










CVPR2022 | TopFormer介绍及复现
TopFormer介绍及复现
前言
论文名称TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
开源代码https://github.com/hustvl/TopFormer
虽然视觉transformers(ViTs)在计算机视觉领域取得了巨大的成功,但其高昂的计算成本阻碍了其在移动设备语义分割等密集预测任务中的应用。在本文中,我们提出了一个移动友好的架构,名为Token
Pyramid Vision Transformer(TopFormer)。TopFormer将来自不同尺度的token作为输入,产生尺度感知的语义特征,然后将这些特征注入到相应的token中,以增加表示。实验结果表明,我们的方法在多个语义分割数据集上显著优于基于CNN和基于ViT的网络,并且在准确性和延迟之间取得了很好的平衡。在ADE20K数据集上,TopFormer在mIoU上的精度比MobileNetV3高5%。
TopFormer介绍
1.Introduction
Vision Transformer(ViTs)在图像分类、目标检测和语义分割等少数视觉任务中显示出了相当强的效果。尽管取得了成功,但是具有全注意力机制的Transformer体系结构需要强大的计算资源,这超出了许多移动和嵌入式设备的能力。在本文中,我们的目标是探索一个移动友好的Vision Transformer。
为了使Vision Transformer适应各种密集的预测任务,最近的视觉Transformer如PVT、CvT、LeViT、MobileViT都采用分层结构,这种结构通常用于卷积神经网络(CNNs)中,如AlexNet、ResNet。这些Vision transformer将全局自注意及其变体应用于高分辨率Token,由于Token数量的二次复杂度带来了沉重的计算成本。
为了提高效率,最近的一些工作,例如Swin Transformer, Shuffle Transformer, Twins和HR-Former,计算本地/窗口区域内的自注意。然而,窗口分区在移动设备上非常耗时。此外,Token slimming和Mobile-Former通过减少Token数量来降低计算能力,但牺牲了它们的识别准确性。
在这些视觉变压器中,MobileViT和mobile - former是专门为移动设备设计的。它们都结合了CNNs和ViTs的优势。在图像分类方面,MobileViT在相同数量的参数下比MobileNets具有更好的性能。Mobile-Former以更少的失败次数获得比mobilenet更好的性能。然而,与mobilenet相比,它们在移动设备上的实际延迟方面并没有显示出优势,正如所报道的那样。它提出了一个问题:是否有可能设计移动友好的网络,可以在移动语义分割任务上取得比mobilenet更低延迟的更好的性能?
受MobileViT和Mobile-Former的启发,我们也利用了CNNs和ViTs的优势。一个基于CNN的模块,标记金字塔模块,用来处理高分辨率的图像,快速产生局部特征金字塔。考虑到移动设备上的计算能力非常有限,这里我们使用几个堆叠的轻量级MobileNetV2块和快速下采样策略来构建Token pyramid。为了获得丰富的语义和较大的接受域,采用基于ViT的模块,记作语义提取器,并以Token作为输入。为了进一步降低计算成本,使用平均池操作符将Token减少到一个非常小的数字,例如,输入大小的1/(64×64)。与ViT、T2T-ViT和LeViT不同的是,我们使用嵌入层的最后一个输出作为输入标记,将来自不同尺度(阶段)的标记汇集到非常小的数字(分辨率)中,并沿着通道维度将它们连接起来。然后将新的Token输入到Transformer块中,以产生全局语义。由于Transformer块中的残留连接,学习到的语义与Token的规模相关,表示为感知规模的全局语义。
