







 本文介绍了作者在参与BirdCLEF2023Kaggle比赛中的经历,关注于鸟类声音识别,包括处理背景噪音、多标签分类、特征提取(如logmel和MFCC)、数据标准化、数据增强策略,以及模型训练和评估技巧,如CNN和LSTM等模型的应用。
本文介绍了作者在参与BirdCLEF2023Kaggle比赛中的经历,关注于鸟类声音识别,包括处理背景噪音、多标签分类、特征提取(如logmel和MFCC)、数据标准化、数据增强策略,以及模型训练和评估技巧,如CNN和LSTM等模型的应用。
第一次接触鸟声相关以及契合自己的研究方向记录一下自己的看法以及获奖者的创新点
对我来说遇到了不少困难
- 背景噪音——尤其是在使用城市中记录的数据时(例如城市噪音、汽车和人声等等)
- 多标签分类问题——当有许多物种同时唱歌时
- 不同类型的鸟鸣声(同一种鸟的不同叫声)
- 物种间差异——生活在不同地区或国家的同一物种之间的鸟鸣声可能存在差异
- 数据集问题——由于一个物种比另一个物种更受欢迎,数据可能高度不平衡,有大量不同的物种,录音可能有不同的长度、录音质量(体积、清洁度)
找一下相关论文以及比赛进行相关深入了解
1.任务描述
鸟类是生物多样性变化的绝佳指标,因为它们具有高度流动性并且具有不同的栖息地要求。因此,物种组合和鸟类数量的变化可以表明恢复项目的成功或失败。然而,频繁地在大面积范围内进行传统的基于观察者的鸟类生物多样性调查不仅成本高昂,而且在后勤方面也具有挑战性。相比之下,被动声学监测(PAM)与基于机器学习的新分析工具相结合,使保护主义者能够以更高的时间分辨率采样更大的空间尺度,并深入探索恢复干预措施与生物多样性之间的关系。

在本次比赛中,您将利用机器学习技能通过声音识别东非鸟类种类。具体来说,您将开发计算解决方案来处理连续音频数据并通过声音识别物种。
2.特征提取
调研了一些论文发现logmel频谱图用的比较多,当然还有很多比如梅尔频率倒谱系数MFCC,伽马通倒谱系数 GTCC等等。也可以进行特征融合比如提取梅尔一阶差分值和梅尔二阶差分值,根据MFCC特征,可以对每一帧的特征值进行一阶差分和二阶差分的计算。一阶差分是指相邻两帧MFCC系数的差值,二阶差分是指相邻两帧一阶差分值的差值。将每一帧的MFCC特征值、梅尔一阶差分值和梅尔二阶差分值按照一定的方式进行组合,可以得到一个维度更高的融合特征向量。复杂的特征会增加推理时间,需要视情况考虑。自己搞个embedding做输入也行。
对于有推理时间限制的一般采用log梅谱图,可以使用 torchaudio 或librosa库生成频谱图。使用以下参数生成频谱图:sample_rate=32000、n_mels=128、fmax=14000、fmin=50 ,hop_size=512、hop_size=512、top_db=None,可以尝试不同时间频谱分辨率带来的效果。
def compute_melspec(y, params):
"""
Computes a mel-spectrogram and puts it at decibel scale
Arguments:
y {np array} -- signal
params {AudioParams} -- Parameters to use for the spectrogram. Expected to have the attributes sr, n_mels, f_min, f_max
Returns:
np array -- Mel-spectrogram
"""
melspec = librosa.feature.melspectrogram(
y, sr=params.sr, n_mels=params.n_mels, fmin=params.fmin, fmax=params.fmax, n_fft=2048, hop_length=512,
)
melspec = librosa.power_to_db(melspec).astype(np.float32) #log梅普图
return melspec标准化处理
def normalize(image, mean=None, std=None):
"""
Normalizes an array in [0, 255] to the format adapted to neural network
Arguments:
image {np array [3 x H x W]} -- [description]
Keyword Arguments:
mean {None or np array} -- Mean for normalization, expected of size 3 (default: {None})
std {None or np array} -- Std for normalization, expected of size 3 (default: {None})
Returns:
np array [H x W x 3] -- Normalized array
"""
image = image / 255.0
if mean is not None and std is not None:
image = (image - mean) / std
return np.moveaxis(image, 2, 0).astype(np.float32)对比5s短的音频采用0填充,比5s长的随机选择一个起点进行裁剪
def crop_or_pad(y, length, sr, train=True, probs=None): #如果原始信号比length短,它会用零填充信号。如果原始信号比length长,则随机选择一个起始点
"""
Crops an array to a chosen length
Arguments:
y {1D np array} -- Array to crop
length {int} -- Length of the crop
sr {int} -- Sampling rate
Keyword Arguments:
train {bool} -- Whether we are at train time. If so, crop randomly, else return the beginning of y (default: {True})
probs {None or numpy array} -- Probabilities to use to chose where to crop (default: {None})
Returns:
1D np array -- Cropped array
"""
if len(y) <= length:
y = np.concatenate([y, np.zeros(length - len(y))])
else:
if not train:
start = 0
elif probs is None:
start = np.random.randint(len(y) - length)
else:
start = (
np.random.choice(np.arange(len(probs)), p=probs) + np.random.random()
)
start = int(sr * (start))
y = y[start : start + length]
return y.astype(np.float32)3.数据增强
数据增强必不可少,目前对语音增强基本都是先转成频谱图进行图像那一套增强方法,可以进行各种不同的尝试
- GaussianNoise
- PinkNoise
- BackgroundNoise
- CutMix
- OR Mixup on waveforms
- Mixup on spectrograms.
