







目录
一、视频学习和论文阅读
1.ResNet
介绍
ResNet在2015年由何凯明团队提出,斩获当年ImageNet竞赛中 分类任务第一名,目标检测第一名。获得COCO数据集中目标 检测第一名,图像分割第一名。
网络中的亮点:
- 超深的网络结构(突破1000层)
- 提出residual模块
- 使用Batch Normalization加速训练(丢弃dropout)

网络层越深越好吗?
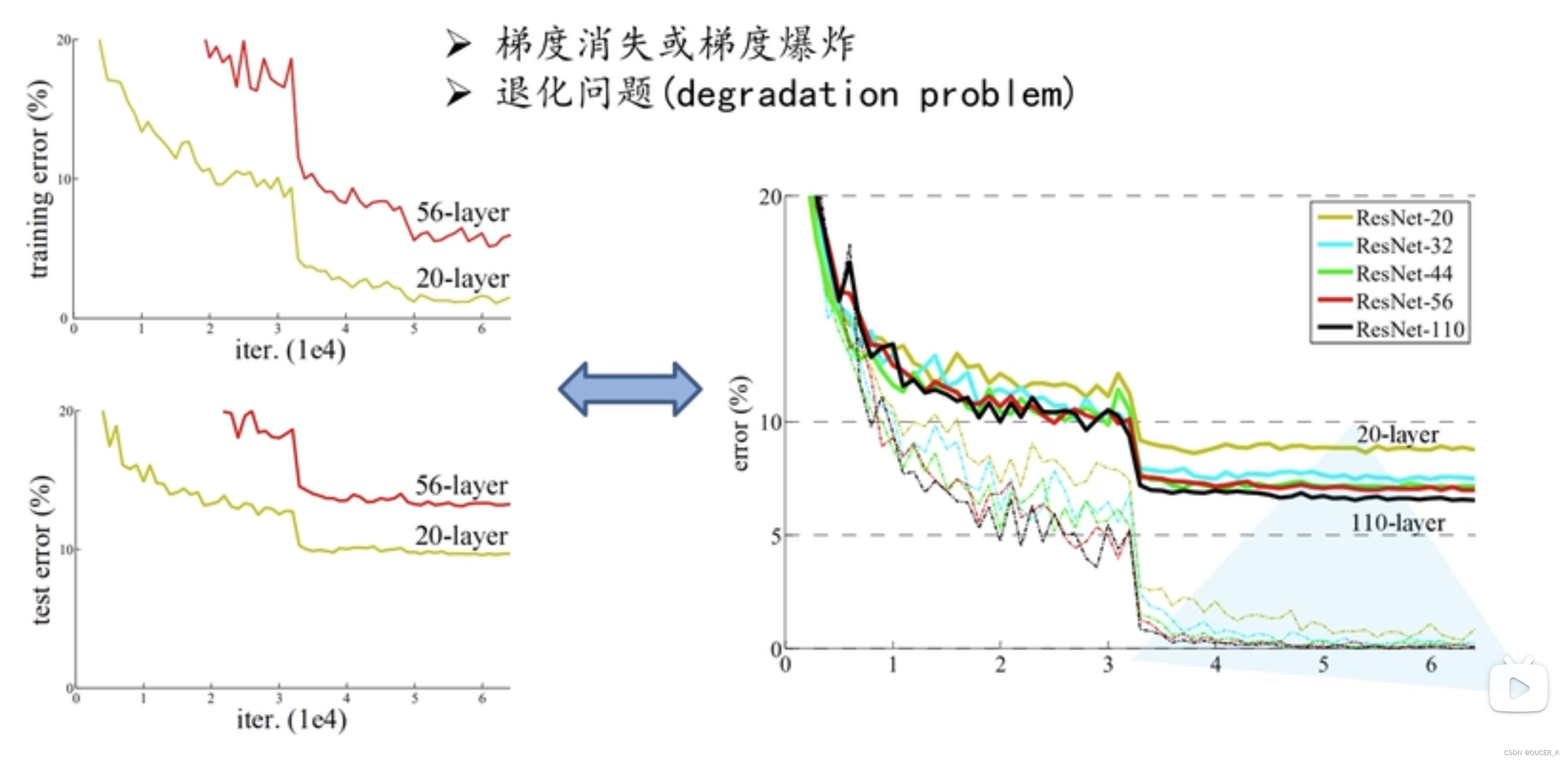
经实验数据证明:当网络堆叠到一定深度时,反而会出现深层网络比浅层网络效果差的情况。
- 对于梯度消失或梯度爆炸问题,Deep Residual Learning for Image Recognition论文提出通过数据的预处理以及在网络中使用 Batch Normalization层来解决。其中Batch Normalization层可以防止每次迭代的梯度变得太大或太小。
- 对于退化问题,该论文提出了residual结构(残差结构)来减轻退化问题,使用residual结构的卷积网络,随着网络的不断加深,效果并没有变差,会变得更好。
残差结构
