







四篇图像解耦工作简要介绍
1 Variational Interaction Information Maximization for Cross-domain Disentanglement
这篇文章的思想是使用信息论知识,实现跨域图像解耦表示,是基于VAE的一个改进工作。
对于图像对x,y,二者之间既有共享的表征信息,也有不共享的表征信息,这篇文章提了如下图所示的架构,训练一个VAE,同时学到X的特定表征,Y的特定表征以及X与Y之间的共享表征,这一目的通过最大化X与Y的联合分布之间的边际似然函数实现:
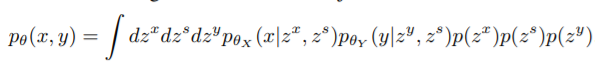
在实际应用中直接优化上述公式有些困难,作者还做了其他的简化表达,经过改进后,其损失函数的思想在于,希望每个数据之前特异的特征被编码到各自单独的编码器 Z x , Z y Z_x,Z_y Zx,Zy之中,而二者之间相互共享的表征则被同一个编码器所 Z s Z_s Zs编码,为了实现这一目的(三类表征之间尽量分开),作者引入了互信息思想,希望尽可能最小化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









