







论文题目:用于单通道语音增强的双路径卷积递归网络DPCRN
1.Abstract
双路径 RNN (DPRNN) 的提出是为了更有效地对时域中用于语音分离的极长序列进行建模。通过将长序列拆分为更小的块并应用块内和块间 RNN,DPRNN 在有限模型大小的语音分离方面取得了令人鼓舞的性能。在本文中,我们将 DPRNN 模块与卷积递归网络 (CRN) 相结合,设计了一种称为双路径卷积递归网络 (DPCRN) 的模型,用于时频域中的语音增强。我们用 DPRNN 模块替换 CRN 中的 RNN,其中块内 RNN 用于对单个帧中的频谱模式进行建模,块间 RNN 用于对连续帧之间的依赖性进行建模。提交的 DPCRN 模型仅使用 0.8M 参数,在 Interspeech 2021 深度噪声抑制 (DNS) 挑战的宽带场景赛道中获得了 3.57 的总体平均意见得分 (MOS)。对其他一些测试集的评估也显示了我们模型的有效性。
2.Introduction
作为一种数据驱动的监督学习方法,基于 DNN 的语音增强主要分为时频域和时域方法。时频 (T-F) 域方法旨在从嘈杂语音的特征中提取干净语音的声学特征(例如,复谱或对数功率谱)。常见的训练目标包括理想比率掩码(IRM)和目标幅度谱(TMS)等。相位谱也被认为有利于语音质量。然而,由于其非结构化特性,很难直接估计相位谱。相敏掩模 (PSM)被提议利用相位信息进行语音增强。最近的方法,例如 PHASEN,利用幅度和相位谱之间的相互联系来进行更好的相位估计。其他一些方法通过优化复谱的实部和虚部或估计复比率模板 (CRM)来隐式检索相位。由于复值权重适用于对频谱的固有信息进行建模,复值神经网络也被用于语音增强。
时域方法通过端到端的训练直接估计干净的语音波形,避免了在T-F域估计相位信息的麻烦。
作为时域中的典型方法,Conv-Tasnet利用一维卷积神经网络 (Conv-1D)作为编码器将时域波形转换为有效的表示形式,以进行有效的干净语音估计,并且然后通过称为解码器的转置卷积层将表示转换回波形。时域方法难以对极长序列进行建模,因此必须使用像wave-u-net这样的非常深的卷积层来进行特征压缩。传统的循环神经网络 (RNN) 也无法有效地对如此长的序列进行建模。双路径递归神经网络 (DPRNN)被提出来解决这个问题,其中长序列特征被分成更小的块,并由块内和块间 RNN 迭代处理,减少要处理的序列的长度对于每个 RNN。
最近提出了一种称为卷积循环网络(CRN)的网络结构。利用 CNN 和 RNN 的优势,CRN 不仅可以捕获频谱图的局部模式,还可以对连续帧之间的依赖关系进行建模。在本文中,我们在 T-F 域中结合了 DPRNN 和 CRN。在CRN的基础上,提出了一种称为双路径卷积循环网络(DPCRN)的新模型。DPCRN 也使用了两种 RNN。intra-chunk RNN 用于对单个时间帧的频谱进行建模,而 inter-chunk RNN 用于对频谱随时间的变化进行建模。
3.DPRNN Model学习
将输入序列拆分为更短的块,并交织两个 RNN,一个块内 RNN 和一个块间 RNN,分别用于局部和全局建模。在 DPRNN 块中,块内 RNN 首先独立处理本地块,然后块间 RNN 聚合来自所有块的信息以执行话语级处理。与时间卷积网络 (TCN) 等基于 CNN 的架构相比,由于固定感受野仅执行局部建模,DPRNN 能够通过块间 RNN 充分利用全局信息并实现卓越性能更小的模型尺寸。