为了在密集预测任务中获得强大的层次特征,该方法将感知尺度的全局语义通过不同尺度的标记通道进行分割,然后将感知尺度的全局语义与对应的标记进行融合,以增强表示。扩增标记被用作分割头的输入。为了证明我们的方法的有效性,我们对具有挑战性的分割数据集:ADE20K , Pascal Context和COCOStuff进行了实验。我们检查硬件上的延迟,例如,一个现成的基于arm的计算核心。如图1所示,我们的方法获得的结果比mobilenet更低的延迟。为了证明该方法的通用性,我们还在COCO数据集上进行了目标检测实验。总之,我们的贡献如下。
提出的TopFormer以来自不同尺度的Token 作为输入,并将Token 集中到非常小的数字中,以便以非常低的计算成本获得尺度感知语义。
语义注入模块可以将感知尺度的语义注入到相应的令牌中,从而构建强大的层次特征,这对于密集的预测任务至关重要。
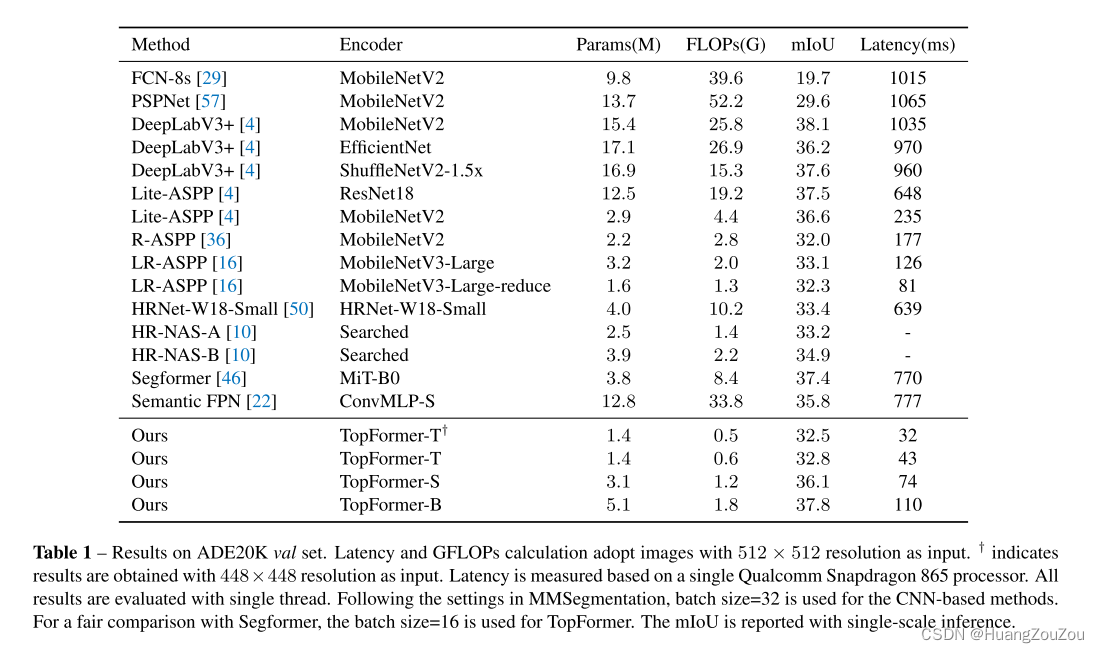
提议的基础模型可以达到比MobileNetV3更好的5% mIoU,在基于arm的移动设备上的ADE20K数据集上具有更低的延迟。这个小版本可以在基于arm的移动设备上进行实时细分,结果很有竞争力。
2.网络结构
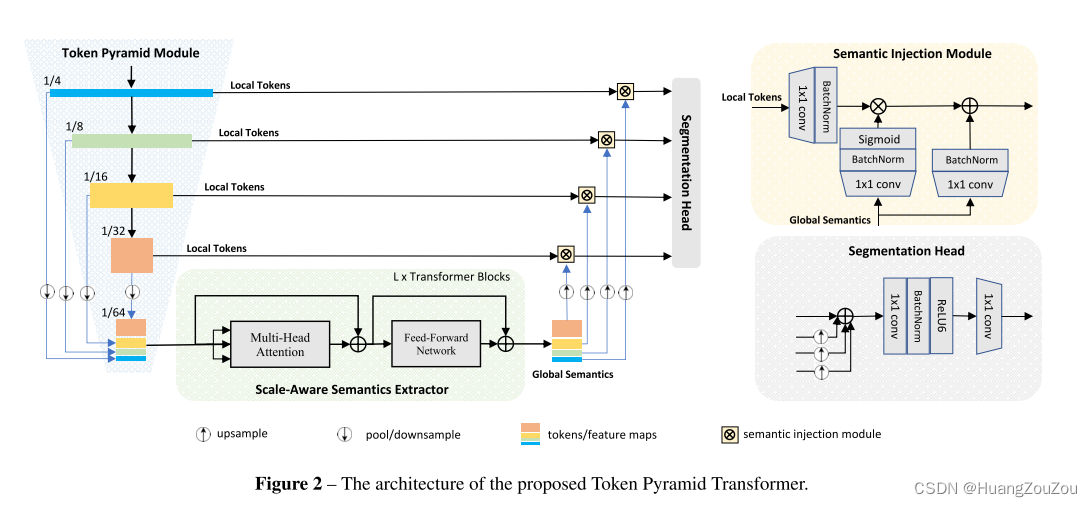
我们的网络由几个部分组成:Token Pyramid Module, Semantics Extractor, Semantics Injection Module 和Segmentation Head。Token Pyramid Module以图像作为输入并产生Token Pyramid。Vision Transformer用作语义提取器,以Token Pyramid为输入,产生尺度感知语义。语义被注入到相应规模的标记中,以通过语义注入模块增加表示。最后,Segmentation Head使用增强的Token Pyramid来执行分割任务。接下来,我们将介绍这些模块的详细信息。
2.1 Token Pyramid Module
受MobileNet的启发,提议的Token Pyramid Module由堆叠的MobileNet块组成。与mobilenet不同,Token Pyramid Module的目标不是获取丰富的语义和大的接受域,而是使用更少的块来构建Token Pyramid。
我们的Token Pyramid Module首先将图像通过一些MobileNetV2块来产生一系列令牌{T1,…, TN},其中N为尺度个数。之后,令牌{T1,…, TN},平均池化到目标大小,例如,H/64×W/64。最后,将来自不同尺度的Token沿通道维串接以产生新的Token。新的Token将被输入Vision Transformer以产生可感知尺度的语义。因为新的Token数量很少,所以即使新Token有很大的通道,Vision Transformer也可以以非常低的计算成本运行。
2.2 Vision Transformer as Scale-aware Semantics
尺度感知语义提取器由几个堆叠的Transformer块组成。变压器块的数量为L。变压器块由多头注意模块、前馈网络(FFN)和剩余连接组成。为了保持令牌的空间形状并减少重塑次数,我们用1 × 1卷积层代替线性层。此外,TopFormer的非线性激活都是ReLU6而不是ViT中的GELU函数。
对于Multi-head Attention模块,我们按照LeViT[12]的设置,将key K和queries Q的head尺寸设置为D = 16,将value V的head设置为2D = 32 channels。减少K和Q的通道可以降低计算注意映射和输出时的计算成本。同时,我们还去掉了层标准化层,并在每个卷积上附加一个批量标准化。在推理过程中,可以将批处理归一化与前面的卷积合并,在层归一化上运行速度更快。
2.3 Semantics Injection Module and Segmentation Head
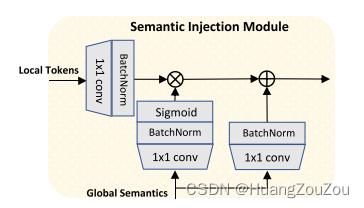