- Gain
- PitchShift
- FrequencyMasking
- TimeMasking
上面是一些普遍适用的,还有很多增强方法自己多尝试
def get_wav_transforms():
"""
Returns the transformation to apply on waveforms
Returns:
Audiomentations transform -- Transforms
"""
transforms = Compose(
[
# HorizontalFlip(p=0.5), #将图像水平翻转
#AddGaussianSNR(max_SNR=0.5, p=0.5),
#AddBackgroundNoise(
# sounds_path=BACKGROUND_PATH, min_snr_in_db=5, max_snr_in_db=10, p=0.5),
TimeMask(min_band_part=0.1, max_band_part=0.15, fade=True, p=0.5,),
#SpecFrequencyMask(min_mask_fraction=0.03, max_mask_fraction=0.25, p=0.3, ), #这个好像有问题
#torchaudio.transforms.TimeMasking(time_mask_param=100, p=0.5),
#torchaudio.transforms.FrequencyMasking(freq_mask_param=10),
Gain(min_gain_in_db=-15, max_gain_in_db=15, p=0.3),
OneOf([
# Cutout(max_h_size=5, max_w_size=16, p=0.5), # 类似于timemask,取一块区域像素点全部替换成0
# CoarseDropout(max_holes=4, p=0.5), # 随机选取若干个矩形区域
AddGaussianNoise(min_amplitude=0.001, max_amplitude=0.015, p=0.5),
AddGaussianSNR(min_snr_in_db=0.5, max_snr_in_db=0.5, p=0.5),
], p=0.5),
]
)
return transforms还有一点就是预加重,预加重可以增强高频部分。
pre_emphasis = 0.97
y = np.append(y[0], y[1:] - pre_emphasis * y[:-1])注意librosa的logmelspec特征并没有预加重的步骤
4.Model
看前几名的模型一般使用参数小的CNN架构或者SED架构,也可以尝试CNN+LSTM或Vision Transformer以及一些新模型,先从CNN上手吧,可以直接调用torchvision的model
from torchvision.models import resnet34更多的resnest,resnext,efficientnet,mobilenet等等
注意所有模型均在 5 秒片段上进行训练
5.训练阶段
optimizer = Adam(model.parameters(), lr=lr)
#optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
