







算法性能分析
1 时间复杂度分析
定义:时间复杂度是一个函数,它定性描述该算法的运行时间。
假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 O(f(n))。
大O:算法导论给出的解释:大O用来表示上界的,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
算法导论给出了例子:拿插入排序来说,插入排序的时间复杂度我们都说是O(2) 。
输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是O(n),但如果数据是逆序的话,插入排序的时间复杂度就是O(n2),也就对于所有输入情况来说,最坏是O(n2) 的时间复杂度,所以称插入排序的时间复杂度为O(n2)。
同理再看一下快速排序,都知道快速排序是O(nlogn),但是当数据已经有序情况下,快速排序的时间复杂度是O(n2) 的,所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n2)。
但是依然说快速排序是O(nlogn)的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界。
例子:
找出n个字符串中相同的两个字符串(假设这里只有两个相同的字符串)。
(1)暴力枚举:除了n2 次的遍历次数外,字符串比较依然要消耗m次操作(m也就是字母串的长度),所以时间复杂度是O(m × n × n)。
(2) 先对n个字符串按字典序来排序,排序后n个字符串就是有序的,意味着两个相同的字符串就是挨在一起,然后在遍历一遍n个字符串,这样就找到两个相同的字符串了。快速排序时间复杂度为O(nlogn),依然要考虑字符串的长度是m,那么快速排序每次的比较都要有m次的字符比较的操作,就是O(m × n × log n) 。之后还要遍历一遍这n个字符串找出两个相同的字符串,别忘了遍历的时候依然要比较字符串,所以总共的时间复杂度是 O(m × n × logn + n × m)。简化后的时间复杂度是 O(m × n × log n)。
所以先把字符串集合排序再遍历一遍找到两个相同字符串的方法要比直接暴力枚举的方式更快。
2 递归算法的时间复杂度
如果对递归的时间复杂度理解的不够深入的话,同一道题目,同样使用递归算法,有的会写出了O(n)的代码,有的写出了O(logn)的代码。
递归算法的时间复杂度本质上是要看: 递归的次数 * 每次递归的时间复杂度(递归的时间复杂度 = 递归次数*每次递归中的次数)。递归次数:可以通过画递归树,数递归树的节点数,得到递归次数。
**例子:**求x的n次方
(1)最直接的方式,一个for循环求出结果,代码如下:
int function1(int x, int n) {
int result = 1; // 注意 任何数的0次方等于1
for (int i = 0; i < n; i++) {
result = result * x;
}
return result;
