







代码:https://github.com/naver-ai/pit.
1.CNN的维度设置
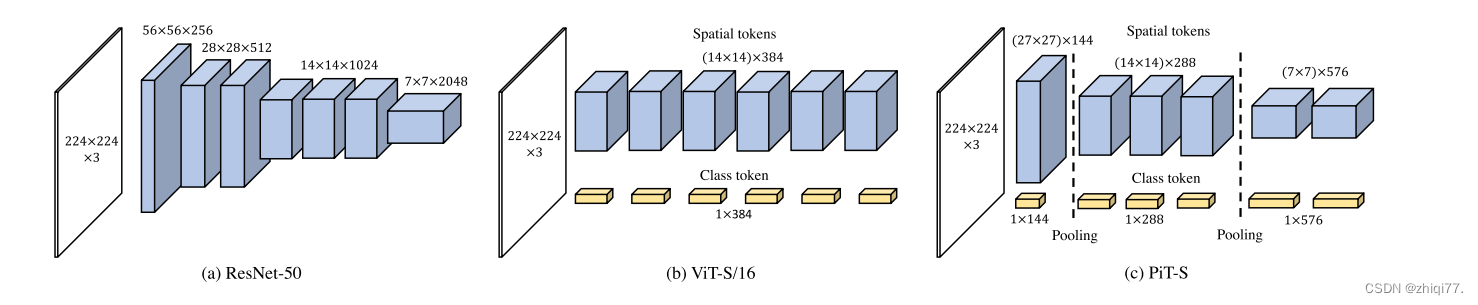
网络维度配置的示意图。我们可视化ResNet 50 ,Vision Transformer(ViT)和我们基于池化的Vision Transformer(PiT);(a)ResNet 50从输入到输出逐渐下采样特征;(B)ViT不改变空间维度;(c)PiT将ResNet风格的空间维度引入ViT。
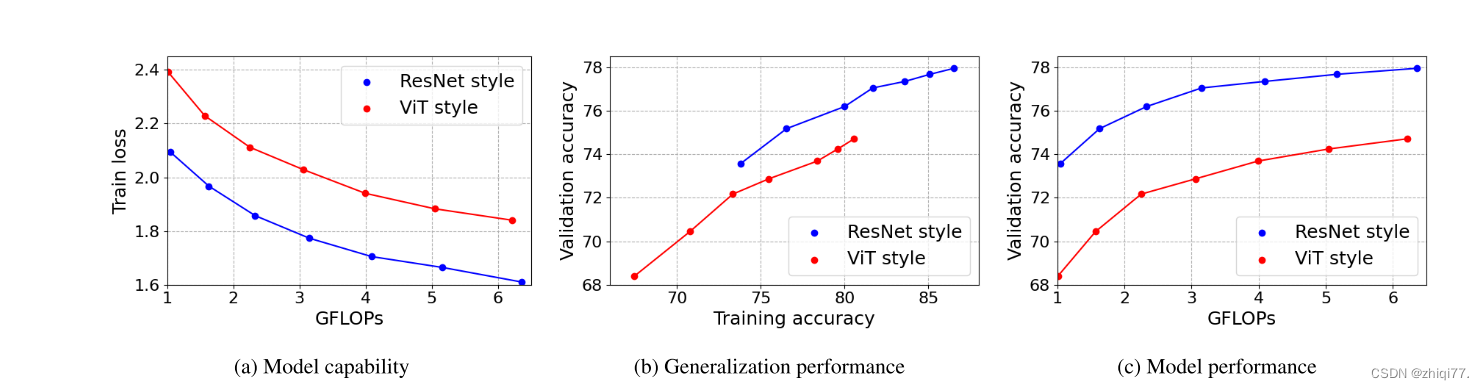
ResNet风格的维度提高了架构的模型能力和泛化性能,从而显著提高了验证准确性。
2.基于池化的视觉Transformer(PiT)
ViT在第一个嵌入层将图像按块划分,并将其嵌入到令牌中。基本上,该结构不包括空间缩减层,并且在网络的整个层中保持相同数量的空间令牌。虽然自注意操作不受空间距离的限制,但参与注意的空间区域的大小受特征的空间大小的影响。因此,为了像ResNet一样调整维度配置,在ViT中还需要空间缩减层。
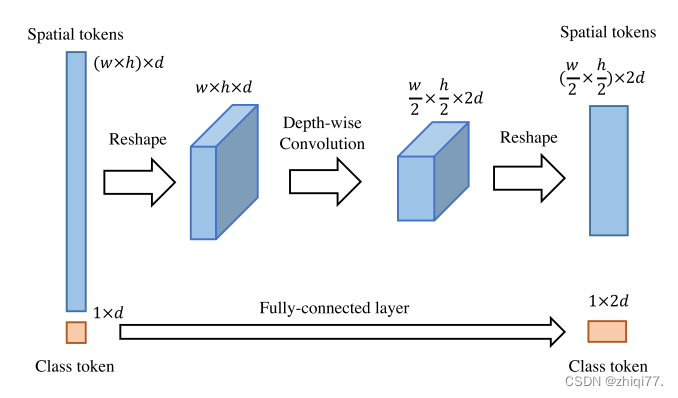
为了利用维配置的优势,我们提出了一个新的架构称为基于池的视觉Transformer(PiT)。首先,我们为ViT设计了一个池化层。我们的池化层如图3所示。由于ViT以2D矩阵而不是3D张量的形式处理神经元响应,因此池化层应该分离空间令牌并将它们重塑为具有空间结构的3D张量。在整形之后,通过深度卷积来执行空间大小减小和通道增加。并且,响应被重新塑造成用于计算Transformer块的2D矩阵。在ViT中,有一些部分不对应于空间结构,例如类令牌或蒸馏令牌。对于这些部分,池化层使用附加的全连接层来调整通道大小以匹配空间令牌。我们的池化层实现了ViT上的空间缩减,并用于我们的PiT架构,如图1(c)所示。PiT包括两个池化层,其形成三个空间尺度。
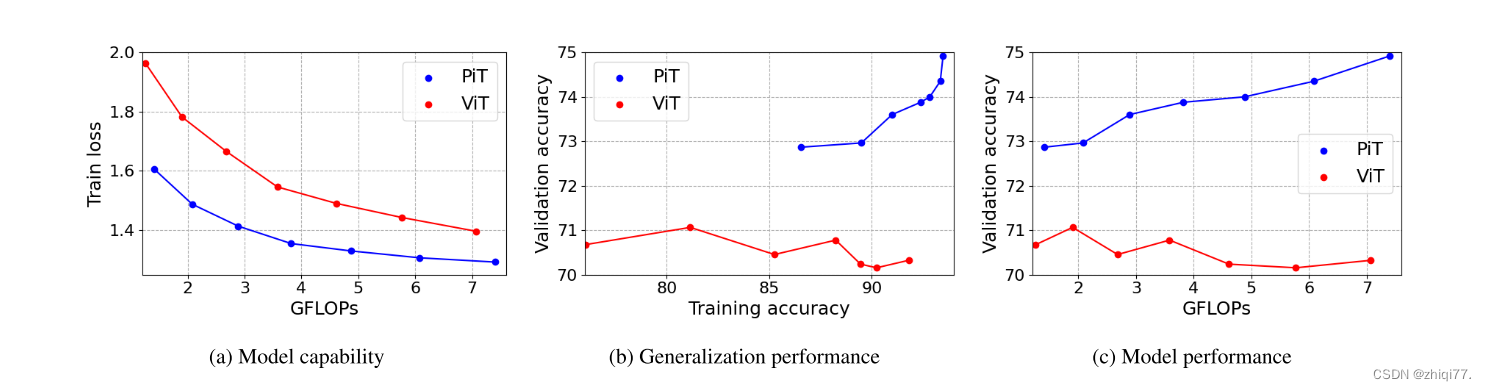
PiT在能力、泛化性能和模型性能方面优于ViT