loss_fct = nn.BCEWithLogitsLoss(reduction="mean").cuda()
#loss_fct = nn.CrossEntropyLoss().cuda()
train_loader = DataLoader(
train_dataset, #增强之后的数据 后面再进行mixup
batch_size=batch_size,
shuffle=True,
pin_memory=True,
drop_last=True,
num_workers=NUM_WORKERS,
)
val_loader = DataLoader(
val_dataset, batch_size=val_bs, pin_memory=True,shuffle=False, num_workers=NUM_WORKERS
)
#实现在训练过程中自适应地调整学习率
#学习率的衰减方式是先进行热身(warmup)阶段,在这个阶段内学习率会逐渐增加到一个较大的值,然后进入线性衰减阶段,学习率会逐渐减小到一个较小的值。
num_warmup_steps = int(warmup_prop * epochs * len(train_loader)) #warmup的训练步数
num_training_steps = int(epochs * len(train_loader)) #总的训练步数
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps, num_training_steps
)optimizer:SGD,Adam,AdamW等等
loss:BCELoss,Focal loss,CrossEntropyLoss等等,也可以组成加权loss
scheduler:余弦退火,warmup等等
6.一些其他有效的策略
知识蒸馏,模型集成,预训练,转onnx加速推理,OpenVino加速,StratifiedKFold
#转成onnx
import torch
from torchvision import models
from model.models import get_model
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
save_folder = "../checkpoint/resnext50_32x4d_one_0.pt" # 模型保存地址
#model = Efficientnet(pretrained=True) # 模型初始化
model = get_model("resnext50_32x4d", num_classes=130)
model.eval() # 模式设置
state_dict = torch.load(save_folder, map_location=torch.device('cpu')) # 读取模型参数
model.load_state_dict(state_dict) # 加载模型参数
# model = torch.load('../checkpoint/resnest50_fast_1s1x64d_double_0.pt', map_location=torch.device('cpu'))
# model = model.eval().to(device)
x = torch.randn(1, 3, 256, 256).to(device)