在获得尺度感知语义之后,我们将它们与其他标记TN直接相加。然而,标记{T1,…, TN}和尺度感知语义。为此,引入语义注入模块以在融合这些标记之前缓解语义差距。如图2所示,语义注入模块(SIM)以Token Pyramid模块的局部令牌和Vision Transformer的全局语义作为输入。局部Token通过1 × 1卷积层传递,然后进行批量归一化,生成要注入的特征。将全局语义输入到1×1卷积层,然后是批处理归一层和sigmoid层,生成语义权值,同时,全局语义也经过1×1卷积层,然后是批处理归一层。这三个输出具有相同的大小。然后,通过Hadamard生成将全局语义注入到局部令牌中,并将注入后的特性添加到全局语义中。多个SIMs的输出共享相同数量的通道,记为M。
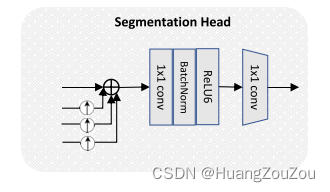
语义注入后,不同尺度的扩充Token捕获了丰富的空间和语义信息,这对语义分割至关重要。此外,语义注入还消除了标记之间的语义鸿沟。该分割方法首先将低分辨率令牌向上采样到与高分辨率令牌相同的大小,然后在元素层面上对所有尺度的令牌进行求和。最后,特征经过两个卷积层生成最终的分割图。
3.Experiments
TopFormer复现
环境配置真的很重要,各种版本的包要兼容
开源代码https://github.com/hustvl/TopFormer
大家这里就先按照我这里的版本安装,以免出现问题。
步骤1.安装pytorch
我用的是RTX3090所以cuda版本要求11.x。
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
步骤2.使用mim安装mmcv-full
pip install -U openmim
mim install mmcv-full==1.3.14
根据系统的类型、CUDA 版本、PyTorch 版本以及 MMCV 版本选择相应的安装命令可以参考https://mmcv.readthedocs.io/zh-cn/1.x/get_started/installation.html#pip
列举一下复现过程可能遇到的一些问题:
- ModuleNotFoundError: No module named ‘mmcv.runner
from mmcv.runner import get_dist_info, init_dist
from mmcv.utils import Config, DictAction, get_git_hash
如果这里直接默认安装不指定相应的mmcv版本就很有可能出现这个错误。因为mmcv后期的版本架构变了,runner在mmengine包中。
-
AssertionError: MMCV==1.7.1 is used but incompatible. Please install mmcv>=1.3.13, <=1.5.0.

-
tools/dist_train.sh: 7: Bad substitution

下面是README.md中的代码
sh tools/dist_train.sh local_configs/topformer/<config-file> <num-of-gpus-to-use> --work-dir /path/to/save/checkpoint
我们如何按照上面代码运行可能提示tools/dist_train.sh: 7: Bad substitution,我们只需要将sh改成bash
bash tools/dist_train.sh local_configs/topformer/<config-file> <num-of-gpus-to-use> --work-dir /path/to/save/checkpoint
例如:
bash tools/dist_train.sh local_configs/topformer/topformer_base_1024x512_80k_2x8city.py 1 --work-dir /path/to/save/checkpoint
总结
提示:这里对文章进行总结:
以上就是今天要讲的内容,本文仅仅简单介绍了TopFormer及复现,有问题欢迎评论区留言!















 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











