







使用交叉熵求loss来优化多分类问题
Network Architecture
输出是10层,代表着10分类。
因为还没有学习线性层知识,所以采用一些底层操作来代替。
新建三个线性层,每个线性层都有w和btensor
注意在pytorch中,第一个维度是out,第二个维度才是in
w1,b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
w2,b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
w3,b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)
第一个线性层可以理解为把784(28×28)降维成200。我们必须指定requires_grad为true,否则会报错。
第二个隐藏层从200到200,就是一个feature转变的过程,没有降维。
第三个输出层,最后输出10个类。
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
最后一层也可以不使用relu,不能使用sigmod或者softmax,因为后面还会使用softmax
这个就是网络tensor和forward过程,
Train
接下来定义一个优化器,优化的目标是3组全连接层的变量[w1,b1,w2,b2,w3,b3]
optimizer=optim.SGD([w1,b1,w2,b2,w3,b3],lr=learning_rate)
criteon=nn.CrossEntropyLoss()
crossEntropyLoss和F.crossEntropyLoss功能一样,都是softmax+log+nll_loss
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data=data.view(-1,28*28)
logits=forward(data)
loss=criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train epoch:{}[{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch,batch_idx*len(data),len(train_loader.dataset),
100.*batch_idx/len(train_loader),loss.item()))
step是指一个batch,而eopch是整个数据集。
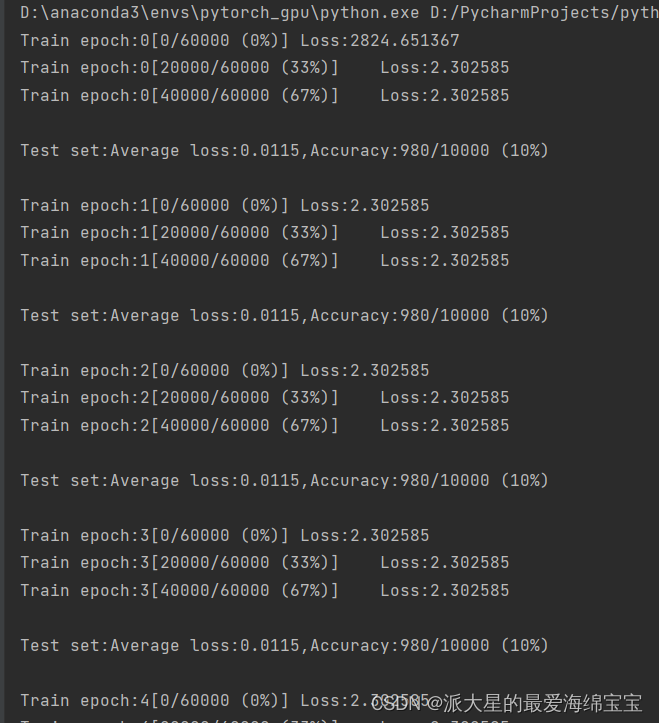
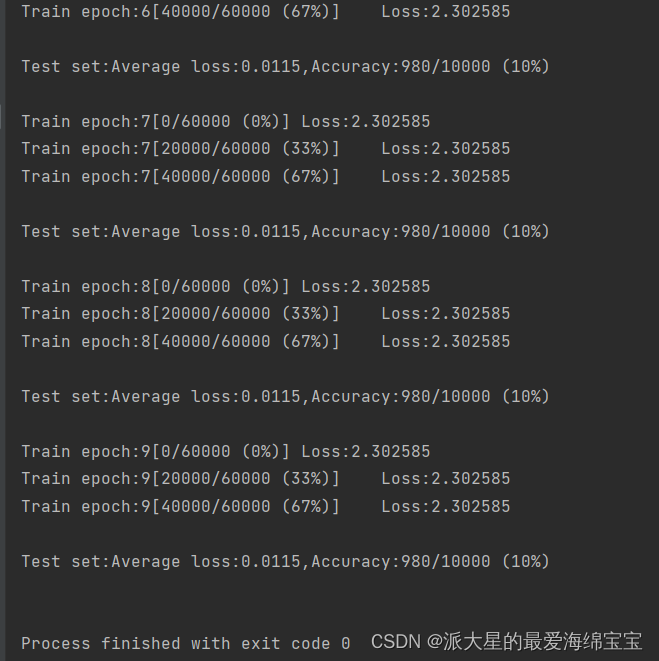
loss保持10%不变,是因为初始化问题
当我们对w1,w2,w3初始化后,b是直接torch.zeros初始化过了。
torch.nn.init.kaiming_normal(w1)
torch.nn.init.kaiming_normal(w2)
torch.nn.init.kaiming_normal(w3)
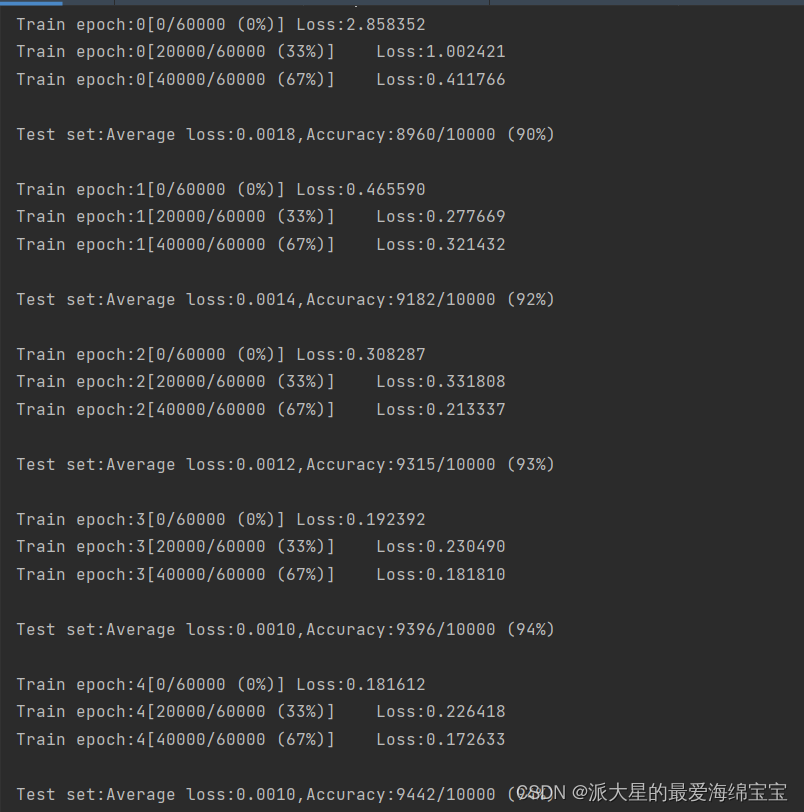
完整代码
import torch
import torch.nn.functional as F
from torch import optim
from torch import nn
import torchvision
batch_size = 200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 把numpy格式转换成tensor
# 正则化,在0附近,可提升性能
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
w1,b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
w2,b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
w3,b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)
torch.nn.init.kaiming_normal(w1)
torch.nn.init.kaiming_normal(w2)
torch.nn.init.kaiming_normal(w3)
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
optimizer=optim.SGD([w1,b1,w2,b2,w3,b3],lr=learning_rate)
criteon=nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data=data.view(-1,28*28)
logits=forward(data)
loss=criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train epoch:{}[{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch,batch_idx*len(data),len(train_loader.dataset),
100.*batch_idx/len(train_loader),loss.item()))
test_loss=0
correct=0
for data,target in test_loader:
data=data.view(-1,28*28)
logits=forward(data)
test_loss+=criteon(logits,target).item()
pred =logits.data.max(1)[1]
correct+=pred.eq(target.data).sum()
test_loss/=len(test_loader.dataset)
print('\nTest set:Average loss:{:.4f},Accuracy:{}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))















 7235
7235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









