







《Evaluating the Disentanglement of Deep Generative Models through Manifold Topology》阅读笔记
1 动机
解耦工作对于模型的泛化、鲁棒性和可解释性来说至关重要,然而由于现有的解耦评测方法通常依赖于训练额外的、新的生成模型(分类器、编码器、回归器等)或在特定数据集以及使用特定方法预处理过的数据集上进行验证,因此评价结果的可靠性较差,且往往与任务较为相关,适用范围有限,也导致了用不同指标评测解耦模型时会出现多种排名结果。
2 方法
本文所提出的评价方法基于拓扑学原理,理论上较为抽象,在实现上,测量每个潜在维度( z i z_i zi)上的条件子流形的持续同调(TDA, https://zhuanlan.zhihu.com/p/31734839),然后,本文的评价核心思想即在于,以解耦因子为条件的潜在子流形之间具有比以纠缠因子为条件的潜在子流形之间具有更高的拓扑相似度。因此,采用W.RLT距离去度量这个拓扑相似性。
本文所采用的从数据样本空间估计拓扑空间同调的方法是相对存在时间(Relative Living Times,RLTs),为了获取RLTs,如下图所示,首先假定训练好的生成模型分布 p m o d e l ( x ) p_{model}(x) pmodel(x)由一个带孔的流形 M m o d e l M_{model} Mmodel支撑,从 p m o d e l ( x ) p_{model}(x) pmodel(x)中采样出样本点集合 X X X,从而得到一个基础的单纯形复合物,改变每个样本点的阈值(即图(d)中每个点的半径)用欧氏距离度量点与点之间的临近测度,在逐渐增大阈值时,会产生不同数量的k维孔(拓扑学中度量同调的重要依据),最终实现对持久性同调的逼近,得到持久性条形码(连续同调评价的产物)。
RLTs则是在改变阈值以生成的多个持久性条形码的矢量化,反映了每个k维孔出现和小时的持续时间内的离散分布,对RLTs取均值,则可以得到这些k维孔的平均相对生成时间,为一个离散概率分布,测量两个数据样本集之间的平均相对生成时间分布的相似性,就可以作为两个样本集之间拓扑相似性的评价依据。
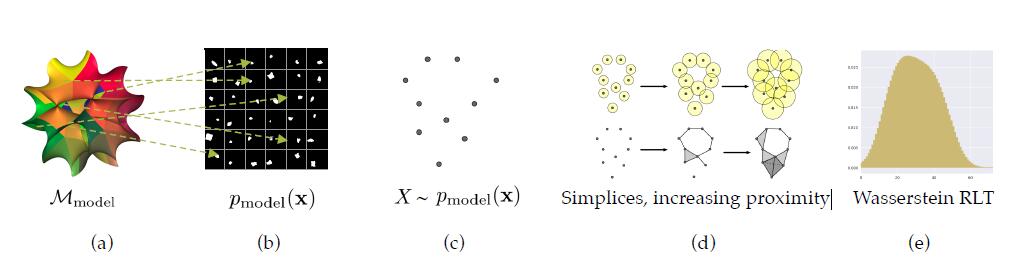
为了说明其理论的有效性,作者可视化了解耦和非解耦的生成模型在dsprites数据集上的拓扑结构:

