







论文名称:使用门控卷积递归网络学习复杂频谱映射以增强单声道语音
论文地址:https://ieeexplore.ieee.org/abstract/document/8910352
1.摘要
相位对于语音的感知质量很重要。然而,由于其中缺乏光谱时间结构,通过监督学习直接估计相谱似乎很棘手。复谱映射旨在从嘈杂语音中估计干净语音的实部和虚部频谱图,同时增强语音的幅度和相位响应。受多任务学习的启发,我们提出了一个用于复杂频谱映射的门控卷积循环网络 (GCRN),相当于一个用于单声道语音增强的因果系统。我们的实验结果表明,所提出的 GCRN 在客观语音清晰度和质量方面大大优于现有的用于复杂频谱映射的卷积神经网络 (CNN)。此外,所提出的方法产生的 STOI 和 PESQ 明显高于幅度谱映射和复比掩蔽。我们还发现,使用所提出的 GCRN 的复谱映射提供了有效的相位估计。
2.复数谱映射
混合噪声建模为 y[k] = s[k] + n[k]
取两边STFT,得到

在极坐标中表示为:

语音信号的 STFT 可以用笛卡尔坐标表示:
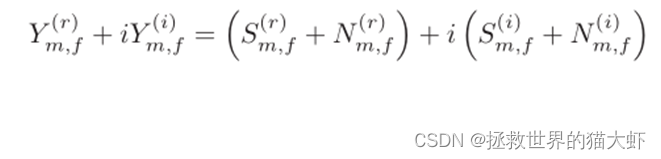
幅度谱映射:从噪声特征(如噪声幅度谱)到目标幅度的映射被学习。然后将估计的幅度与噪声相位相结合,重新合成波形
复数谱映射:直接从噪声语音的实谱和虚谱到纯净语音的实谱和虚谱学习谱映射。随后,估计的实谱和虚谱被合并以恢复时域信号
3.卷积循环网络(CRN)

我们使用一个卷积递归网络,它本质上是一个编码器-解码器架构,在编码器和解码器之间有LSTMs。具体来说,编码器包括五个卷积层,而解码器包括五个去卷积层。在编码器和解码器之间,两个LSTM层对时间依赖性进行建模。编码器-解码器的结构是以对称的方式设计的:内核的数量在编码器中逐渐增加,在解码器中逐渐减少。为了沿频率方向汇总上下文,在所有卷积层和解卷积层中沿频率维度采用2的跨度。换句话说,特征图的频率维度在编码器中逐层减半,在解码器中逐层翻倍,这确保了输出与输入具有相同的形状。此外,跳过连接被用来将每个编码器层的输出与相应的解码器层的输入连接起来。在CRN中,所有的卷积和解旋都是因果关系,因此增强系统不使用未来信息。图说明了CRN架构,用于幅值域的频谱映射。
4.基于Mask的语音增强
在 TF 域中定义的训练目标主要分为两组,即基于掩蔽的目标和基于映射的目标,前者描述了干净语音和背景噪声之间的时频关系,后者对应响应干净语音的频谱表示。下面介绍基于掩蔽的语音增强方法。
提出两个假设
1.我们假设信号能量稀疏的,即对于大多数时频区域它的能量为0,如下图所示,我们可以看到大多数区域的值,即频域能量为0。
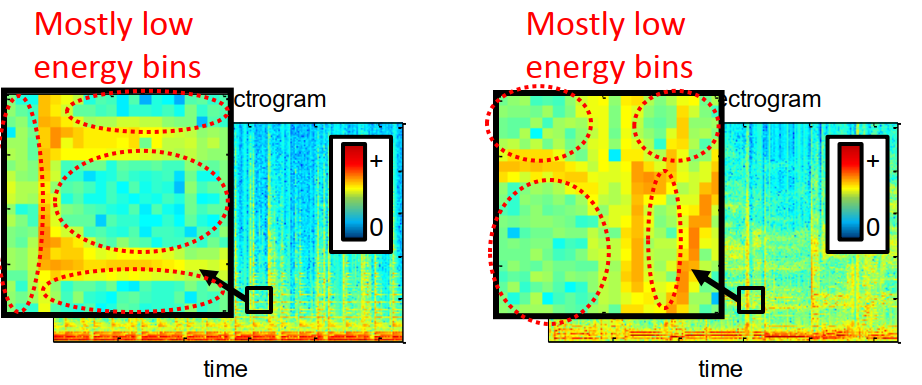
2.我们假设信号能量不相交的,即它们的时频区域不重叠或者重叠较少,如下图所示,我们可以看到时频区域不为0的地方不重叠或者有较少部分的重叠。
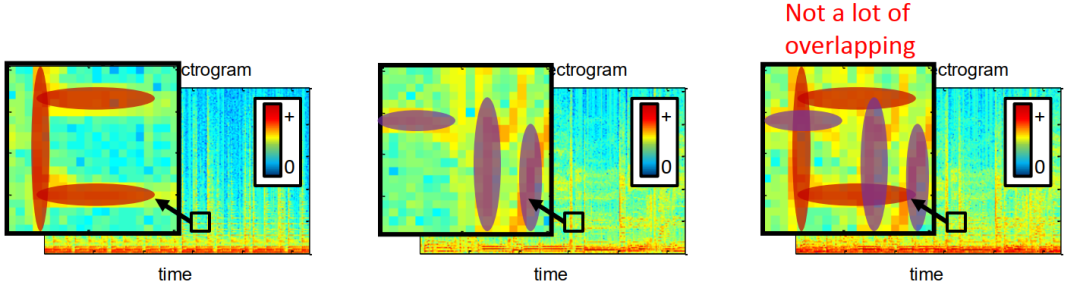
我们通过0和1的二值掩码然后乘以混合信号的语谱图就可以得到我们想要喜好的语谱图了,如下图所示
该如何计算掩蔽值,掩蔽值计算方法有许多,但一般来说有两种常用的计算方法,分别为理想二值掩蔽(Ideal Binary Mask, IBM)和理想比值掩蔽(Ideal Ratio Mask, IRM)。IBM的计算公式如下

