







前言
本期将分享「TopFormer」,论文地址https://arxiv.org/abs/2204.05525。源码地址https://github.com/hustvl/TopFormer
数据集
本次使用的数据集介绍参考之前的文章如何制作马萨诸塞州道路遥感数据集
TopFormer
TopFormer包含以下几个部分:
-
Token Pyramid Module:输入待分割的图像,输出token金字塔。 -
Semantics Extractor:输入token金字塔,输出scale-aware的语义信息。 -
Semantics Injection Module:将Semantics Extractors输出的语义信息与对应scale的特征进行融合。 -
分割Head:将融合后的特征作为输入,输出分割结果。 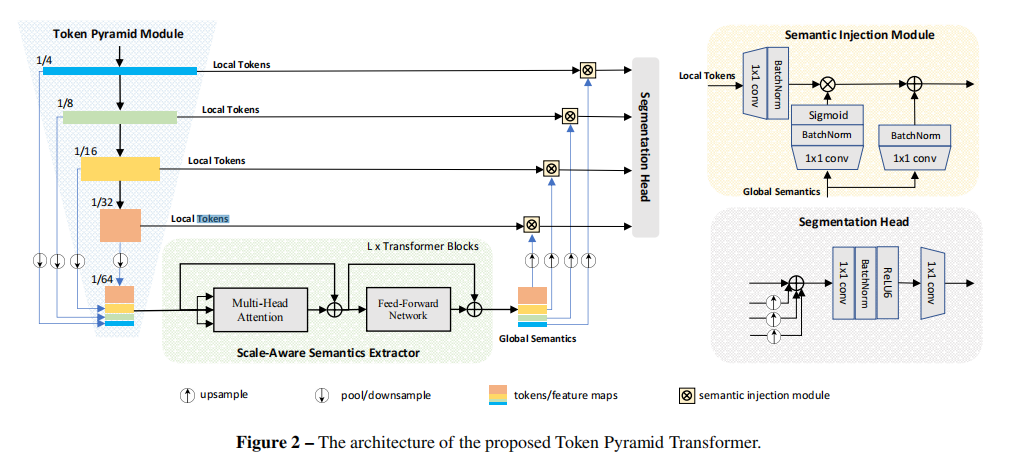
网络结构
结构来源https://github.com/bonne658/topformer
import torch, math
from torch import nn
from collections import OrderedDict
import torch.nn.functional as F
cfgs=[
# kernel, expand_ratio, output_channel, stride
[3, 1, 16, 1], # 1/2 0.464K 17.461M
[3, 4, 32, 2], # 1/4 1 3.44K 64.878M
[3, 3, 32, 1], # 4.44K 41.772M
[5, 3, 64, 2], # 1/8 3 6.776K 29.146M
[5, 3, 64, 1], # 13.16K 30.952M
[3, 3, 128, 2], # 1/16 5 16.12K 18.369M
[3, 3, 128, 1], # 41.68K 24.508M
[5, 6, 160, 2], # 1/32 7 0.129M 36.385M
[5, 6, 160, 1], # 0.335M 49.298M
[3, 6, 160, 1], # 0.335M 49.298M
]
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
############## 1
class Conv2d_BN(nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1, groups=1, bn_weight_init=1, lwd='c'):
super().__init__()
self.inp_channel = a
self.out_channel = b
self.ks = ks
self.pad = pad
self.stride = stride
self.dilation = dilation
self.groups = groups
self.add_module(lwd, nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=False))
bn = nn.BatchNorm2d(b)
nn.init.constant_(bn.weight, bn_weight_init)
nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
class InvertedResidual(nn.Module):
def __init__(self, inp: int, oup: int, ks: int, stride: int, expand_ratio: int, activations = None) -> None:
super(InvertedResidual, self).__init__()
self.stride = stride
self.expand_ratio = expand_ratio
assert stride in [1, 2]
if activations is None:
activations = nn.ReLU
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
# pw
layers.append(Conv2d_BN(inp, hidden_dim, ks=1))
layers.append(activations())
layers.extend([
# dw
Conv2d_BN(hidden_dim, hidden_dim, ks=ks, stride=stride, pad=ks//2, groups=hidden_dim),
activations(),
# pw-linear
Conv2d_BN(hidden_dim, oup, ks=1)
])
self.conv = nn.Sequential(*layers)
self.out_channels = oup
self._is_cn = stride > 1
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class TokenPyramidModule(nn.Module):
def __init__(self, out_indices, inp_channel=16, activation=nn.ReLU, width_mult=1.):
super().__init__()
self.out_indices = out_indices
self.stem = nn.Sequential(
Conv2d_BN(3, inp_channel, 3, 2, 1),
activation()
)
self.layers = []
for i, (k, t, c, s) in enumerate(cfgs):
output_channel = _make_divisible(c * width_mult, 8)
layer_name = 'layer{}'.format(i + 1)
layer = InvertedResidual(inp_channel, output_channel, ks=k, stride=s, expand_ratio=t, activations=activation)
self.add_module(layer_name, layer)
inp_channel = output_channel
self.layers.append(layer_name)
def forward(self, x):
outs = []
x = self.stem(x)
for i, layer_name in enumerate(self.layers):
layer = getattr(self, layer_name)
x = layer(x)
if i in self.out_indices:
outs.append(x)
return outs
############## 2
def get_shape(tensor):
shape = tensor.shape
if torch.onnx.is_in_onnx_export():
shape = [i.cpu().numpy() for i in shape]
return shape
class PyramidPoolAgg(nn.Module):
def __init__(self, stride):
super().__init__()
self.stride = stride
def forward(self, inputs):
B, C, H, W = get_shape(inputs[-1])
H = (H - 1) // self.stride + 1