with torch.no_grad():
torch.onnx.export(
model, # 要转换的模型
x, # 模型的任意一组输入
'resnest50_fast_1s1x64d.onnx', # 导出的 ONNX 文件名
opset_version=11, # ONNX 算子集版本
input_names=['input'], # 输入 Tensor 的名称(自己起名字)
output_names=['output'] # 输出 Tensor 的名称(自己起名字)
)
import onnx
# 读取 ONNX 模型
onnx_model = onnx.load('resnest50_fast_1s1x64d.onnx')
# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)
print('无报错,onnx模型载入成功')
print(onnx.helper.printable_graph(onnx_model.graph))转成onnx也可以部署到本地服务器或者网站上进行预测 ,部署app或者板子上
7.后期处理
如果音频文件中某个类别的任何预测值超过 0.96,我们尝试将该类别的置信度提高 1.5 倍。
根据上一个和下一个5s片段调整置信度。
8.可视化
这块主要是论文里看到的,画一些混淆矩阵,PR曲线,计算AUC,ROC等等
def cnf_matrix_plotter(cm, classes, cmap=plt.cm.Blues):
"""
传入混淆矩阵和标签名称列表,绘制混淆矩阵
"""
plt.figure(figsize=(10, 10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
# plt.colorbar() # 色条
tick_marks = np.arange(len(classes))
plt.title('混淆矩阵', fontsize=30)
plt.xlabel('预测类别', fontsize=20, c='r')
plt.ylabel('真实类别', fontsize=20, c='r')
plt.tick_params(labelsize=12) # 设置类别文字大小
plt.xticks(tick_marks, classes, rotation=90) # 横轴文字旋转
plt.yticks(tick_marks, classes)
# 写数字
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
fontsize=12)
plt.tight_layout()
plt.savefig('混淆矩阵.pdf', dpi=300) # 保存图像
plt.show()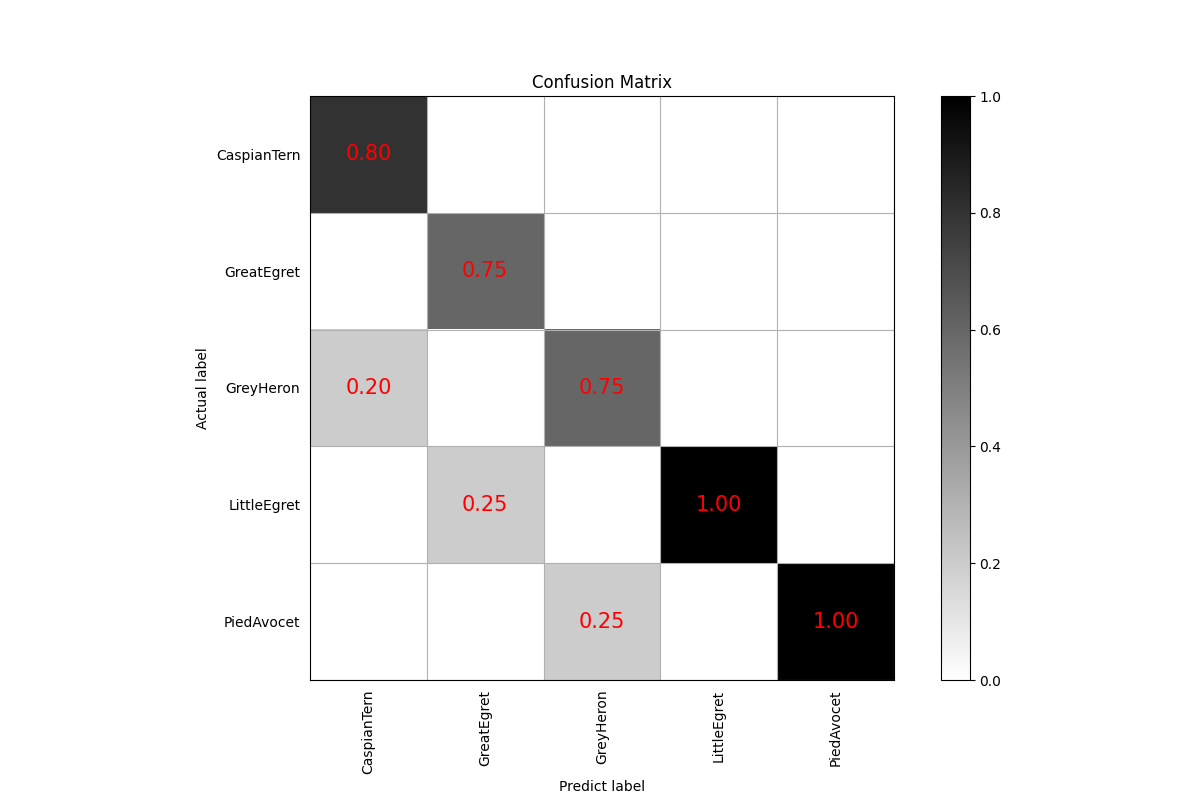
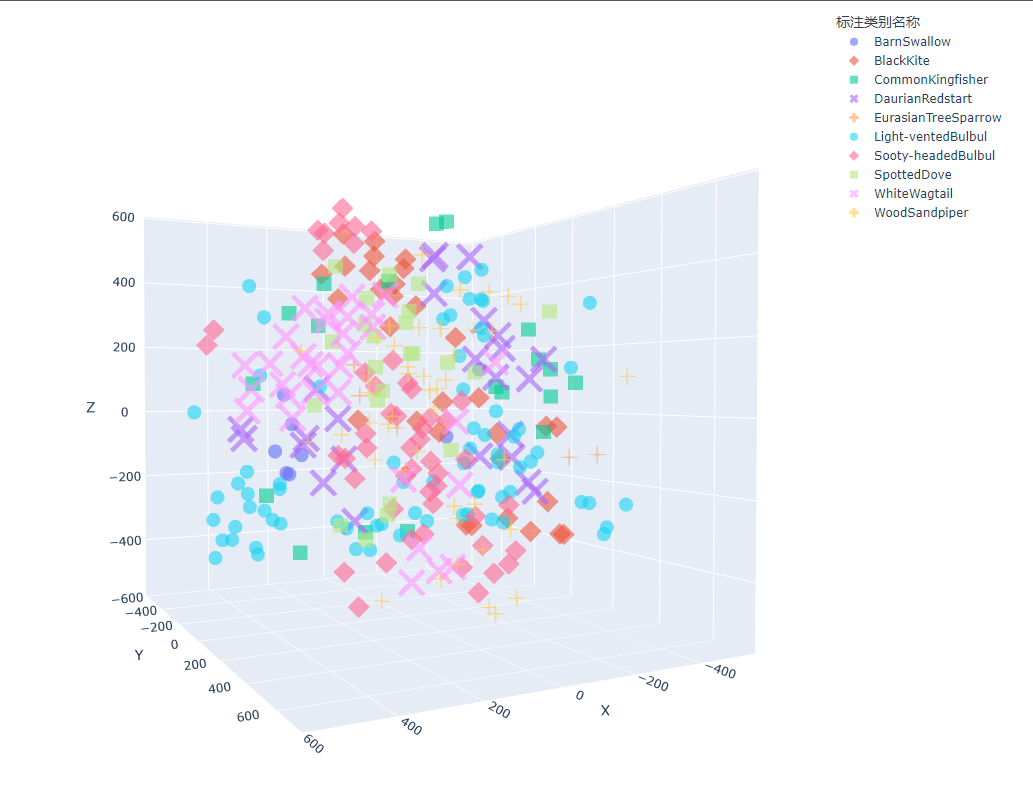
也可以提取语义特征t-SNE进行降维可视化
大概就这么多吧总结之前一段时间学到的知识,后面想到了再补充,有一些错误的话欢迎指出

















 2814
2814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









