







 UniLMs是统一语言模型预训练的代表,通过不同的注意力机制支持单向、双向和序列到序列任务。UniLMv2引入了PMLM,结合了自编码和部分自回归预训练任务,解决了BERT的独立性假设问题。在预训练阶段,模型随机执行三种任务之一,而在Fine-Tuning阶段,根据任务类型调整注意力机制。PMLM通过插入[M]和[P]标记来控制上下文环境的变化,用于NLU和NLG任务。
UniLMs是统一语言模型预训练的代表,通过不同的注意力机制支持单向、双向和序列到序列任务。UniLMv2引入了PMLM,结合了自编码和部分自回归预训练任务,解决了BERT的独立性假设问题。在预训练阶段,模型随机执行三种任务之一,而在Fine-Tuning阶段,根据任务类型调整注意力机制。PMLM通过插入[M]和[P]标记来控制上下文环境的变化,用于NLU和NLG任务。
UniLMs
UniLMs由《Unified Language Model Pre-training for Natural Language Understanding and Generation》(2019)提出,其核心是通过不同的注意力机制,在同一模型下进行Unidirectional Language Model, Bidirectional Language Model, 与 Sequence to Sequence Language Model三种任务。
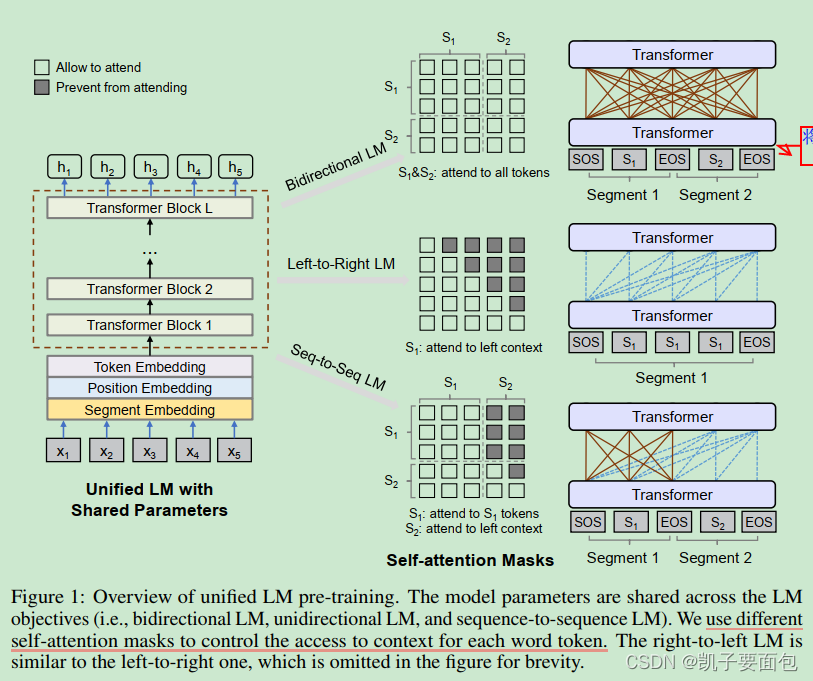
- Bidirectional LM:能够看到全部上下文与自身。
- Left-to-Right LM:只能看到左侧的上下文与自身。
- Seq-to-Seq LM:对于源序列,可以看到全部上下文及自身;对于目标序列,能看到源序列的所有信息,以及目标序列的左侧上下文及自身。
- 预训练阶段,对于一个Batch,随机选择做三种任务中的一种。
UniLMv2