}
时间复杂度为O(n)
(2)考虑一下递归算法:
int function2(int x, int n) {
if (n == 0) {
return 1; // return 1 同样是因为0次方是等于1的
}
return function2(x, n - 1) * x;
}
表面上这个代码的时间复杂度是O(log n),其实并不是这样,递归算法的时间复杂度本质上是要看: 递归的次数 * 每次递归中的操作次数。
每次n-1,递归了n次时间复杂度是O(n),每次进行了一个乘法操作,乘法操作的时间复杂度一个常数项O(1),所以这份代码的时间复杂度是 n × 1 = O(n)。
(3)优化一下的递归算法:
int function3(int x, int n) {
if (n == 0) return 1;
if (n == 1) return x;
if (n % 2 == 1) {
return function3(x, n / 2) * function3(x, n / 2)*x;
}
return function3(x, n / 2) * function3(x, n / 2);
}
首先看递归了多少次呢,可以把递归抽象出一棵满二叉树。刚刚同学写的这个算法,可以用一棵满二叉树来表示(为了方便表示,选择n为偶数16),如图:
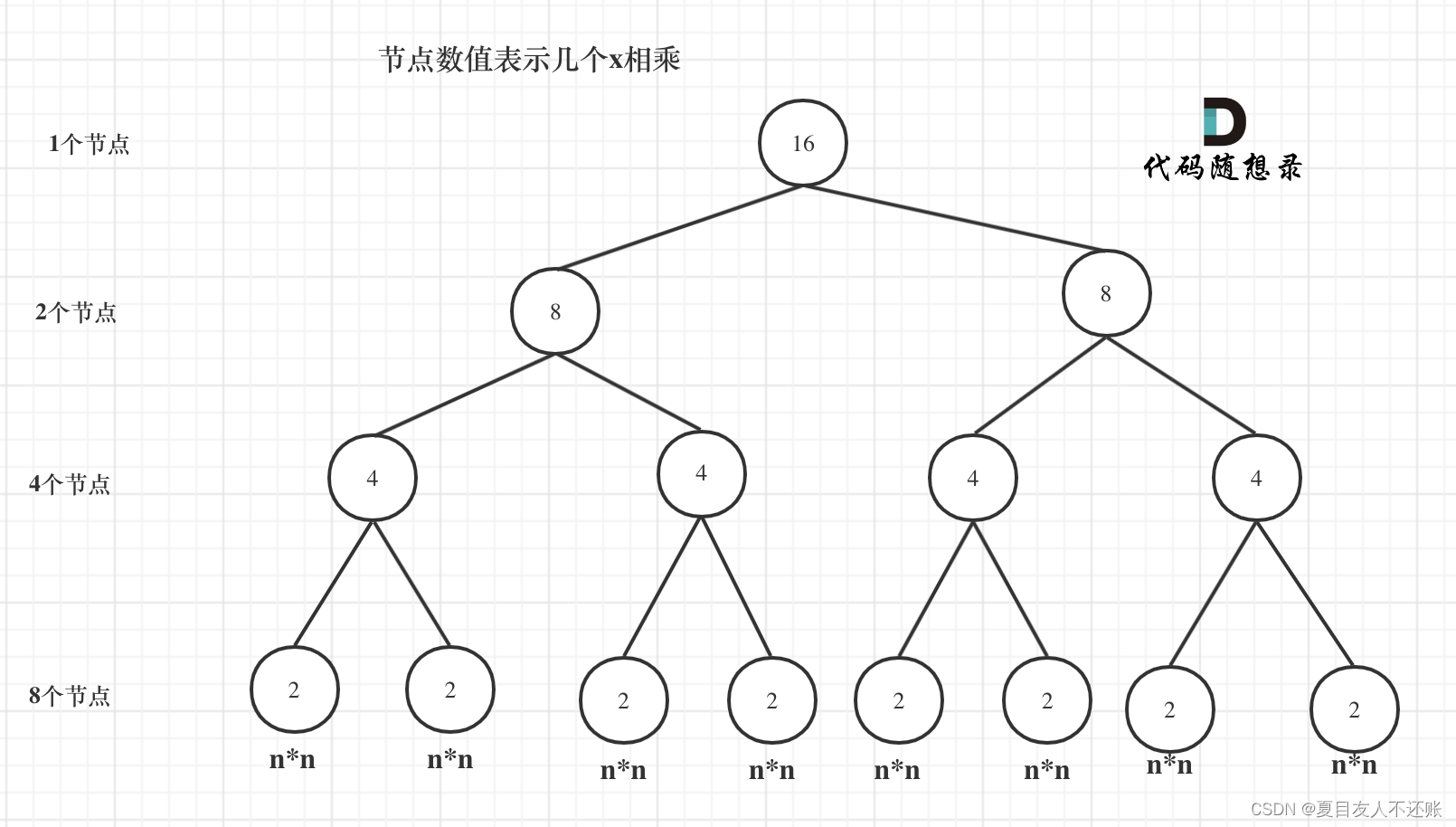
这棵树上每一个节点就代表着一次递归并进行了一次相乘操作,所以进行了多少次递归的话,就是看这棵树上有多少个节点。
求满二叉树节点数量:2^3 + 2^2 + 2^1 + 2^0 = 15。
如果是求x的n次方,这个递归树有多少个节点呢,如下图所示:(m为深度,从0开始)
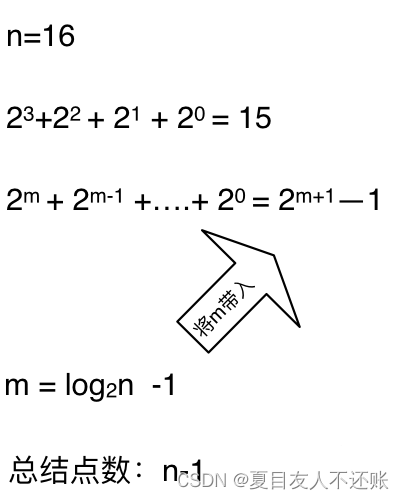
时间复杂度忽略掉常数项-1之后,这个递归算法的时间复杂度依然是O(n)
(4)(3)中的算法有重复计算的部分,优化后:
int function4(int x, int n) {
if (n == 0) return 1;
if (n == 1) return x;
int t = function4(x, n / 2);// 这里相对于function3,是把这个递归操作抽取出来
if (n % 2 == 1) {
return t * t * x;
}
return t * t;
}
依然还是看递归了多少次,可以看到这里仅仅有一个递归调用,且每次都是n/2 ,所以这里一共调用了log以2为底n的对数次。
每次递归了做都是一次乘法操作,这也是一个常数项的操作,那么这个递归算法的时间复杂度才是真正的O(logn)。
3 空间复杂度分析
**定义:**对一个算法在运行过程中占用内存空间大小的量度,记做S(n)=O(f(n)。
空间复杂度(Space Complexity)记作S(n) 依然使用大O来表示。利用程序的空间复杂度,可以对程序运行中需要多少内存有个预先估计。
例子:
空间复杂度是 O ( 1 ) O(1) O(1)的C++代码如下:
int j = 0;