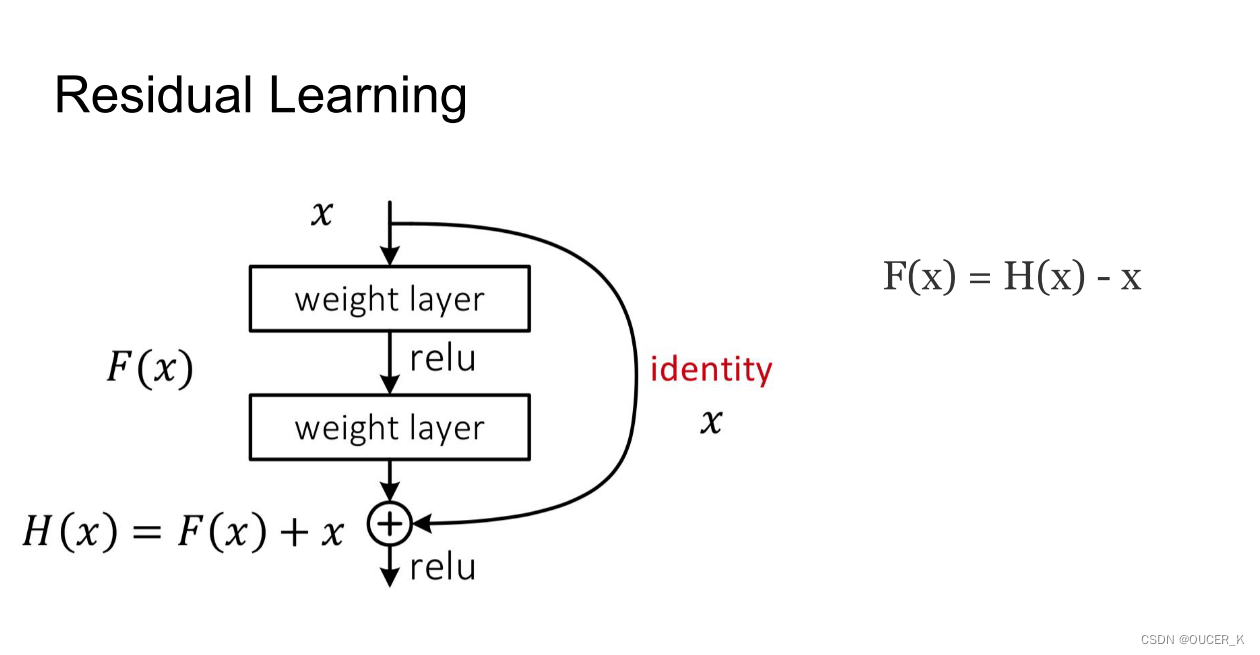
- 若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。
- 而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即H(X) - X即学习X -> (H(X) - X) + X。其中X这一部分为直接的identity mapping,而H(X) - X则为有参网络层要学习的输入输出间残差。
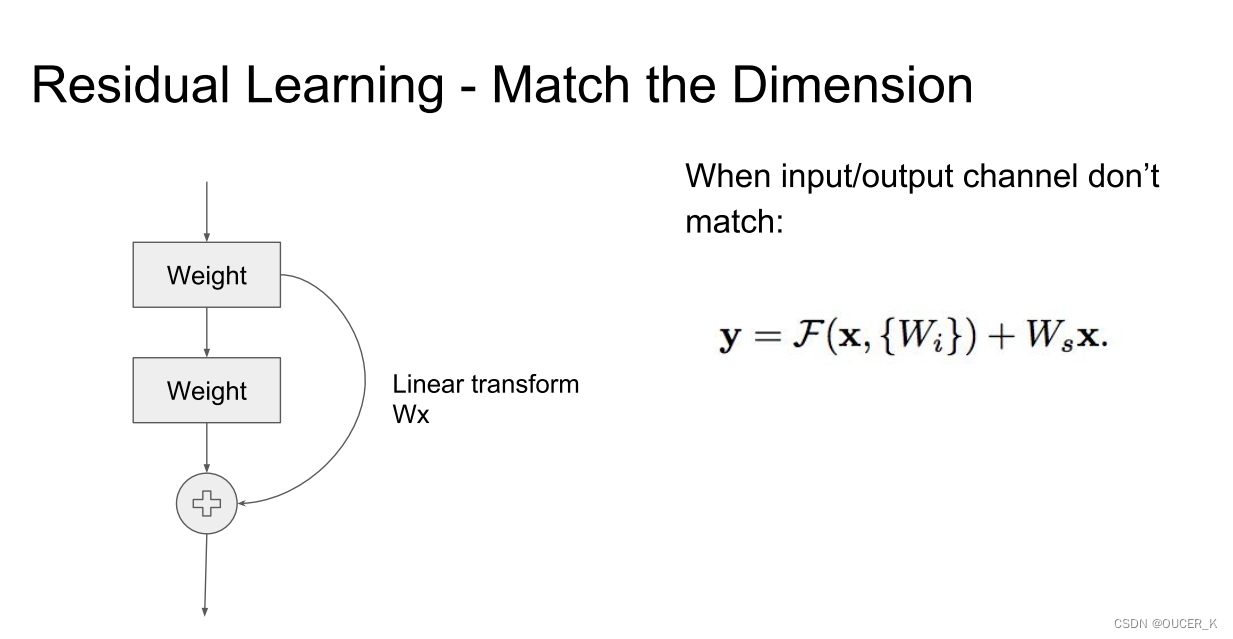
当输入输出通道不匹配时,可以通过建立一种有效的identity mapping函数(即恒等映射)从而可以使得处理后的输入X与输出Y的通道数目相同即Y = F(X, Wi) + Ws*X。 Wx为linear projection 线性投影。
虚线和实线残差结构
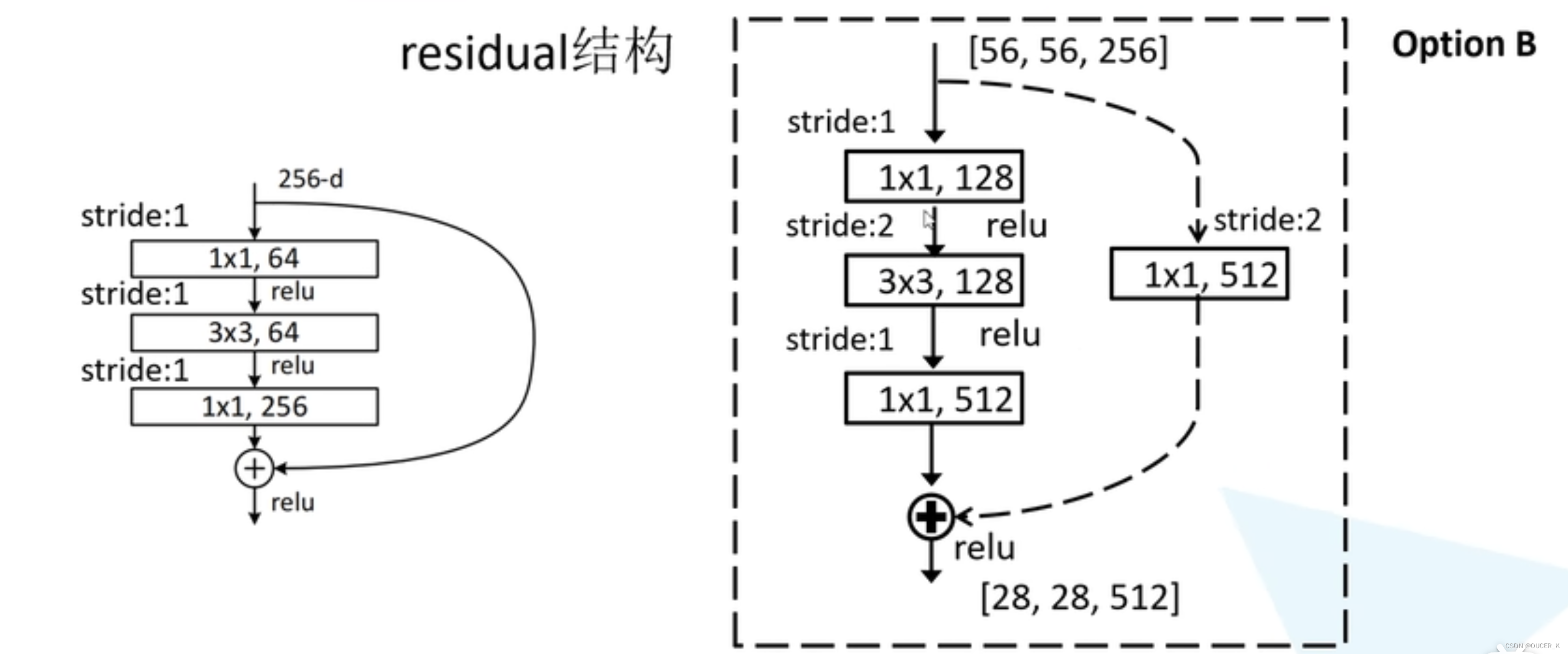
实线表示identity shortcut,虚线表示projection shortcut. 出现projection shortcut的原因是模型内部的操作改变了feature map的尺寸(height, width, channel),我们需要一个projection来match dimension。