UniLMv2 提出 PMLM (Pseudo Masked Language Model),在一个前向传播步骤中,同时做 AutoEncoding MLM与 Partially AutoRegressive MLM,并且解决 BERT MLM 中 “[MASK]”独立性假设的问题。
预训练任务
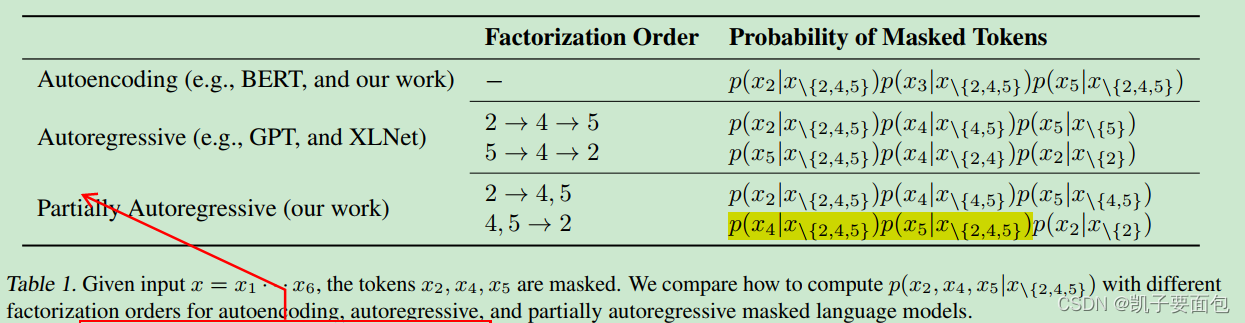
作者将 MLM 任务分为三类,分别为“AutoEncoding, AutoRegressive, Partially AutoRegressive”, 三者的区别如下图:
-
MLM 是指 “在一定上下文环境下,进行预测”。
-
AutoEncoding MLM 中,假设所有 MASK 是相互独立,因此对于每一个 MASK, 其预测的上下文环境是静态不变的,因此可以并行计算,此情形与 BERT MLM 一致。
-
AutoEncoding MLM 与 AutoRegressive MLM 、 Partially AutoRegressive MLM 的核心区别在于, 前者的上下文环境是静态的, 而后者是变化地, 随着因式分解步骤的增加,上下文信息量也随之增加。
-
AutoRegressive MLM 与 Partially AutoRegressive MLM 的核心区别在于,在每一因素分解步骤中, AutoRegressive MLM 预测的数量总是为1, 而 Partially AutoRegressive MLM 可以大于1。
-
在 Partially AutoRegressive MLM 中,对于一个 Spaned MASK(连续mask多个token),在某一因式分解步骤中,该 Span 内的所有tokens,任然在“独立性假设”条件下进行预测。
即假设存在 M = < M 1 , M 2 , . . . , M m > M = <M_1, M_2, ..., M_m> M=<M1,M2,...,Mm> 因式分解顺序, M i M_i Mi 表示一个集合, M i = M 1 i , M 2 i , . . . , M n i M_i = {M_1^i, M_2^i, ..., M_n^i} Mi=M1i,M2i,...,Mni,至少有一个集合的数量大于1, 那么:
