
word_embedding = self.word_embedding(x) # (batch_size, src_len, d_model)
pos = torch.tensor([[pos_idx for pos_idx in range(x.size(1))] for batch_idx in range(x.size(0))],
dtype=torch.int).unsqueeze(0)
position_embedding = self.position_embedding(pos) # (batch_size, src_len, d_model)
outputs = word_embedding + position_embedding
# attn_maks.shape: (batch_size, src_len, src_len)
attn_mask = get_attn_pad_mask(x, x)
encoder_attentions = list()
for layer in self.layers:
outputs, attn = layer(outputs, attn_mask)
encoder_attentions.append(attn)
return outputs, encoder_attentions
class DecoderLayer(nn.Module):
"""
consist of MultiHeadAttention which is used in calculating self attention and cross attention
and PosWiseFeedForward.
"""
def __init__(self):
super(DecoderLayer, self).__init__()
self.self_attn_layer = MultiHeadAttention()
self.cross_attn_layer = MultiHeadAttention()
self.ff_layer = PosWiseFeedForward()
def forward(self, decoder_input, encoder_outputs, decoder_attn_mask, decoder_encoder_attn_mask):
"""
inputs -> cal self_attention -> cal corss_attention -> project previous outputs
:param decoder_input: (batch_size, tgt_len, d_model)
:param encoder_outputs: (batch_size, src_len, d_model)
:param decoder_attn_mask: (batch_size, tgt_len, tgt_len)
:param decoder_encoder_attn_mask: (batch_size, tgt_len, src_len)
"""
# decoder_output.shape: (batch_size, tgt_len ,d_model)
# decoder_attn.shape: (batch_size, num_heads, tgt_len, tgt_len)
decoder_outputs, decoder_self_attn\
= self.self_attn_layer(decoder_input, decoder_input, decoder_input, decoder_attn_mask)
# decoder_outputs.shape: (batch_size, tgt_len, d_model)
# decoder_cross_attn.shape: (batch_size, num_heads, tgt_len, src_len)
decoder_outputs, decoder_cross_attn = \
self.cross_attn_layer(decoder_outputs, encoder_outputs, encoder_outputs, decoder_encoder_attn_mask)
decoder_outputs = self.ff_layer(decoder_outputs)
return decoder_outputs, decoder_self_attn, decoder_cross_attn
class Decoder(nn.Module):
""" consist of stacked decoder layer and embedding layer(word + position). """
def __init__(self, target_vocab_size, max_length=256):
super(Decoder, self).__init__()
self.word_embedding = nn.Embedding(target_vocab_size, d_model)
self.position_embedding = nn.Embedding.from_pretrained(
get_sinusoid_encoding_table(max_length, d_model), freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(num_layers)])
def forward(self, decoder_inputs, encoder_inputs, encoder_outputs):
"""
x -> embedding -> each decoder layer
:param decoder_inputs: (batch_size, tgt_len)
:param encoder_inputs: (batch_size, src_len)
:param encoder_outputs: (batch_size, src_len, d_model)
"""
word_embedding = self.word_embedding(decoder_inputs)
pos = torch.tensor([[pos_idx for pos_idx in range(decoder_inputs.size(1))]
for _ in range(decoder_inputs.size(0))], dtype=torch.int).unsqueeze(0)
position_embedding = self.position_embedding(pos)
decoder_outputs = word_embedding + position_embedding # (batch_size, tgt_len, d_model)
decoder_self_attn = get_attn_pad_mask(decoder_inputs, decoder_inputs) # (batch_size, tgt_len, tgt_len)
decoder_subsequence_attn = get_attn_subsequence_mask(decoder_inputs) # (batch_size, tgt_len, tgt_len)
# combine self attention and subsequence attention in first sublayer of decoder layer
decoder_self_attn = torch.gt((decoder_self_attn + decoder_subsequence_attn), 0)
decoder_cross_attn = get_attn_pad_mask(decoder_inputs, encoder_inputs) # (batch_size, tgt_len, src_len)
decoder_self_attentions, decoder_cross_attentions = list(), list()
for layer in self.layers:
# decoder_outputs.shape: (batch_size, tgt_len, d_model)
# self_attn.shape: (batch_size, num_heads, tgt_len, tgt_len)
# cross_attn.shape: (batch_size, num_heads, tgt_len, src_len)
decoder_outputs, self_attn, cross_attn =\
layer(decoder_outputs, encoder_outputs, decoder_self_attn, decoder_cross_attn)
decoder_self_attentions.append(self_attn)
decoder_cross_attentions.append(cross_attn)
return decoder_outputs, decoder_self_attentions, decoder_cross_attentions
class Transformer(nn.Module):
""" https://blog.csdn.net/qq_37236745/article/details/107352273 """
def __init__(self, source_vocab_size, target_vocab_size):
super(Transformer, self).__init__()
self.encoder = Encoder(source_vocab_size=source_vocab_size)
self.decoder = Decoder(target_vocab_size=target_vocab_size)
self.proj_layer = nn.Linear(d_model, target_vocab_size, bias=False)
def forward(self, encoder_inputs, decoder_inputs):
"""
:param encoder_inputs: (batch_size, src_len)
:param decoder_inputs: (batch_size, tag_len)
"""
# encoder_outputs.shape: (batch_size, src_len ,d_model)
# encoder_attentions.shape: (batch_size, num_heads, src_len, src_len)
encoder_outputs, encoder_attentions = self.encoder(encoder_inputs)
# decoder_outputs.shape: (batch_size, tgt_len, d_model)
decoder_outputs, decoder_self_attentions, decoder_cross_attentions =\
self.decoder(decoder_inputs, encoder_inputs, encoder_outputs)
decoder_outputs = self.proj_layer(decoder_outputs)
return decoder_outputs, encoder_attentions, decoder_self_attentions, decoder_cross_attentions
参考资料:
1. BERT和Transformer理解及测试
2. 自然语言处理中的Transformer和BERT
3. Bert系列
4. Fine-Tuning 与 Feature-Based strategy 的区别
5. https://blog.csdn.net/qq_37236745/article/details/107352273















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