使用PiT架构,我们进行了实验以验证PiT与ViT相比的效果。实验设置与ResNet实验相同。图4(a)表示ViT和PiT的模型能力。在相同的计算成本下,PiT比ViT具有更低的列车损失。在ViT中使用空间缩减层也提高了体系结构的性能。训练精度和验证精度之间的比较显示出显著差异。如图4(B)所示,即使训练精度提高,ViT也不会提高验证精度。另一方面,在PiT的情况下,验证精度随着训练精度的增加而增加。泛化性能的巨大差异导致PiT和ViT之间的性能差异,如图4(c)所示。ViT论文[9]中报道了ViT即使在ImageNet中FLOP增加时也不会提高性能的现象。在ImageNet规模的训练数据中,ViT表现出较差的泛化性能,PiT缓解了这一点。因此,我们认为空间归约层也是必要的推广ViT。使用训练技巧是提高ImageNet中ViT泛化性能的一种方法。训练技巧和PiT的结合在实验部分。
3.注意力分析
我们用注意力矩阵上的度量分析Transformer网络。记αi,j为注意矩阵A ∈ RM×N的(i,j)分量。注意,使用软最大层之后的注意值,即αi,j = 1。。注意熵定义为
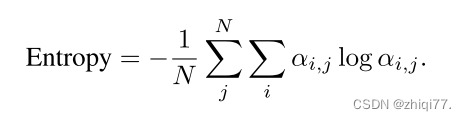
熵表示注意交互的扩散和集中程度。小熵指示集中的相互作用,大熵指示扩散的相互作用。我们还测量了注意力距离
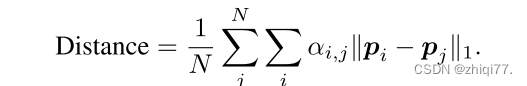
pi表示特征图F ∈ RH×W×C的第i个标记(xi/W,yi/H)的相对空间位置。因此,注意距离示出了与整体特征尺寸相比的相对比率,这使得能够在不同尺寸的特征之间进行比较。我们分析了基于变换器的模型(ViT-S 和PiT-S),并且测量了整体验证图像的值,并对每层的所有头部进行平均。我们的分析仅针对空间标记进行,而不是遵循先前研究的类标记。我们还跳过最后一个Transformer块的注意,因为最后一个注意的空间令牌独立于网络输出。
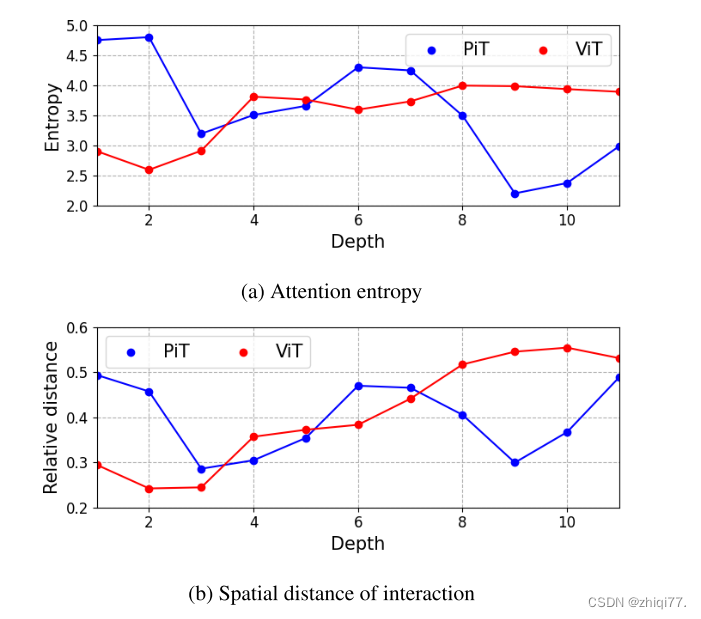
PiT将使用空间尺寸设置更改图案。在浅层(1-2层),大的空间尺寸增加了熵和距离。另一方面,由于空间尺寸小,熵和距离在深层(9-11层)处减小。简而言之,PiT的池化层将相互作用分散在浅层,并将相互作用集中在深层。与语言域的离散字输入相反,视觉域使用图像块输入,其需要预处理操作,诸如滤波、对比度和亮度校准。在浅层,PiT的扩散相互作用比ViT的集中相互作用更接近于预处理。此外,与语言模型相比,图像识别具有相对低的输出复杂度。因此,在深层,集中的相互作用可能就足够了。视觉和语言领域存在显著差异,我们认为PiT的注意力适合作为图像识别的骨干。
