







主要解决的问题
如何得到更有用的特征?
模型自动学习,dnn;人工设计,用户侧特征和item侧特征
答:利用GBDT自动进行特征交叉
使用场景
最广泛的场景是CTR点击率预估,即预测当给用户推送的广告会不会被用户点击。
推荐系统全流程
离线部分目标主要是训练出可用模型,而在线部分则考虑模型上线后,性能可能随时间而出现下降,弱出现这种情况,可选择使用Online-Learning来在线更新模
离线部分
- 数据收集:主要收集和业务相关的数据,通常会有专门的同事在app位置进行埋点,拿到业务数据
- 预处理:对埋点拿到的业务数据进行去脏去重;
- 构造数据集:经过预处理的业务数据,构造数据集,在切分训练、测试、验证集时应该合理根据业务逻辑来进行切分;
- 特征工程:对原始数据进行基本的特征处理,包括去除相关性大的特征,离散变量one-hot,连续特征离散化等等;
- 模型选择:选择合理的机器学习模型来完成相应工作
- 超参选择
- 在线A/B Test:选择优化过后的模型和原先模型(如baseline)进行A/B Test,若性能有提升则替换原先模型;
在线部分
- Cache & Logic:设定简单过滤规则,过滤异常数据;
- 模型更新:当收集到合适大小数据时,对模型进行pretrain+finetuning,若在测试集上比原始模型性能高,则更新model server的模型参数;
- Model Server:接受数据请求,返回预测结果;
GBDT+LR原理
1. 对原始训练数据做训练,得到一个二分类器,GBDT的输出为这些弱分类器的组合[0 1 0 0 1] ,或者一个稀疏向量(数组)。所以在一个具有n个弱分类器、共计m个叶子结点的GBDT中,每一条训练数据都会被转换为1*m维稀疏向量,且有n个元素为1,其余m-n 个元素全为0
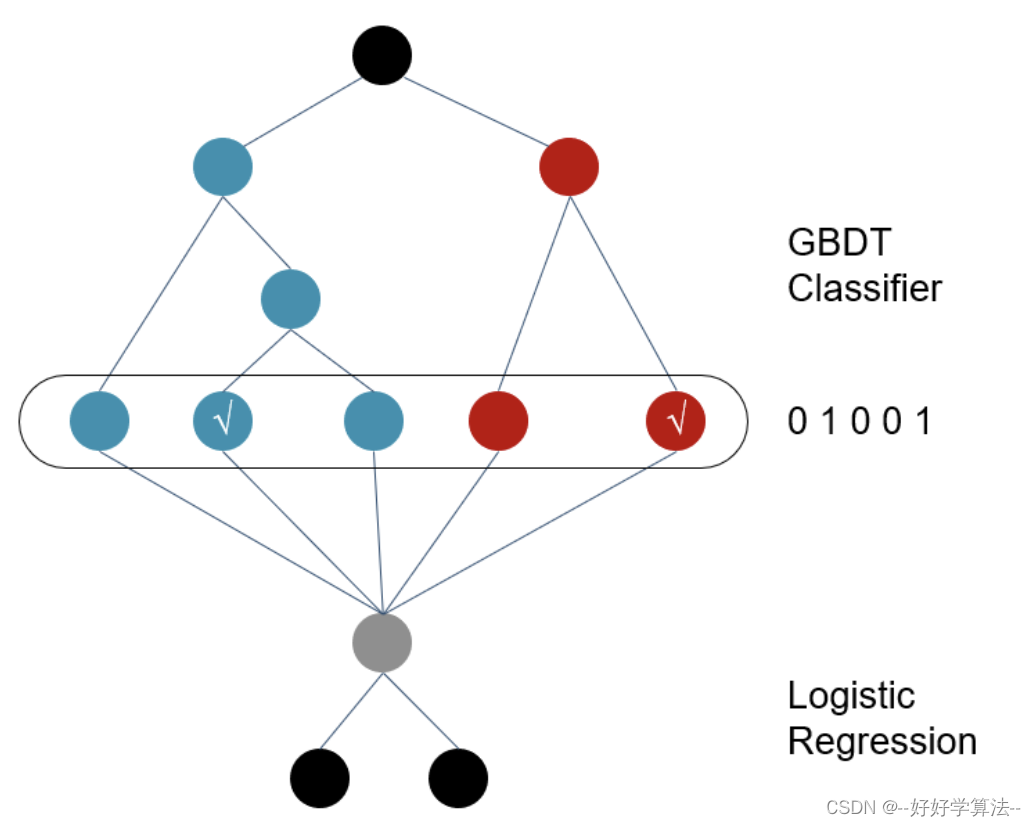
类似one-hot的向量形式
特征交叉
树的高度为k,则进行了k次节点的分裂,因此,最终的叶子节点实际上是进行了k阶特征交叉
2. LR:GBDT输出的数据稀疏,而且由于弱分类器个数,叶子结点个数的影响,可能会导致新的训练数据特征维度过大,因此,在Logistic Regression这一层中,可使用正则化来减少过拟合的风险,在Facebook的论文中采用的是L1正则化。
模型评价指标
1.Normalized Entropy
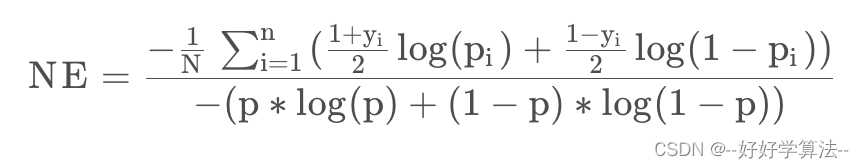
yi为样本的真实label,pi 为预估的CTR,p为训练集上的真实平均CTR。