for (int i = 0; i < n; i++) {
j++;
}
空间复杂度是 O ( n ) O(n) O(n)的C++代码如下:
int* a = new int(n);
for (int i = 0; i < n; i++) {
a[i] = i;
}
定义了一个数组出来,这个数组占用的大小为n,虽然有一个for循环,但没有再分配新的空间,因此,这段代码的空间复杂度主要看第一行即可,随着n的增大,开辟的内存大小呈线性增长,即 O(n)。
在递归的时候,会出现空间复杂度为logn的情况。
4 递归算法的性能分析
递归求斐波那契数列的性能分析
斐波那契数的递归写法:
int fibonacci(int i) {
if(i <= 0) return 0;
if(i == 1) return 1;
return fibonacci(i-1) + fibonacci(i-2);
}
时间复杂度分析:
一棵深度(按根节点深度为1)为k的二叉树最多可以有 2^k - 1 个节点。

递归的时间复杂度 = 递归次数*每次递归中的次数
每次递归的次数是3次,常数项,所以该递归算法的时间复杂度为O(2^n),这个复杂度是非常大的,随着n的增大,耗时是指数上升的。
其实罪魁祸首就是这里的两次递归,导致了时间复杂度以指数上升。
return fibonacci(i-1) + fibonacci(i-2);
优化一下这个递归算法,主要是减少递归的调用次数:
// 版本二
int fibonacci(int first, int second, int n) {
if (n <= 0) {
return 0;
}
if (n < 3) {
return 1;
}
else if (n == 3) {
return first + second;
}
else {
return fibonacci(second, first + second, n - 1);
}
}
这里相当于用first和second来记录当前相加的两个数值,此时就不用两次递归了。
因为每次递归的时候n减1,即只是递归了n次,所以时间复杂度是 O(n)。
同理递归的深度依然是n,每次递归所需的空间也是常数,所以空间复杂度依然是O(n)。
代码(版本二)的复杂度如下:
- 时间复杂度:O(n)
- 空间复杂度:O(n)
空间复杂度分析
(1) 递归调用函数时,通常会将一些数据结构和变量入栈,以便在递归调用完成后能够恢复之前的状态并继续执行。具体入栈的内容包括:
- 函数的返回地址:在进入递归函数时,当前函数的返回地址会被压入栈中,以便在递归调用完成后能够返回到之前的函数继续执行。
- 函数的参数:递归调用时,需要将新的参数值传递给递归函数。这些参数值也会被入栈保存。
- 局部变量:递归调用会创建新的函数栈帧,每个栈帧都有自己的局部变量。这些局部变量也会被入栈保存。
- 临时变量:递归调用中使用的一些临时变量也会被入栈保存,以便在递归调用完成后能够恢复之前的值。
(2) 递归算法的空间复杂度 = 每次递归的空间复杂度 * 递归深度
为什么要求递归的深度呢?