P ( x M ∣ x n o t M ) = ∏ i m P ( M t ∣ M n o t , M > = t ) = ∏ i m ∏ j n P ( x j i ∣ M n o t , M > = t ) P(x_M|x_{not M}) = \prod_i^mP(M_t|M_{not , M_{>=t}}) \newline =\prod_i^m\prod_j^nP(x_j^i|M_{not , M_{>=t}}) P(xM∣xnotM)=i∏mP(Mt∣Mnot,M>=t)=i∏mj∏nP(xji∣Mnot,M>=t) -
本论文采用Transformer结构,同时进行 AutoEncoding MLM 与 Partially AutoRegressive MLM。在数据处理阶段, MASK采用如下策略,遮掩 15% 的原始输入, 每一遮掩部分在40%的情况下, 为Ngram(2-6),60%条件下为1。
PMLM
由于每一因式分解步骤中, Partially AutoRegressive MLM 的上下文环境会变化,可以把 P 当成一个 Placeholder。假设输入序列为 x 1 , x 2 , x 3 , x 4 , x 5 , x 6 x1, x2, x3, x4, x5, x6 x1,x2,x3,x4,x5,x6,遮掩的集合为 { x 2 } , { x 4 , x 5 } \{x2\},\{x4, x5\} {x2},{x4,x5}, 因式分解顺序为{x4, x5} ->{x2}。
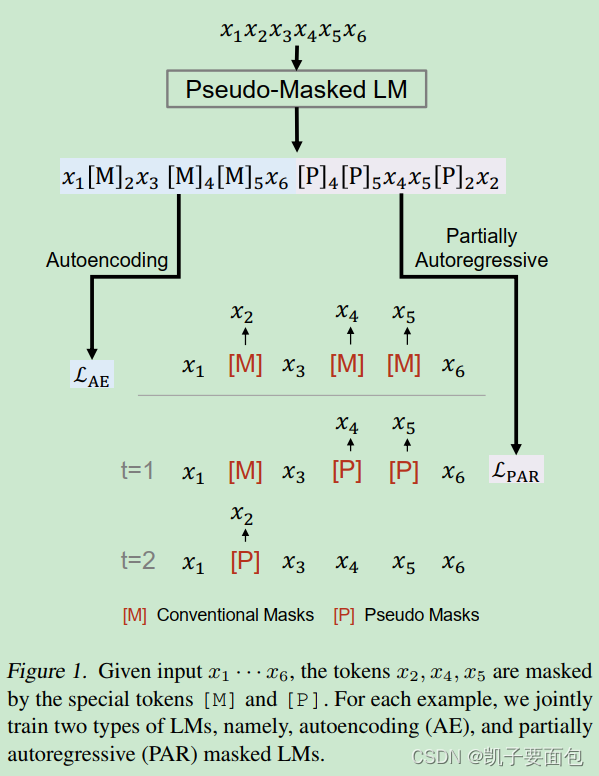
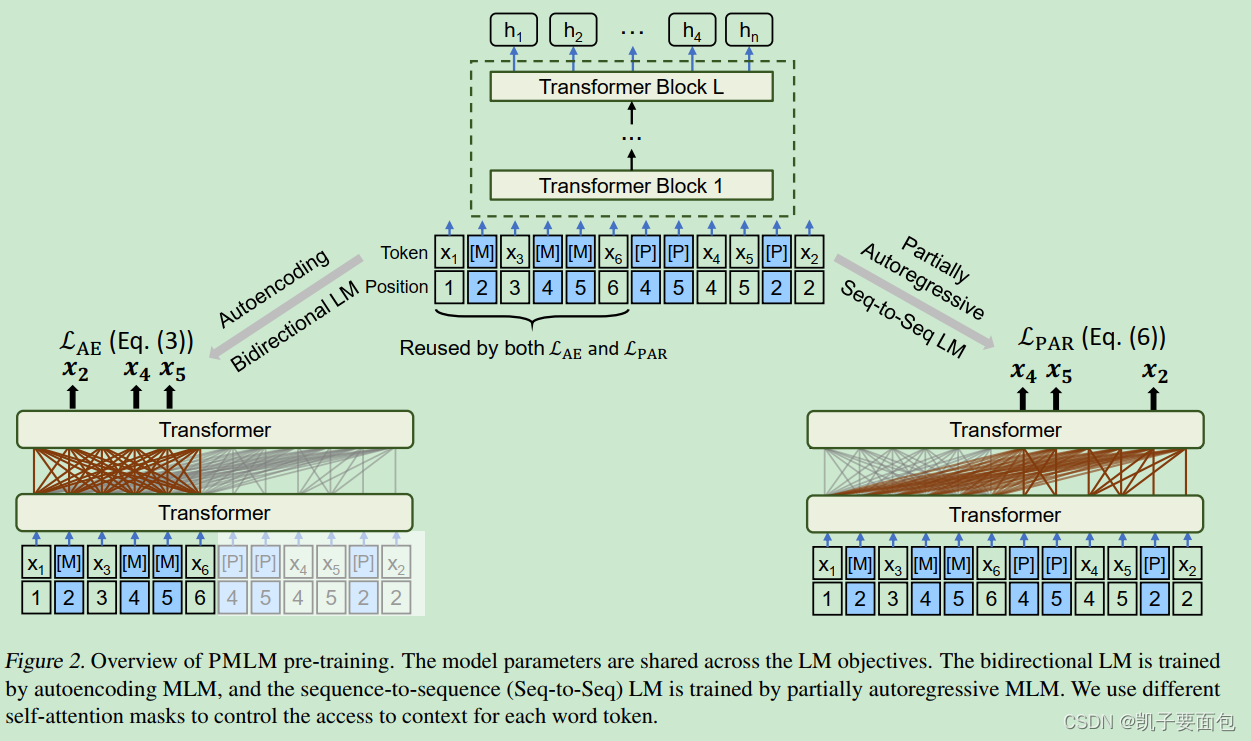
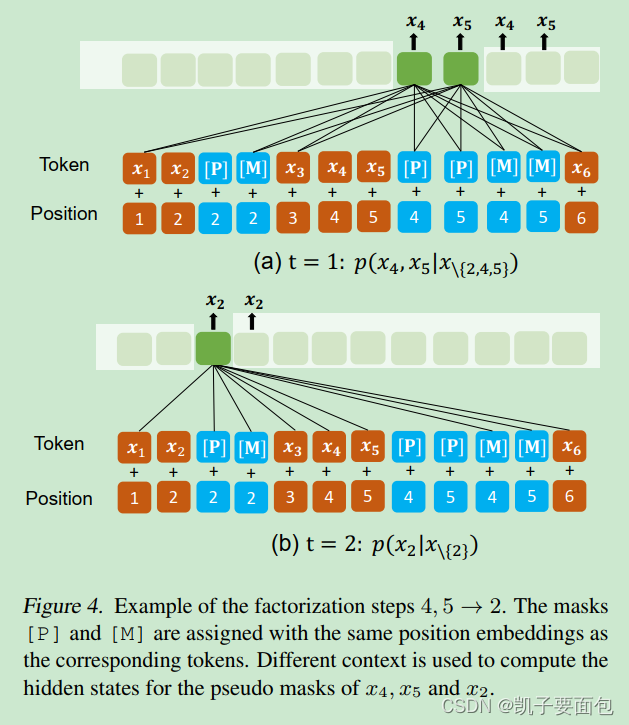