2.Calibration
Calibration=预估CTR/真实CTR,COPC的倒数,COPC=真实CTR/预估CTR
学习率
Per-Coordinate Learning Rates
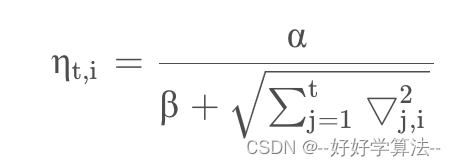
当一个特征出现的次数较多时,说明此时这个特征参数训练的已经比较充分了,因此学习率可以比较低一点;但当一个特征出现的次数较少时,说明此时训练的还不够充分,所以需要较大的学习率来尽快的收敛。
优点:使得那些低频长尾特征也能学到一个比较好的参数。
经验之谈:除以每个特征的曝光次数的开方也可以提升auc
why GBDT not XGB?
GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理。
代码实现
https://www.cnblogs.com/wkang/p/9657032.html
相关问题
1.使用GBDT进行特征组合,会导致模型周期拉长,导致模型更新不及时,效果变差该如何解决?
答:
- GBDT部分天级别甚至几天更新一次
- LR部分的参数online learning 实时的更新
2.样本采样
负采样,是做了负采样之后会导致样本分布发生变化,尤其是CTR发生变化,因此需要进行CTR校准还原
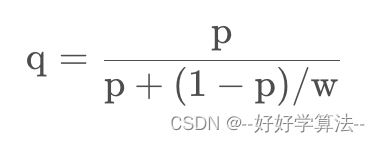
p为在采样后的pctr,w为负采样采样率,q为校准后的CTR。
补充:GBDT模型原理
加法模型:每轮迭代会产生一个弱分类器, 每个分类器在上一轮分类器的残差基础上进行训练,每轮的训练是在上一轮的训练的残差基础之上进行训练的
损失函数:回归问题中一般使用的是平方损失, 而二分类问题中使用交叉熵损失
例子:假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁;我们去你和损失,拟合的数值为6岁,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。
上一步的残差是下一步的解决目标。
GBDT既可以用于分类模型,也可以用于回归模型。在分类模型中,GBDT通过训练多个决策树来预测样本的类别,每个决策树的输出是概率值或者类别标签。在回归模型中,GBDT通过训练多个决策树来预测目标变量的值,每个决策树的输出是一个实数值。















 3888
3888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