W = (W - 1) // self.stride + 1
return torch.cat([nn.functional.adaptive_avg_pool2d(inp, (H, W)) for inp in inputs], dim=1)
############## 3
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class Attention(torch.nn.Module):
def __init__(self, dim, key_dim, num_heads, attn_ratio=4, activation=None):
super().__init__()
self.num_heads = num_heads
#self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads # num_head key_dim
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
self.to_q = Conv2d_BN(dim, nh_kd, 1)
self.to_k = Conv2d_BN(dim, nh_kd, 1)
self.to_v = Conv2d_BN(dim, self.dh, 1)
self.proj = torch.nn.Sequential(activation(), Conv2d_BN(self.dh, dim, bn_weight_init=0))
def forward(self, x): # x (B,N,C)
B, C, H, W = get_shape(x)
# B*num_heads*hw*key_dim,每个像素有key_dim维
qq = self.to_q(x).reshape(B, self.num_heads, self.key_dim, H * W).permute(0, 1, 3, 2)
# B*num_heads*key_dim*hw
kk = self.to_k(x).reshape(B, self.num_heads, self.key_dim, H * W)
# B*num_heads*hw*d
vv = self.to_v(x).reshape(B, self.num_heads, self.d, H * W).permute(0, 1, 3, 2)
# B*num_heads*hw*hw
attn = torch.matmul(qq, kk)
# hw的每个元素与所有元素的权重,类似协方差矩阵
attn = attn.softmax(dim=-1) # dim = k
# B*num_heads*hw*d
xx = torch.matmul(attn, vv)
xx = xx.permute(0, 1, 3, 2).reshape(B, self.dh, H, W)
xx = self.proj(xx)
return xx
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = Conv2d_BN(in_features, hidden_features)
self.dwconv = nn.Conv2d(hidden_features, hidden_features, 3, 1, 1, bias=True, groups=hidden_features)
self.act = act_layer()
self.fc2 = Conv2d_BN(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.dwconv(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, key_dim, num_heads, mlp_ratio=4., attn_ratio=2., drop=0., drop_path=0., act_layer=nn.ReLU):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
self.attn = Attention(dim, key_dim=key_dim, num_heads=num_heads, attn_ratio=attn_ratio, activation=act_layer)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x1):
x1 = x1 + self.drop_path(self.attn(x1))
x1 = x1 + self.drop_path(self.mlp(x1))
return x1
class BasicLayer(nn.Module):
def __init__(self, block_num, embedding_dim, key_dim, num_heads, mlp_ratio=4., attn_ratio=2., drop=0., attn_drop=0., drop_path=0., act_layer=None):
super().__init__()
self.block_num = block_num
self.transformer_blocks = nn.ModuleList()
for i in range(self.block_num):
self.transformer_blocks.append(Block(
embedding_dim, key_dim=key_dim, num_heads=num_heads,
mlp_ratio=mlp_ratio, attn_ratio=attn_ratio,
drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
act_layer=act_layer))
def forward(self, x):
# token * N
for i in range(self.block_num):
x = self.transformer_blocks[i](x)
return x
############## 4
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class InjectionMultiSum(nn.Module):
def __init__(self, inp: int, oup: int, activations = None) -> None:
super(InjectionMultiSum, self).__init__()
#self.local_embedding = ConvModule(inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
#self.global_embedding = ConvModule(inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
#self.global_act = ConvModule(inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
self.local_embedding = Conv2d_BN(inp, oup, lwd='conv')
self.global_embedding = Conv2d_BN(inp, oup, lwd='conv')
self.global_act = Conv2d_BN(inp, oup, lwd='conv')
self.act = h_sigmoid()
def forward(self, x_l, x_g):
'''
x_g: global features
x_l: local features
'''