4.建筑设计
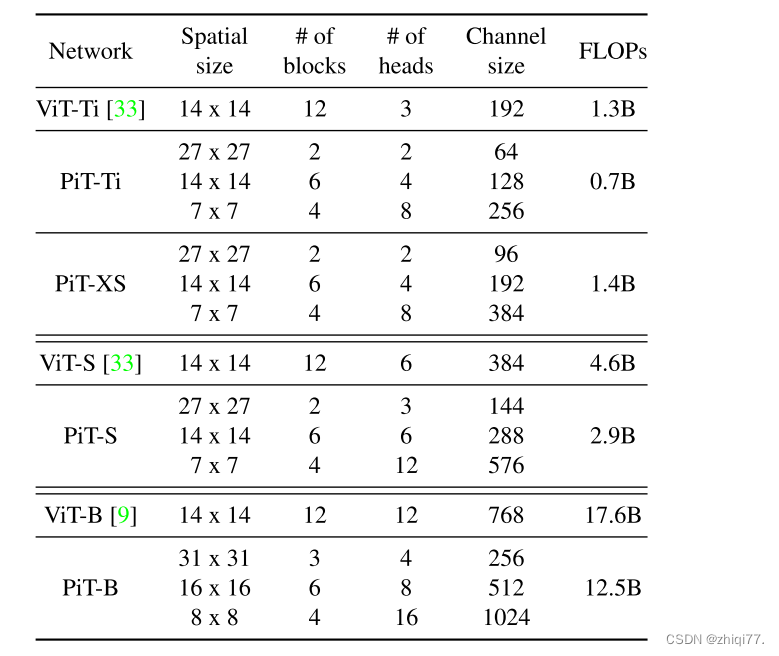
详细架构如表1所示。为方便起见,我们将模型名称缩写为:基于224×224图像测量Tiny-Ti、eXtra Small-XS、Small-S、Base-B FLOP和空间大小。由于PiT使用比ViT更大的空间大小,我们将嵌入层的步幅大小减小到8,而作为ViT的补丁大小为16。两个池化层用于PiT,并且信道增加被实现为增加多头注意力的头的数量。我们将PiT设计为具有与ViT相似的深度,并调整通道和磁头以具有比ViT更小的FLOP、参数大小和GPU延迟。
5.结论
在本文中,我们已经证明了CNN中广泛使用的设计原理-通过池化或卷积进行的空间维度变换,在基于变换器的架构(如ViT)中没有考虑;最终影响模型性能。我们首先使用ResNet进行了研究,发现在空间维度方面的变换提高了计算效率和泛化能力。为了利用ViT的好处,我们提出了一个PiT,它将池化层整合到Vit中,PiT表明,通过广泛的实验,这些优势可以很好地协调到ViT。因此,虽然显着提高了性能的ViT架构,我们已经表明,通过考虑空间的相互作用比池层是必不可少的一个自我注意力为基础的架构。
6.代码
class PoolingTransformer(nn.Module):
def __init__(self, image_size, patch_size, stride, base_dims, depth, heads,
mlp_ratio, num_classes=1000, in_chans=3,
attn_drop_rate=.0, drop_rate=.0, drop_path_rate=.0):
self.transformers = nn.ModuleList([])
self.pools = nn.ModuleList([])
for stage in range(len(depth)):
drop_path_prob = [drop_path_rate * i / total_block
for i in range(block_idx, block_idx + depth[stage])]
block_idx += depth[stage]
#因为维度变了嘛,所以需要创建新的tranformer,用的是timm包的实现
#每个子transformer模块有不同的depth,也就是过多个block
self.transformers.append(
Transformer(base_dims[stage], depth[stage], heads[stage],
mlp_ratio,
drop_rate, attn_drop_rate, drop_path_prob)
)
if stage < len(heads) - 1:
#创建符合现在维度的pooling层
self.pools.append(
conv_head_pooling(base_dims[stage] * heads[stage],
base_dims[stage + 1] * heads[stage + 1],
stride=2
)
)
def forward_features(self, x):
x = self.patch_embed(x)
pos_embed = self.pos_embed
x = self.pos_drop(x + pos_embed)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)
for stage in range(len(self.pools)):
x, cls_tokens = self.transformers[stage](x, cls_tokens)
#过几个block,加一个pooling
x, cls_tokens = self.pools[stage](x, cls_tokens)
x, cls_tokens = self.transformers[-1](x, cls_tokens)
cls_tokens = self.norm(cls_tokens)
return cls_tokens
def forward(self, x):
cls_token = self.forward_features(x)
cls_token = self.head(cls_token[:, 0])
return cls_token
















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









