






本文根据B站UP“我是土堆”视频教程整理,视频链接如下:
https://www.bilibili.com/video/BV1S5411X7FY?p=26&vd_source=5a88e37d241fe49a63a0ca57f11ba8d2
问题:
在使用yolov5进行目标识别的时候,只能使用CPU,网上查的到的方法是将device由默认改为自己电脑显卡的编号,我电脑显卡编号为1(显卡编号在“任务管理器-性能”中查看),改为如下:
parser.add_argument('--device', default='1', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
但我修改后运行,仍报错,如下:
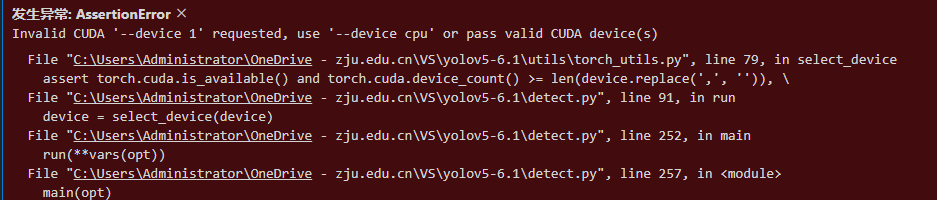
问题原因:未安装pytorch GPU运行环境。
解决方法:重新安装pytorch GPU运行环境。
具体步骤:
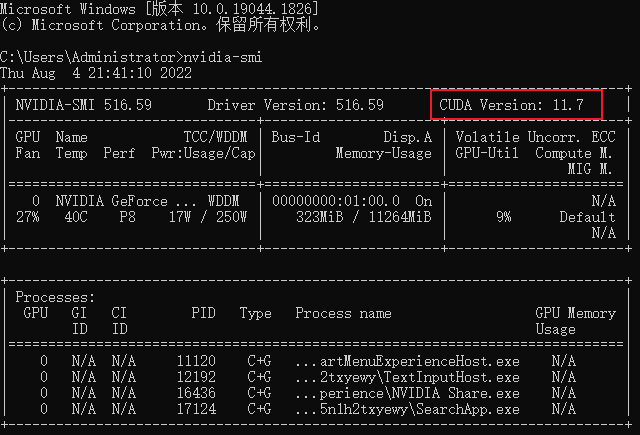
1、先确定Cuda版本。
打开cmd窗口,输入:
nvidia-smi
即可查看Cuda版本,如下图所示:
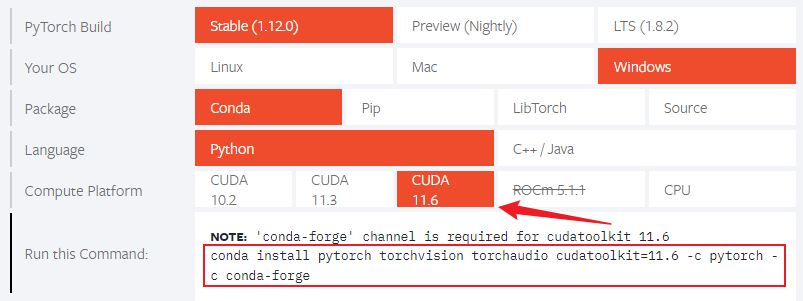
2、打开Pytorch官网,选择低于Cuda版本的最高版本11.6,弹出了conda安装命令,选中conda按照命令并复制,如下图所示:
3、打开anaconda,激活需要安装pytorch的环境:
conda activate yolov5 #将yolov5替换为你创建的虚拟环境名称
4、激活需要安装pytorch的环境后,粘贴conda安装命令,先不回车,将后面的下载通道改为国内镜像,如下代码所示,否则安装时下载会很慢。
使用清华镜像安装cudatoolkit
conda install cudatoolkit=11.6 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
使用清华镜像安装pytorch torchvision torchaudio
conda install pytorch torchvision torchaudio -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/
附:
安装pytorch、torchvision、torchaudio可以选择如下镜像地址:
清华镜像
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/
北京外国语大学镜像
https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/win-64/
阿里巴巴镜像
http://mirrors.aliyun.com/anaconda/cloud/pytorch/win-64/
南京大学镜像
https://mirror.nju.edu.cn/pub/anaconda/cloud/pytorch/win-64/
安装cudatoolkit可以选择如下镜像地址:
清华镜像
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
北京外国语大学镜像
https://mirrors.bfsu.edu.cn/anaconda/pkgs/main
阿里巴巴镜像
http://mirrors.aliyun.com/anaconda/pkgs/main
5、安装完成后,将device由默认改为自己电脑显卡的编号,如下代码所示,再次运行yolo测试程序。
parser.add_argument('--device', default='1', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
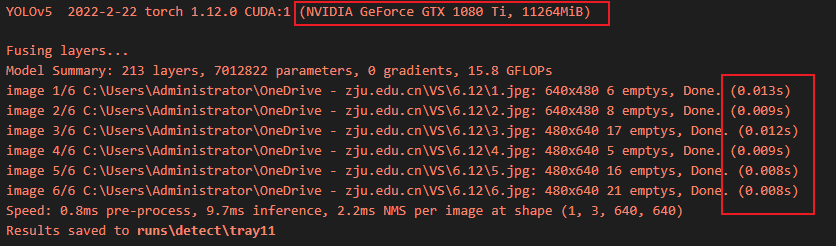
速度对比:
使用CPU
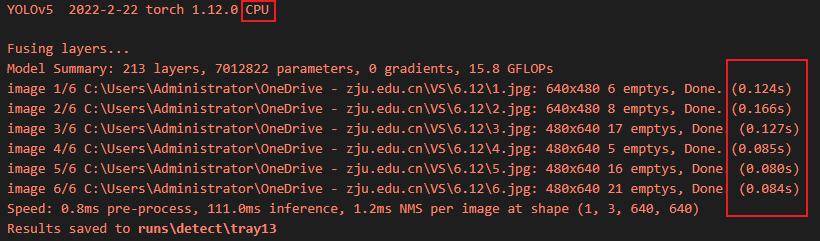
使用GPU

















 8996
8996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