其中LC为阈值,一般取0,SNR计算公式为:

IRM为一个[0-1]的值,计算公式为:

本文使用的估计值cIRM,定义为

使用M乘以Y得到增强的频谱图的估计S
本文扩展了信号近似(SA),SA 通过最小化干净语音和估计语音的频谱幅度之间的差异来执行掩蔽
基于 cRM 的信号近似 (cRM-SA) 的损失定义为:

(其中绝对值表示复数模数,即复数的绝对值)
5.分组策略
本文提出了一种分组策略来提高循环层的效率,同时保持其性能。

如图4(b)所示,在每个组内分开。分组操作大大减少了层间连接的数量,从而降低了模型的复杂性。但是,无法捕获组间依赖性。换句话说,输出仅取决于相应特征组中的输入,无法学习来自不同组的特征之间的依赖性,这可能会显着降低表示能力。
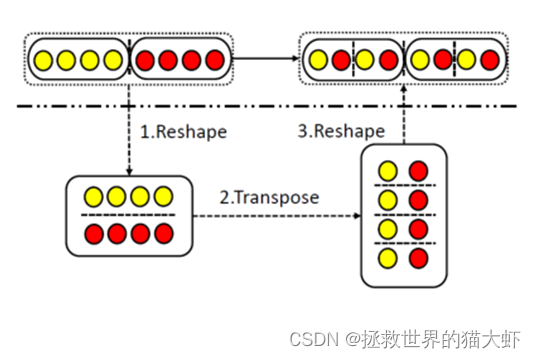
为了缓解这个问题,在连续组循环层之间添加表示重排层,采用两个连续循环层之间的无参数表示重排层来重新排列特征和隐藏状态,从而恢复组间相关性(图 4(c))。为了提高模型效率,我们在模型中对 LSTM 层采用这种分组策略。我们发现这种策略通过适当的组数提高了增强性能。
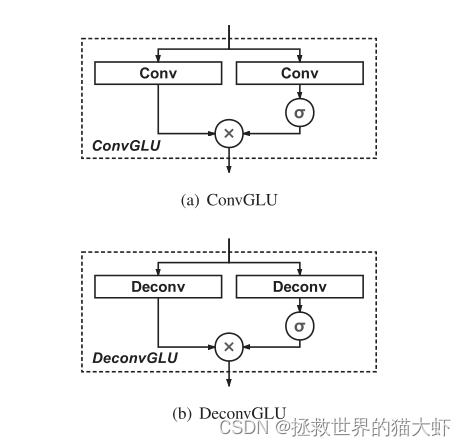
6.Gated Linear Units
卷积GLU和反卷积GLU结构:

7.网络架构
门控卷积循环网络 (GCRN)

带噪语音的实部和虚部频谱图被视为两个不同的输入通道。编码器模块和 LSTM 模块在实部和虚部的估计中共享,而两个不同的解码器模块分别用于估计实部和虚部频谱图。
每个卷积或反卷积 GLU 块后面依次是批量归一化操作和指数线性单元 (ELU) 激活函数。线性层堆叠在每个解码器的顶部,以将学习到的特征投射到真实或虚构的频谱图中。
网络架构的详细信息:

每层的输入大小和输出大小以 featureM aps × timeSteps × frequencyChannels 格式给出。此外,层超参数以 (kernelSize, strides, outChannels) 格式指定。请注意,每个解码器层中的特征图数量因跳过连接而翻倍。我们没有在 [32] 中使用 2 × 3(时间 × 频率)的内核大小,而是使用 1 × 3 的内核大小,我们发现这不会降低性能。
8.结论
在这项研究中,我们提出了一个使用卷积循环网络进行复杂频谱映射的新框架,该网络学习从嘈杂语音的真实和虚构频谱图映射到干净语音的频谱图。它同时增强了噪声语音的幅度和相位响应。受多任务学习的启发,所提出的方法扩展了新开发的 CRN,并产生了一种用于单声道语音增强的因果、噪声和说话人无关的算法。我们的实验结果表明,我们提出的模型的复谱映射显着改善了幅度谱映射的 STOI 和 PESQ,以及复比掩蔽和基于复比掩蔽的信号近似。此外,我们提出的模型在复杂光谱映射方面大大优于现有的 CNN。
此外,我们将分组策略纳入循环层,以在保持性能的同时显着提高模型效率。我们提出的方法还提供了一个相位估计,它被证明比噪声阶段更接近清洁阶段。从另一个角度来看,我们发现当与噪声幅度或增强幅度相结合时,估计相位产生明显高于噪声相位的 STOI 和 PESQ。应该注意的是,可以从目标复杂频谱图中完美地恢复干净的语音。我们认为,基于 GCRN 的复杂频谱映射方法代表了在不利声学环境和实际应用中产生高质量增强语音的重要一步。在未来的研究中,我们计划将我们的方法扩展到多通道语音增强,其中准确的相位估计可能更为重要。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









