






CLIP
Learning Transferable Visual Models From Natural Language Supervision 2021
contribution
- 使用自然语言作为监督信息,训练一个迁移效果很好的视觉模型,摆脱固定类别标签的限制(categorical label)
- 学习到的预训练模型可以直接在下游任务做zero-shot推理
- 对30多个数据集、多种不同下游任务上进行测试来评估性能,能达到和有监督的baseline方法差不多的性能
Method
预训练

模型输入图片文字对,通过encoder得到文本图像特征,每个training batch里有n个图片-文本对,然后在这些特征上做对比学习,特征矩阵里对角线上的都是正样本,矩阵中非对角线上的元素都是负样本。

推理
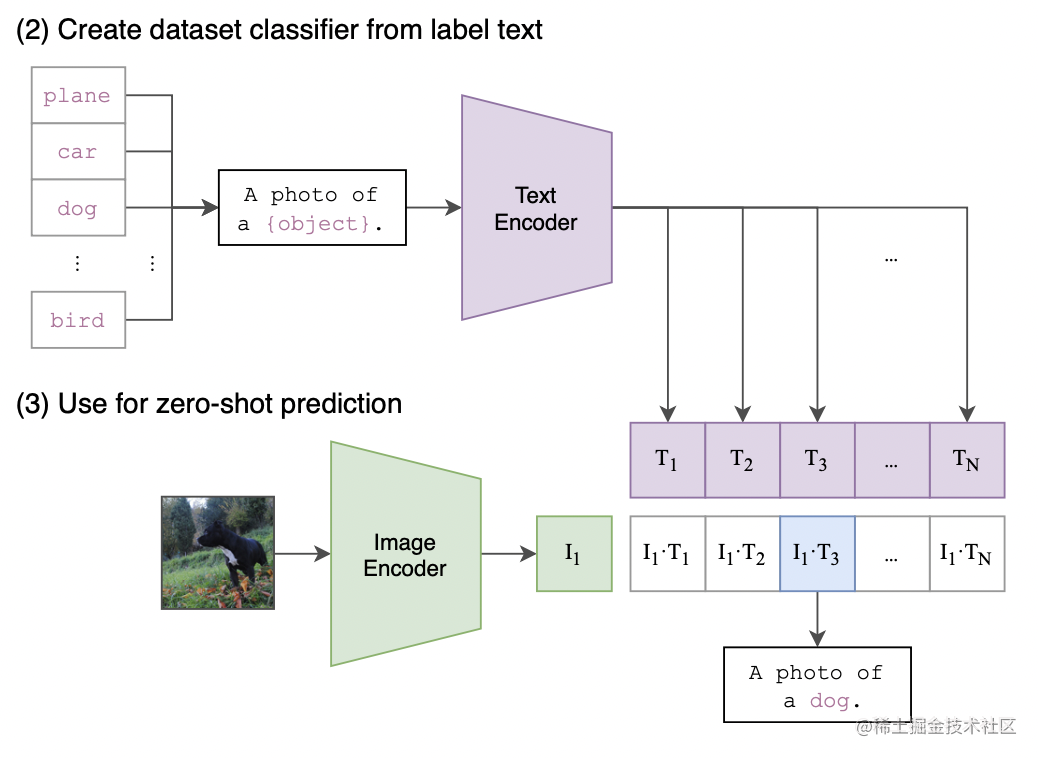
预训练后只得到文本和图片的特征,没有分类头。作者利用自然语言的方法,prompt template。把类别标签转换为句子。将图片的特征和不同的文本特征算余弦相似性,选最相似的那个文本特征对应的句子,从而完成了分类任务。彻底摆脱了categorical label的限制。
prompt
- 问题: 歧义、distribution gap(训练输入句子、推理是单词)
- prompt是在做微调或者直接做推理时的一种方法,起到的是一个提示的作用,也就是文本的引导作用。
- prompt engineer 利用这个模板(如:“A photo of a {label}.”)把单词变成一个句子
- prompt ensembling 使用多个模版集成zero shot classifiers
training
- dataset:WIT 400 million (image, text) pairs
- image encoder:a series of 5 ResNets and 3 Vision Transformers
- text encoder:transformer
- details:32 epoches,adam ,基于grid searches,random search和manual tuning调整超参
















 2946
2946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