各个深度的ResNet
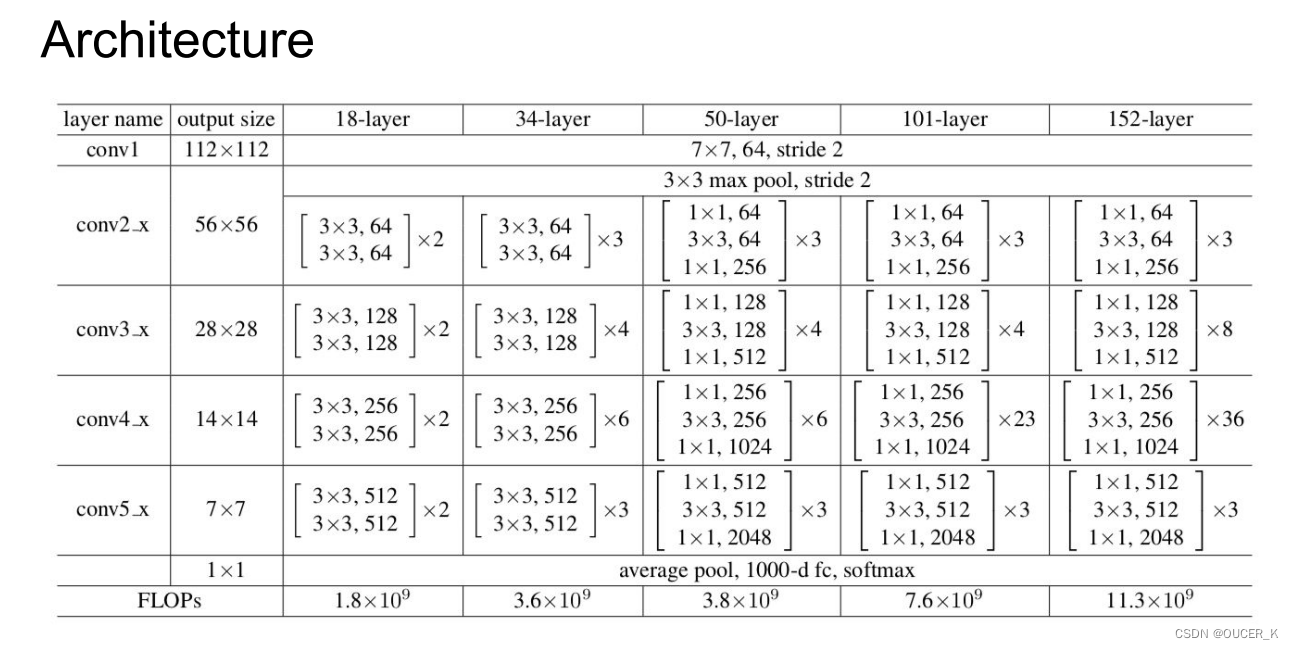
Batch Normalization

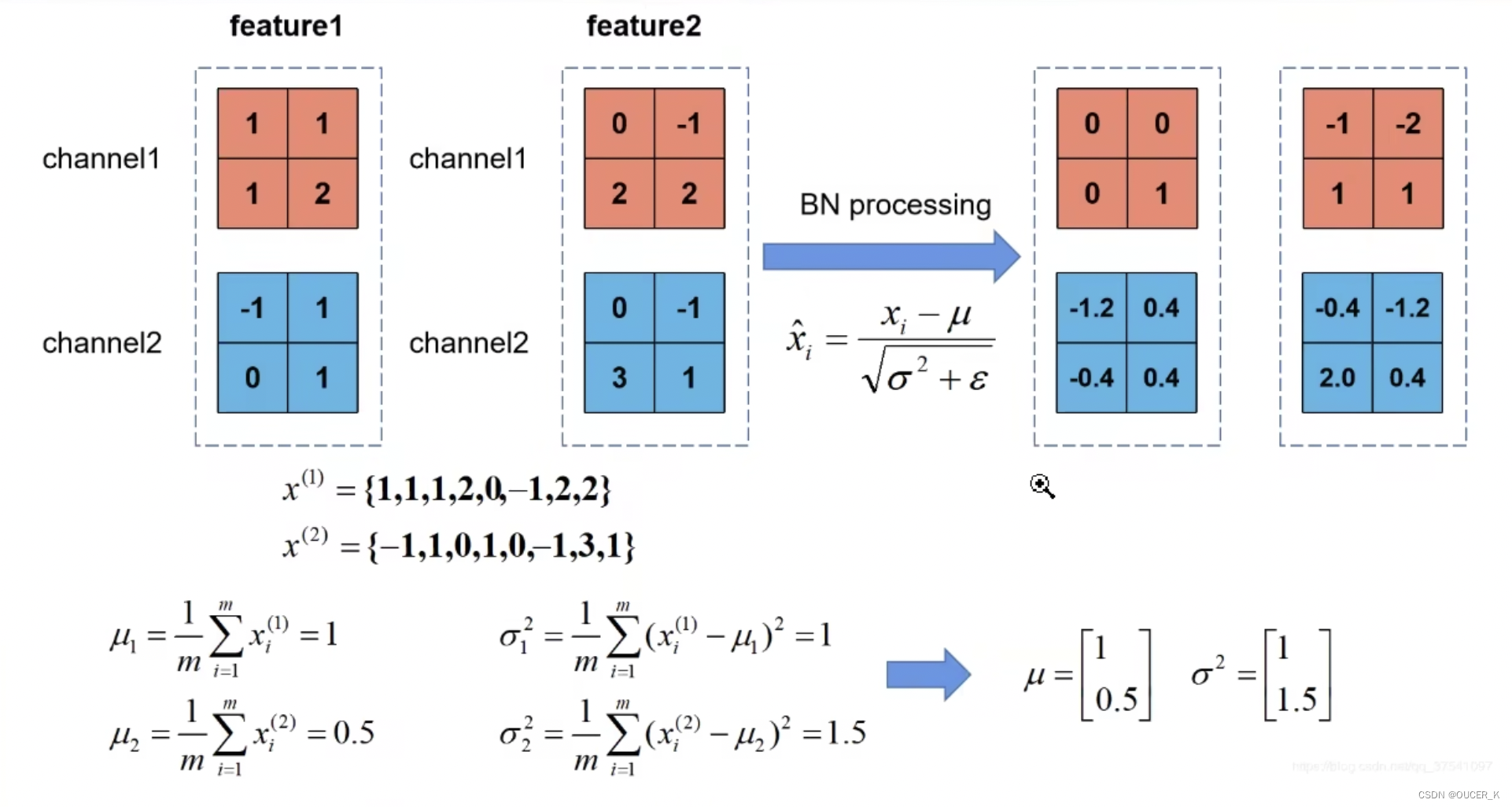
BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布。进一步说,对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
迁移学习
使用迁移学习能够快速训练出一个理想的结果,即使在数据集较小的情况下也可以实现。
常见的迁移学习方式:
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入权重后在原网络基础上再添加一次全连接层,仅训练最后一个全连接层
2.ResNeXt
介绍
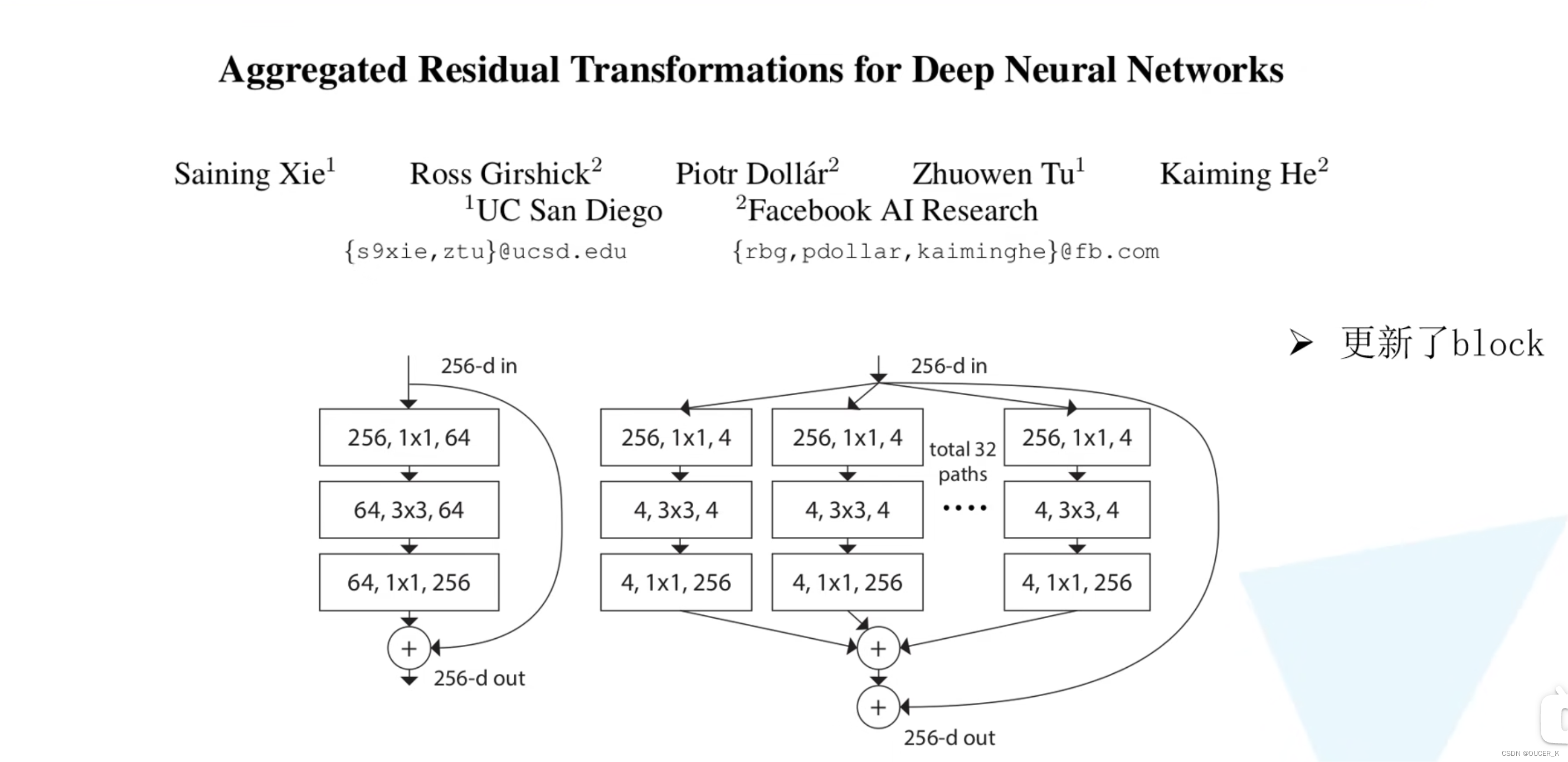
