







2. 我们用的tensorflow mobile netv2官方的预训练模型
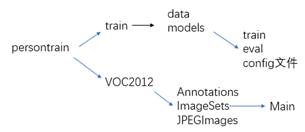
3. 准备预训练模型和数据集
首先要知道文件夹的目录格式
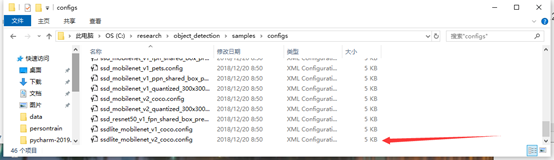
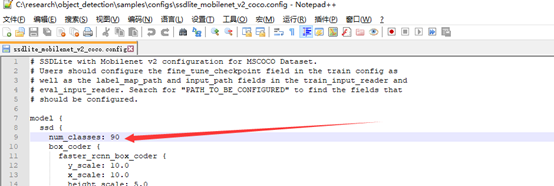
打开后看到的是下面的东西,要改的东西都已经标注了

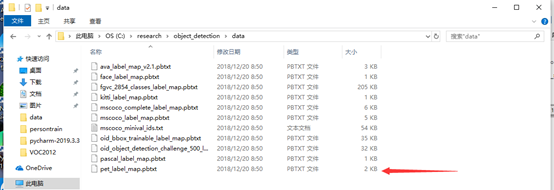
然后还要一个pbtxt

4. 接下来教你怎么改数据集,
我之前说的VOC2012里面的文件包含什么,Annotations是我们打的标签,JPEGImages是我们的图片,ImageSets里面的Main文件夹里面包含

就是我们对我们图片的名字打包放到这里
Annotations的xml文件要求的格式是

这里自己体会吧,folder必须是voc2012,path里面的图片位置必须要在VOC2012的JPEGImages,网上有很多该路径的方法,但是他们并没有先删除我们之前的path路径,而是直接怼上去(看下方),

我也没找到方法,然后我想到了一个最笨的方法,把图片和xml文件分别放到指定的文件夹,然后用labelImg去打开我们之前打好的标签,打开后,我们对之前的标签稍微移动一下,然后保存,这样path就会变成你想要的路径了,但是弄完这个步骤,会出现下方的问题

这个问题,好解决,我们只需要替代他就行了(我提醒一下,如果原来图片是1080p的,最好缩小一下,不然可能会报一些你不明白的错)
然后我们生产txt文件,我这边有脚本生成(我会将脚本打包,有需要的可以下载,也可私信我)
5. VOC2012文件夹的东西弄完之后,我们生成record

python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=I:/persontrain/train/data/label_map.pbtxt --data_dir=I:/persontrain --year=VOC2012 --set=train --output_path=I:/persontrain/pascal_train.record
生成val的话,把train换成val就行了,然后把这两个文件放到data下面与pbtxt同目录,
6. 然后改config文件,把刚才我指出要改的路径加上去,record就是我们刚才生成的路径,至此,我们改的东西就差不多了
7. 开始训练东西(cmd的路径,都是research下面),我们用legacy下的train文件
8. 我们只需要传入3个3个数据
python object_detection/legacy/train.py --pipeline_config_path=I:\persontrain\train\models\ssd_mobilenet_v2_coco.config --train_dir=I:\persontrain\train\models\train --logtosderr

点回车,开始训练

















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