因为每次递归所需的空间都被压到调用栈里(这是内存管理里面的数据结构,和算法里的栈原理是一样的),一次递归结束,这个栈就是就是把本次递归的数据弹出去。所以这个栈最大的长度就是递归的深度。
int fibonacci(int i) {
if(i <= 0) return 0;
if(i == 1) return 1;
return fibonacci(i-1) + fibonacci(i-2);
}
此时可以分析这段递归的空间复杂度,从代码中可以看出每次递归所需要的空间大小都是一样的,所以每次递归中需要的空间是一个常量,并不会随着n的变化而变化,每次递归的空间复杂度就是 O ( 1 ) O(1) O(1)。
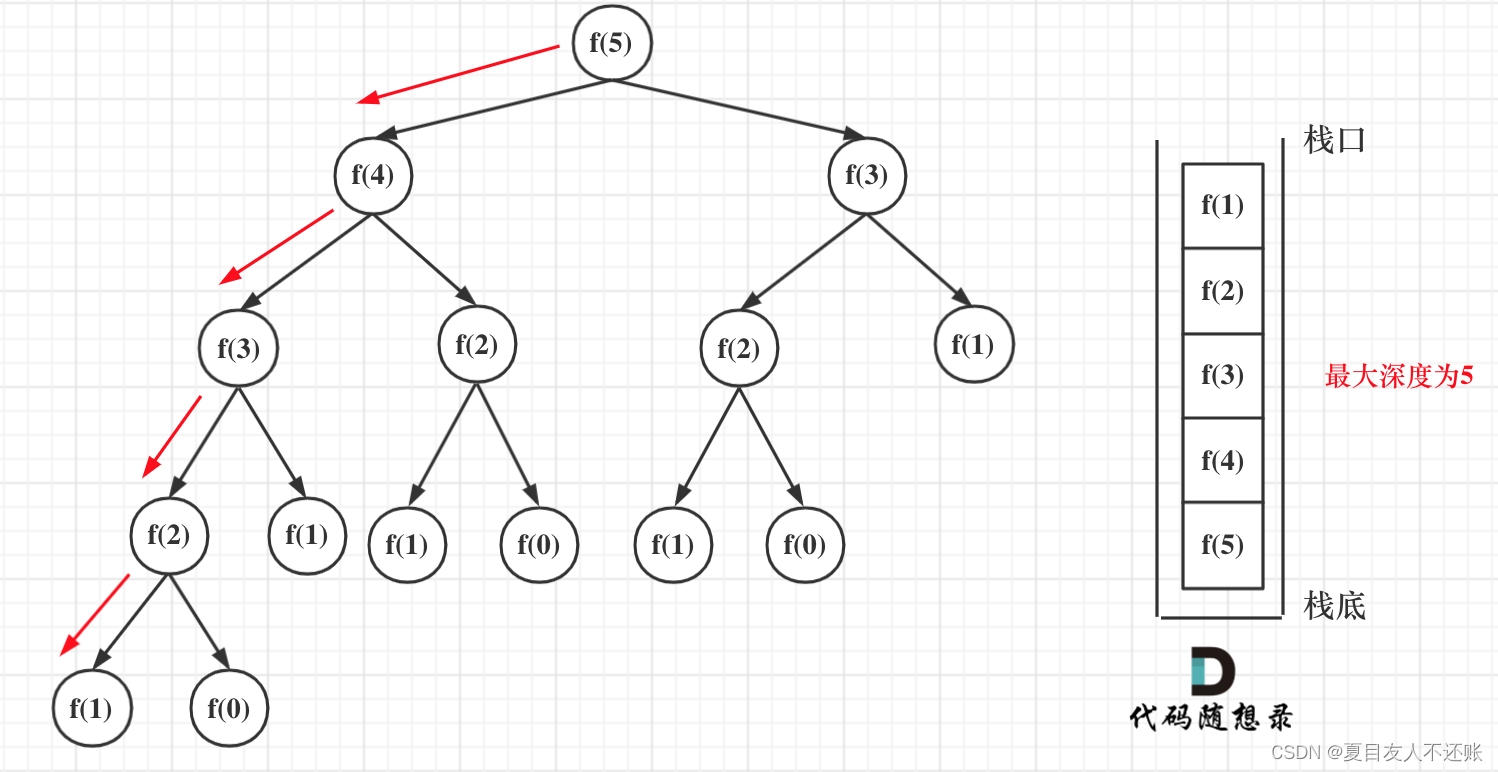
递归第n个斐波那契数的话,递归调用栈的深度就是n。
那么每次递归的空间复杂度是O(1), 调用栈深度为n,所以这段递归代码的空间复杂度就是O(n)。
二分法(递归实现)的性能分析
int binary_search( int arr[], int l, int r, int x) {
if (r >= l) {
int mid = l + (r - l) / 2;
if (arr[mid] == x)
return mid;
if (arr[mid] > x)
return binary_search(arr, l, mid - 1, x);
return binary_search(arr, mid + 1, r, x);
}
return -1;
}
依然看 每次递归的空间复杂度和递归的深度, 每次递归的空间复杂度可以看出主要就是参数里传入的这个arr数组,但需要注意的是在C/C++中函数传递数组参数,不是整个数组拷贝一份传入函数而是传入的数组首元素地址。
也就是说每一层递归都是公用一块数组地址空间的,所以 每次递归的空间复杂度是常数即:O(1)。
再来看递归的深度,二分查找的递归深度是logn ,递归深度就是调用栈的长度,那么这段代码的空间复杂度为 1 * logn = O(logn)。