Aggregated Residual Transformations for Deep Neural Networks论文得知,在 ImageNet-1K 数据集上,经验表明,即使在保持复杂性的限制条件下,增加基数也能够提高分类精度。此外,当增加容量时,增加基数比更深或更宽更有效。模型名为 ResNeXt,是进入 ILSVRC 2016 分类任务的基础,在该任务中获得了第二名。
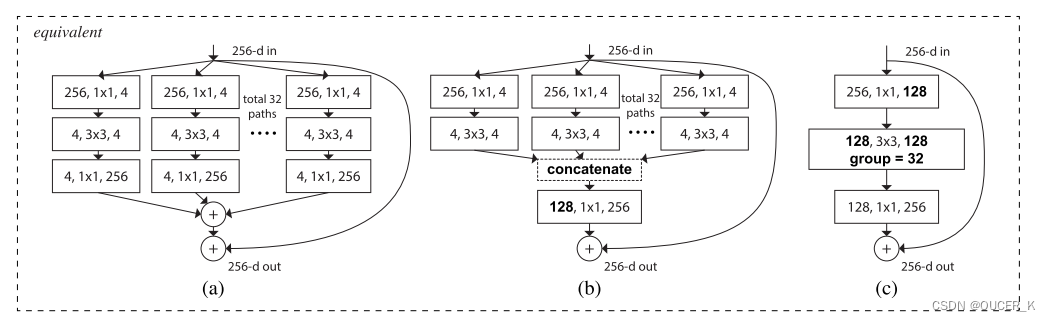
论文提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
a是ResNeXt基本单元,如果把输出的1x1合并到一起,得到等价网络b拥有和Inception-ResNet相似的结构,而进一步把输入的1x1也合并到一起,得到等价网络c则和通道分组卷积的网络有相似的结构。上面的block模块,它们在数学计算上完全等价。
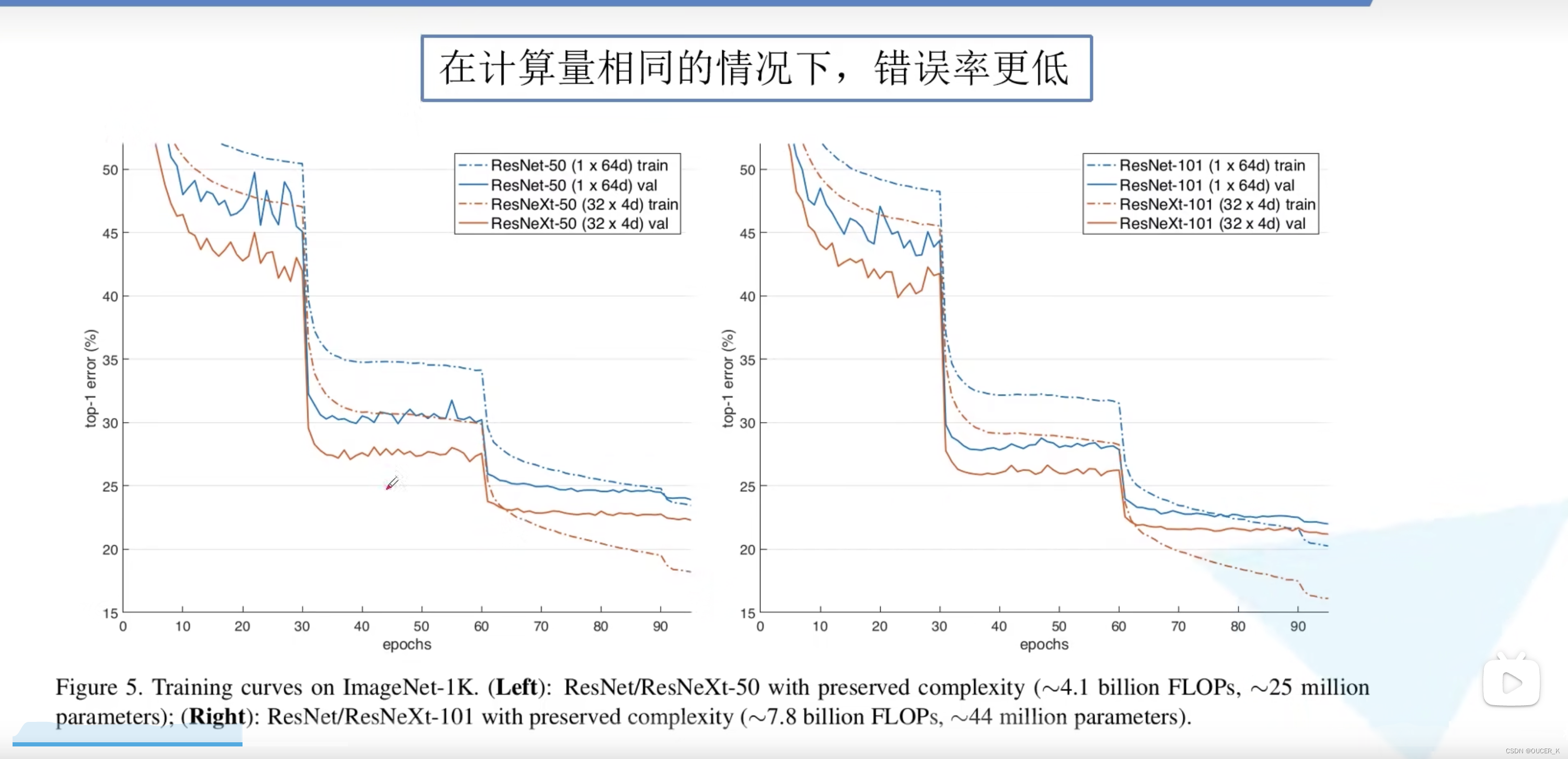 在 ImageNet-5K 集和 COCO 检测集上进一步研究 ResNeXt,也显示出比 ResNet 更好的结果。
在 ImageNet-5K 集和 COCO 检测集上进一步研究 ResNeXt,也显示出比 ResNet 更好的结果。