B, C, H, W = x_l.shape
local_feat = self.local_embedding(x_l)
global_act = self.global_act(x_g)
sig_act = F.interpolate(self.act(global_act), size=(H, W), mode='bilinear', align_corners=False)
global_feat = self.global_embedding(x_g)
global_feat = F.interpolate(global_feat, size=(H, W), mode='bilinear', align_corners=False)
out = local_feat * sig_act + global_feat
return out
class Backbone(nn.Module):
def __init__(self,
channels=[32, 64, 128, 160],
out_channels=[None, 256, 256, 256],
embed_out_indice=[2, 4, 6, 9],
decode_out_indices=[1, 2, 3],
depths=4,
key_dim=16,
num_heads=8,
attn_ratios=2,
mlp_ratios=2,
c2t_stride=2,
drop_path_rate=0.1,
act_layer=nn.ReLU6,
injection_type="muli_sum",
init_cfg=None,
injection=True):
super().__init__()
self.channels = channels
self.injection = injection
self.embed_dim = sum(channels)
self.decode_out_indices = decode_out_indices
self.init_cfg = init_cfg
if self.init_cfg != None:
self.pretrained = self.init_cfg['checkpoint']
self.tpm = TokenPyramidModule(out_indices=[2, 4, 6, 9])
self.ppa = PyramidPoolAgg(stride=2)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depths)] # stochastic depth decay rule
self.trans = BasicLayer(block_num=depths, embedding_dim=self.embed_dim, key_dim=key_dim, num_heads=num_heads,
mlp_ratio=mlp_ratios, attn_ratio=attn_ratios, drop=0, attn_drop=0, drop_path=dpr, act_layer=act_layer)
# SemanticInjectionModule
self.SIM = nn.ModuleList()
inj_module = InjectionMultiSum
if self.injection:
for i in range(len(channels)):
if i in decode_out_indices:
self.SIM.append(
inj_module(channels[i], out_channels[i], activations=act_layer))
else:
self.SIM.append(nn.Identity())
def forward(self, x):
ouputs = self.tpm(x)
out = self.ppa(ouputs)
out = self.trans(out)
if self.injection:
xx = out.split(self.channels, dim=1)
results = []
for i in range(len(self.channels)):
if i in self.decode_out_indices:
local_tokens = ouputs[i]
global_semantics = xx[i]
out_ = self.SIM[i](local_tokens, global_semantics)
results.append(out_)
return results
else:
ouputs.append(out)
return ouputs
class Head(nn.Module):
def __init__(self,num_class, c=256):
super().__init__()
self.conv_seg = nn.Conv2d(c, num_class, kernel_size=1)
self.linear_fuse = nn.Sequential(OrderedDict([
('conv', nn.Conv2d(c, c, 1, stride=1, padding=0, dilation=1, groups=1, bias=False)),
('bn', nn.BatchNorm2d(c))
]))
self.act = nn.ReLU6()
self.dropout = nn.Dropout2d(0.1)
def forward(self, x):
x=self.act(self.linear_fuse(x))
x=self.dropout(x)
return self.conv_seg(x)
class TopFormer(nn.Module):
def __init__(self,num_class=2) -> None:
super().__init__()
self.backbone=Backbone()
self.decode_head=Head(num_class)
self.init_weights()
def forward(self, x):
B, C, H, W = x.shape
x=self.backbone(x)
xx=x[0]
for i in x[1:]:
xx += F.interpolate(i, xx.size()[2:], mode='bilinear', align_corners=False)
xx = self.decode_head(xx)
return F.interpolate(xx, (H,W), mode='bilinear', align_corners=False)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
n //= m.groups
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None: m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
if m.bias is not None: m.bias.data.zero_()
训练结果
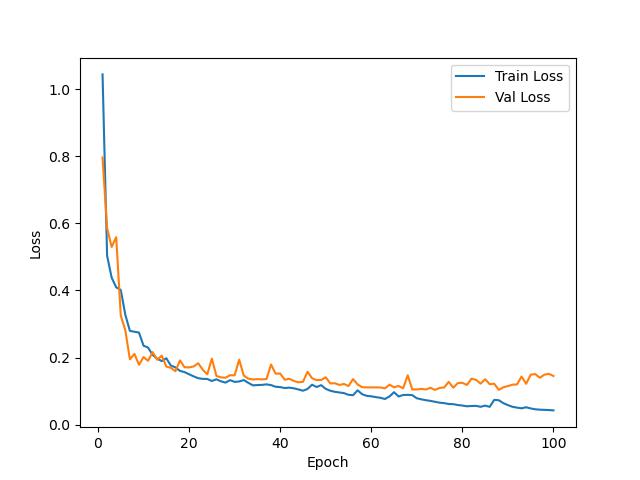
测试结果

结语
「完整代码与训练结果请加入我们的星球。」
「感兴趣的可以加入我们的星球,获取更多数据集、网络复现源码与训练结果的」。
 「加入前不要忘了在公众号首页领取优惠券哦!」
「加入前不要忘了在公众号首页领取优惠券哦!」
往期精彩
本文由 mdnice 多平台发布















 8554
8554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











