







第一步 先准备环境
1,IDEA 安装的SDK是2.13.8版本
2,新建maven项目,依赖如下
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.0</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
案例1,使用spark sql读取json数据
准备json格式的数据
{"name":"Michael","age":23}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
代码如下
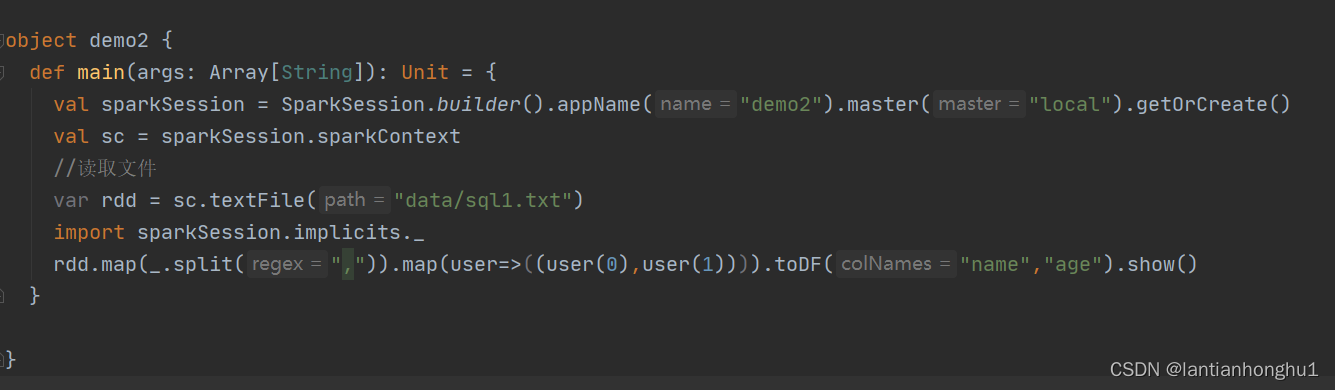
案例2 ,使用spark sql 进行多表联合查询
准备emp表的数据
{"name": "zhangsan","age": 26,"depId": 1,"gender": "女","salary": 20000}
{" name" : "lisi", "age": 36,"depld": 2,"gender": "男","salary": 8500}
{"name": "wangwu", "age": 23,"depId": 1,"gender": "女","salary": 5000}
{"name": "zhaoliu","age": 25,"depId": 3,"gender": "男","salary": 7000}
{"name": "marry", "age": 19, "depId": 2,"gender": "男","salary": 6600}
{"name": "Tom","age": 36,"depId": 4,"gender": "女","salary" : 5000}
{"name": "kitty", "age": 43,"depId": 2,"gender" : "女","salary": 6000}
准备部门表的数据
{"id": 1,"name": "Tech Department"}
{"id": 2,"name": "Fina Department"}
{"id": 3,"name": "HR Department"}
代码如下
package T6
import org.apache.spark.sql.SparkSession
object demo5 {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("demo5").master("local").getOrCreate()
import sparkSession.implicits._
//读取数据
val emp_rdd = sparkSession.read.json("data/sql5.txt")
val dept_rdd = sparkSession.read.json("data/sql6.txt")
//把json数据格式转换表
emp_rdd.createOrReplaceTempView("emp")
dept_rdd.createOrReplaceTempView("dept")
//获取每个员工的姓名,部门名称,工资
sparkSession.sql("select e.name,d.name,e.salary from emp e,dept d where e.depId=d.id").show()
//获取工资最高的女员工的姓名,部门名称,年龄
sparkSession.sql("select e.name,d.name,e.salary,e.age from emp e,dept d where e.depId=d.id and salary=" +
" (select max(salary) from emp where gender='女')").show()
//获取女员工的平均工资
sparkSession.sql("select avg(salary) from emp where gender='女' ").show()
// select e.name,d.name,e.salary,e.age from emp e,dept d where e.depId=d.id and salary=
}
}
案例3
准备数据
姓名 科目1 科目2 科目3 科目4
小卡拉 70 70 75 60
小黑 80 80 70 40
小贤 60 70 80 45
小豪 70 80 90 100
1,求每位学员的科目总分
2,求每科目的总分
,代码如下
package com.T5
import org.apache.spark.{SparkConf, SparkContext}
object demo5 {
def main(args: Array[String]): Unit = {
var sparkConf = new SparkConf().setAppName("demo5").setMaster("local")
var sc = new SparkContext(sparkConf)
//定义文件路径
var filepath = "data/aa.txt"
//获取第一行内容
var firstfile = sc.textFile(filepath).first()
//求每一个学员的总分
sc.textFile(filepath).filter(!_.equals(firstfile)).map(line=>{
//切割每一行内容
var arr = line.split("\t")
var name = arr(0)
var km1 = arr(1).toInt
var km2 = arr(2).toInt
var km3 = arr(3).toInt
var km4 = arr(4).toInt
//输出
(name,km1+km2+km3+km4)
}).foreach(println)
//求每个科目的总分
var km1 = 0
var km2 = 0
var km3 = 0
var km4 = 0
var i =0
sc.textFile(filepath).filter(!_.equals(firstfile)).map(line=>{
var arr = line.split("\t")
//输出
(arr(1).toInt,arr(2).toInt,arr(3).toInt,arr(4).toInt)
}).foreach(
x=>{
km1+=x._1
km2+=x._2
km3+=x._3
km4+=x._4
i+=1
if (i==4){
println(("科目1",km1),("科目2",km2),("科目3",km3),("科目4",km4))
}
}
)
}
}
















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