论文中的方法表明,除了宽度和深度的维度之外,基数(变换集的大小)是一个具体的、可测量的维度,它具有核心重要性。实验表明,与更深或更宽相比,增加基数是一种更有效的获得准确性的方法,尤其是当深度和宽度开始为现有模型带来递减收益时。上图,在 Inception 模块中,输入被分成几个低维嵌入(通过 1×1 卷积),由一组专门的过滤器(3×3、5×5 等)进行转换,并通过连接合并。
网络结构与性能
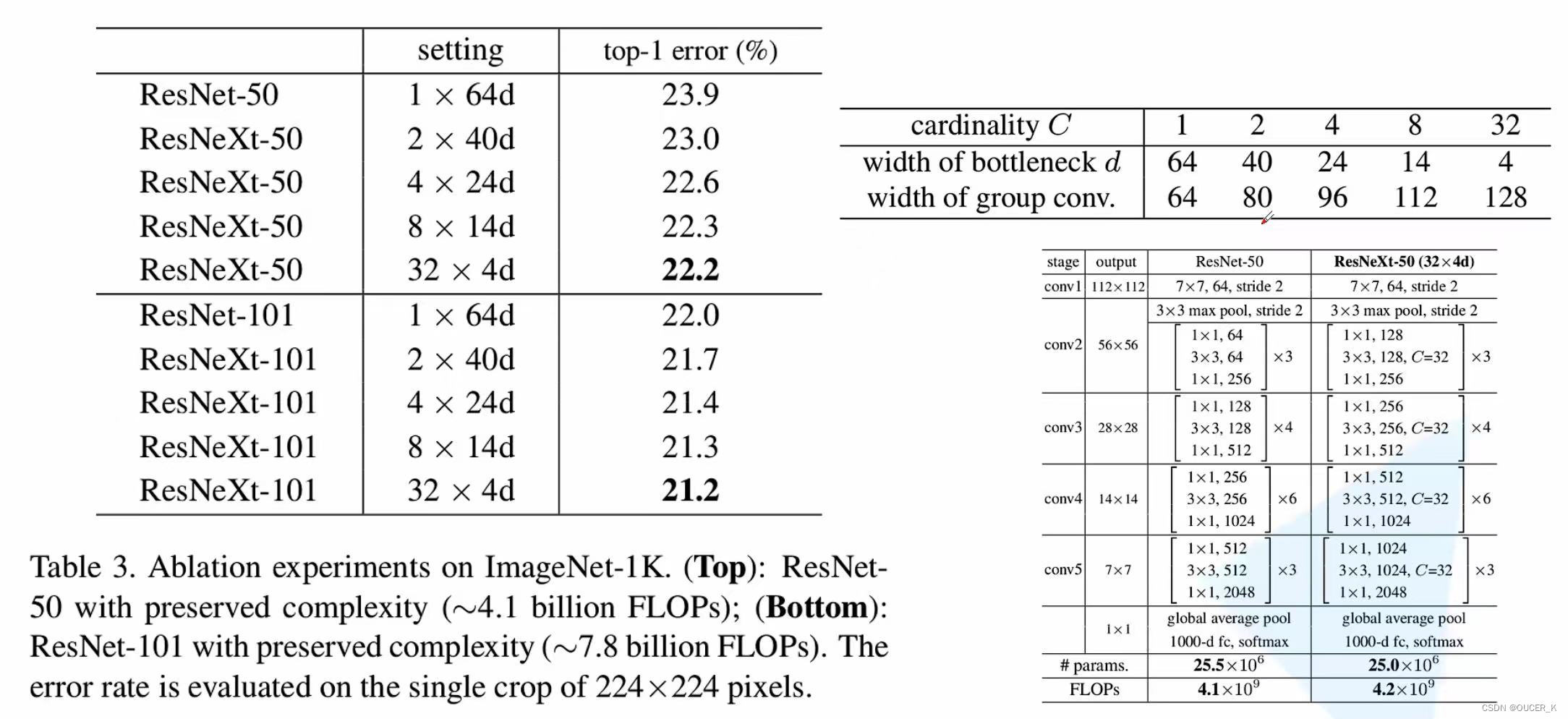
- 上图表明,在保留复杂性的情况下,当瓶颈宽度小时,以减小宽度为代价增加基数开始显示出饱和精度。我们认为在这种权衡中不断减小宽度是不值得的。所以下面我们采用不小于4d的瓶颈宽度。
- 受 VGG/ResNets 启发的两个简单规则的约束:(i)如果生成相同大小的空间图,则这些块共享相同的超参数(宽度和过滤器大小),以及(ii ) 每次对空间图进行 2 倍下采样时,块的宽度就会乘以 2 倍。根据这两条规则,设计一个模板模块,一个网络中的所有模块都可以据此确定。所以这两条规则极大地缩小了设计空间,让我们可以专注于几个关键因素。如上图所示。
二、代码练习