- 在每一mask的位置后,插入[M] 与 [P], [M] 与 [P] 、被遮掩的原始输入具有相同的位置编码,并且原始输入不会被替换,依然存在于原始序列中。
- Tansformer 是 position agnostic, 不同token具有同一位置编码信息,对于模型而言相当于处在同一序列位置。
- Partially AutoRegressive MLM 任务, 顶层的 [P] 位置对应的隐向量会喂进分类器。
- AutoEncoding MLM 任务, 顶层的 [M] 位置对应的隐向量会喂进分类器。
- Partially AutoRegressive MLM 任务与AutoEncoding MLM 任务是互补的, AutoEncoding MLM 任务在于捕获 UnMasked Context 与 [M], 而 Partially AutoRegressive MLM 任务在于捕获 M i M_i Mi之间的关系。
- 注意力机制控制上下文环境的变化, [P] 不能 attend self,
M
t
M_t
Mt 不能 attend
M
>
=
t
M_{>=t}
M>=t。

Fine-Tuning
在 Fine-Tuning 阶段,对于 NLU 任务,与 BERT 类似。对于 NLG 任务, 如 [ S O S ] s o u r c e [ E O S ] t a r g e t [ E O S ] [SOS] source [EOS] target [EOS] [SOS]source[EOS]target[EOS], s o u r c e source source 部分采用全注意机制, 而 target 部分, 每一个词添加 $[P] $, 并采用对角线注意力机制, 与 UniLMs 中的 Seq-Seq LM 相似。

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