可以发现,解耦模型在尺寸和转角两个因子下的子流形明显不同胚,转角子流形有一维孔,旋转则没有,而每个因子内部的各个子流形是同胚的,而不解耦模型则没有这个性质。
传统的基于RLTs的拓扑相似性度量使用欧氏距离,但是经验上发现使用Wasserstein距离能显著改善度量精度。因此,作者基于W重心提出W.RLTs度量方法:
度量思想:
前面已经提到,采样后得到的RLTs代表k维空穴存在与否的离散分布,首先求出这个离散分布的重心 :分布重心定义为“使用W-2距离计算到达分布中所有点的最小总距离所在的位置”,计算公式如下:
:分布重心定义为“使用W-2距离计算到达分布中所有点的最小总距离所在的位置”,计算公式如下:
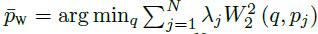
上面的 λ λ λ是一个权重参数,其和为1。
在求出RLTs的重心之后,从两个角度评价其解耦性能的好坏:
1、 同一个因子内部的条件子流形应该有较高的拓扑相似性;
2、 不同因子的条件子流形具有较低的拓扑相似性。
因此,在某一因子 s i s_i si为条件下生成的条件子流形下,控制因子 s i s_i si的值不变,而其他因子的值可以变化,得到一个同一因子下的集群,测量这一集群内的拓扑相似性作为这一因子下的条件子流形的拓扑相似性结果;同时,测量不同因子作为条件的子流形之间的拓扑相似性,作为因子间拓扑相似性结果。作者在CelabA数据集上可视化了W.RLTs结果来说明这一思想,下图中的第一行是同一个因子内部的连续同调W.RLTs,下一行是不同因子之间的W.RLTs:
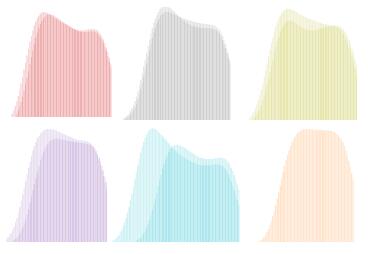
无监督评价方法
在评价时,由于实际的因子 s i s_i si与实验设置的因子 z j z_j zj之间可能并不存咋一一对应的连结,因此,本文使用W距离计算每个因子 z j z_j zj为条件的子流形的拓扑相似性,也就是使用W距离计算不同条件子流形之间的分布重心的距离,得到一个 j ∗ j j*j j∗j维的拓扑相似性矩阵 M M M,在得到拓扑相似性矩阵之后,使用奇异值分解进行频谱共聚类,其目的在于合并同态的以设置因子 z z z为条件的子流形,使得 z z z可以与实际因子 s s s相对应,即合并解耦作用相似的因子,降维。由此得到最终的 c ∗ c c*c c∗c维的共聚类相似性矩阵 M c M_c Mc。作者可视化了不同模型在不同数据集下的共聚类相似性矩阵(颜色越深,代表相似性越强,对角线即上即为同一条件子流形的同态相似性可视化结果):

之后,最小化共聚类相似性矩阵 M c M_c Mc的聚类内方差和聚类间方差,去求得最终的聚类数量c,使用共聚类相似性矩阵 M c M_c Mc,计算解耦得分 μ μ μ。解耦得分定义为聚类内相似性和聚类间相似性之差:
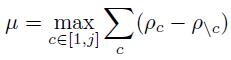
因此,一个解耦效果较好的模型,想要获得较高的解耦得分,则希望有尽量大的聚类内相似性,同时聚类间的相似性尽量小,类间相似性非常直观,就是 M c M_c Mc对角元上的值,因此:
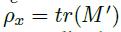
同样的,类间相似性就是 M c M_c Mc剔除对角元元素之外的值:
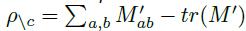
这就是无监督方法的聚类解耦评估方法。
有监督评价方法
与上面的无监督方法相比,有监督方法的改动在于不再比较不同给定因子 z j z_j zj,之间的拓扑相似性,而是对于有标签的数据集,同时计算实际因子 s i s_i si的W.RLTs,因此,在评价时,只计算 z j z_j zj与 s i s_i si之间的拓扑相似性,得到 j ∗ i j*i j∗i维的矩阵 M M M,同样进行奇异值分解(具体怎么做没有再说明),因此类间相似性和类内相似性的计算如下:

与无监督指标不同的地方在于,有监督指标对计算结果进行了归一化处理:
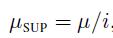
方法的限制
本评价方法假定数据流形是不完全对称的,因此没有考虑对称流形的情况,同时,RLTs不能计算数据流形的完整拓扑,而是进行逼近。
3 实验
作者将本文提出的方法与MIG,一个使用一个分类器的方法Disentanglement和一个专门对人脸数据库解耦表现做评估的PPL方法进行比较,对不同解耦模型做排名,得到与其他指标相似的排名结果:

大部分指标排名都比较相似,然而对于β-VAE,本文方法的指标与MIG相比差异较大,但是两种指标评价β-VAE时都有较大的方差,因此说明β-VAE的表现可能不是很稳定。同时还发现了两种训练目标比较相似的模型可能在解耦表现上有较大差异(Factor VAE和β-VAE)。
同时报告了定量结果:

作者指出,大部分情况下,无监督评估指标更为适用,尤其对于CelebA,由于脸部信息过多,不易于用有监督方法进行评价,而如果想评估特定的解耦(发色,眼镜),用有监督的方法会更合适。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