1.用类似 LetNet 的网络结构训练测试
网络定义代码如下:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.conv3 = nn.Conv2d(16, 32, 4)
self.conv4 = nn.Conv2d(32, 32, 4)
self.conv5 = nn.Conv2d(32, 32, 5)
self.conv6 = nn.Conv2d(32, 32, 6)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32, 16)
self.fc2 = nn.Linear(16, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = F.relu(self.conv5(x))
x = x.view(-1, 32)
x = F.relu(self.fc1(x))
x = F.softmax(self.fc2(x), dim=1)
return x
2.用类似 ResNet 的网络结构训练测试
网络定义代码如下:
class Net(nn.Module):
def __init__(self, model):
super(Net, self).__init__()
# 取掉model的后1层
self.resnet_layer = nn.Sequential(*list(model.children())[:-1])
self.Linear_layer = nn.Linear(2048, 2) #加上一层参数修改好的全连接层
def forward(self, x):
x = self.resnet_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
return x
model_new = Net(model)
model_new = model_new.to(device)3.测试结果
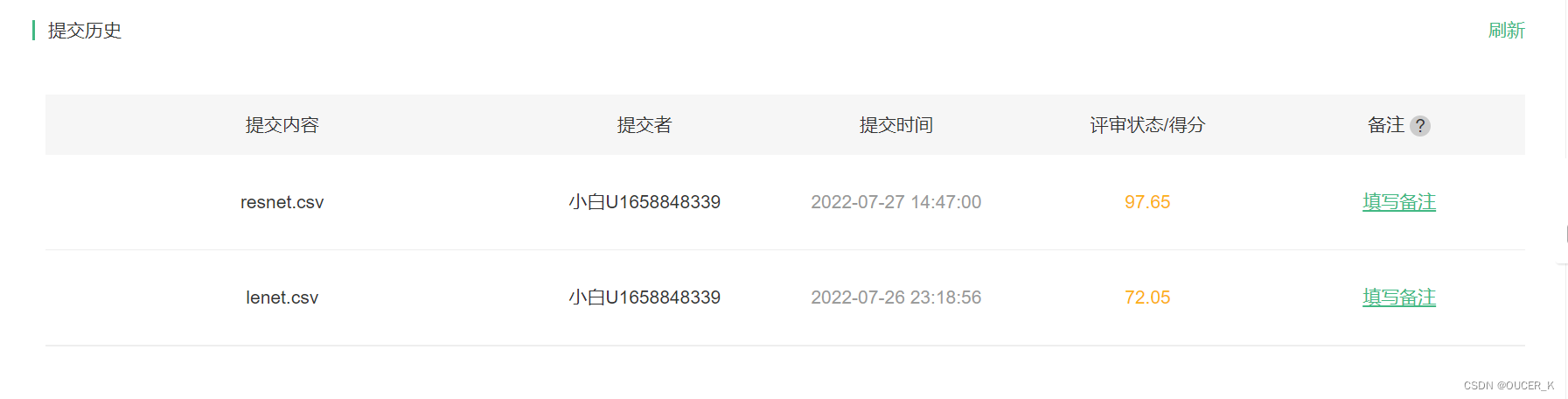
- 我们可以看出使用ResNet的准确率要明显高于LeNet,即使ResNet训练的epoch轮数很少。
- 大部分情况下,优化器Adam效果相较SGD更好,然而在ResNet下,SGD效果比Adam好。
- 学习率的调整可采用动态的方式。学习率太小收敛太慢,学习率太大会导致参数在最优点来回波动。通常先采用较大学习率进行训练,在训练过程中不断衰减。