要注意所用的语言在传递函数参数的时,是拷贝整个数值还是拷贝地址,如果是拷贝整个数值那么该二分法的空间复杂度就是O(nlogn)。
5 内存消耗
(1) 不同语言的内存管理
不同的编程语言各自的内存管理方式。
- C/C++这种内存堆空间的申请和释放完全靠自己管理
- Java 依赖JVM来做内存管理,不了解jvm内存管理的机制,很可能会因一些错误的代码写法而导致内存泄漏或内存溢出
- Python内存管理是由私有堆空间管理的,所有的python对象和数据结构都存储在私有堆空间中。程序员没有访问堆的权限,只有解释器才能操作。
(2) 内存对齐
不要以为只有C/C++才会有内存对齐,只要可以跨平台的编程语言都需要做内存对齐,Java、Python都是一样的。
而且这是面试中面试官非常喜欢问到的问题,就是:为什么会有内存对齐?
主要是两个原因
- 平台原因:不是所有的硬件平台都能访问任意内存地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。为了同一个程序可以在多平台运行,需要内存对齐。
理是由私有堆空间管理的,所有的python对象和数据结构都存储在私有堆空间中。程序员没有访问堆的权限,只有解释器才能操作。
(2) 内存对齐
不要以为只有C/C++才会有内存对齐,只要可以跨平台的编程语言都需要做内存对齐,Java、Python都是一样的。
而且这是面试中面试官非常喜欢问到的问题,就是:为什么会有内存对齐?
主要是两个原因
- 平台原因:不是所有的硬件平台都能访问任意内存地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。为了同一个程序可以在多平台运行,需要内存对齐。
- 硬件原因:经过内存对齐后,CPU访问内存的速度大大提升。















 5452
5452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