问题总结
Residual learning
- Residual learning解决了深层网络中梯度退化和精度下降(训练集)的问题,使网络能够越来越深,既保证了精度,又控制了速度。
Batch Normailization 的原理
- BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布。
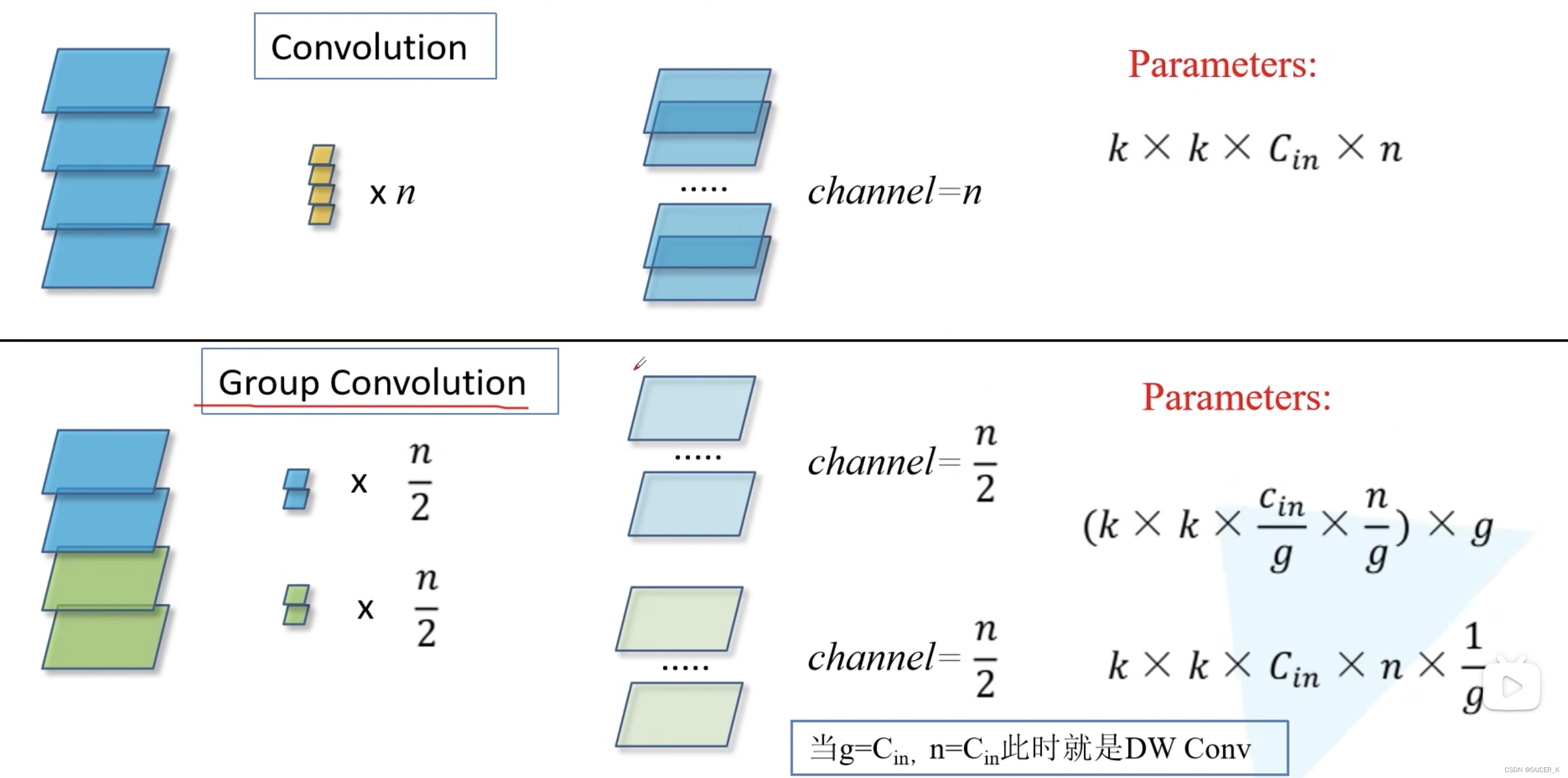
为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
- 因为分组卷积能够在不明显增加参数量级、不提升计算复杂度的情况下提升模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
- 分组卷积的一个弊端是组与组之间没有信息流通的渠道,导致网络的特征提取能力下降。通常选择分组数为32构建的网络性能最佳。















 1218
1218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