双路径 RNN (DPRNN) 由三个阶段组成:分割、块处理和重叠添加。分割阶段将顺序输入拆分为重叠的块,并将所有块连接成一个 3-D 张量。然后将张量传递给堆叠的 DPRNN 块,以交替方式迭代应用局部(块内)和全局(块间)建模。最后一层的输出使用重叠相加方法转换回顺序输出。下图显示了该模型的流程图。
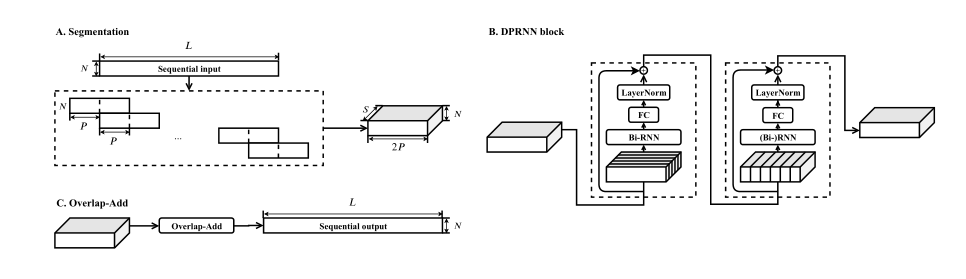
这是双路径循环神经网络(DPRNN)的系统流程图。 (A) 分割阶段将顺序输入拆分为有或没有重叠的块,并将它们连接起来形成 3-D 张量。在我们的实现中,重叠率设置为 50%。 (B) 每个 DPRNN 块由两个在不同维度上具有循环连接的 RNN 组成。块内双向 RNN 首先并行应用于各个块以处理局部信息。然后跨块应用块间 RNN 以捕获全局依赖性。可以堆叠多个块以增加网络的总深度。 (C) 最后一个 DPRNN 块的 3-D 输出通过对块执行重叠相加转换回顺序输出。
1)Segmentation分割模块
对于顺序输入 W ∈ ,其中 N 是特征维度,L 是时间步数,分割阶段将 W 分成长度为 K 和跳跃大小为 P 的块。第一个和最后一个块被零填充,以便 W 中的每个样本出现并且只出现在 K/P 个块中,生成 S 个大小相等的块
, s = 1, . . . S. 然后将所有块连接在一起形成一个 3-D 张量 T = [
, . . .
]
。
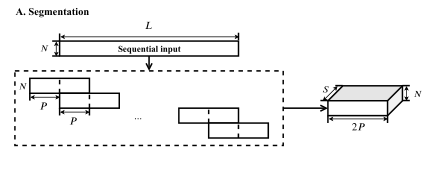
这里K=2P,把S个块连接起来就是一个三维块
2)Block processing块处理模块
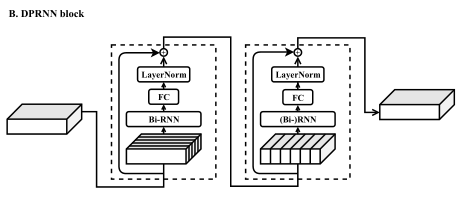
每个块包含两个子模块,分别对应块内和块间处理。
将分割模块的输出T传递到 B 个 DPRNN 块的堆栈,首先输入到块内RNN的数据记为
,b = 1 , 2 , . . . , B ,其中
=
。块内RNN是双向的,并应用于 Tb 的第二维(K是第一维,S为第二维,K和S就分别代表了intra-chunk和inter-chunk的RNN的长度信息,表示处理的是块内的还是块间的),即作用于单个混合语音块相当于是
,
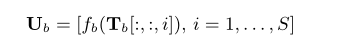
其中是RNN的输出,
(·)是RNN定义的mapping映射函数,
[:, :, i]
是定义序列
再通过一个线性全连接 (FC) 层,就是改变信息维度,即将
的特征维度转换回
的特征维度
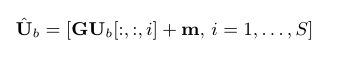
其中 是变换后的特征,
和
分别是 FC 层的权重和偏置,
[:, :, i]
表示
中的第i个S维度的块。
再通过归一化 LN层应用于
,可以很好增加模型的泛化能力
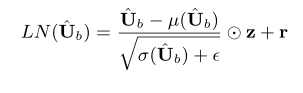
其中 z, r 是重新缩放因子,
是数值稳定性的小正数(用来防止分母为0),并且
表示 Hadamard 点积。 µ(·) 和 σ(·) 分别是3维张量的均值和方差,他们的求法如下:
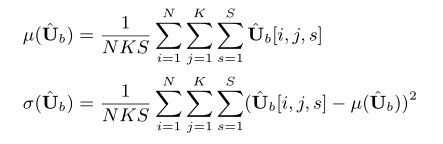
最后通过一个残差连接得到输出
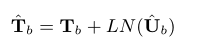
块内RNN的输出作为块间RNN的输入,块间RNN由于需要对全局序列进行建模,因此在在混合语音块的时间维度上进行操作,由于RNN是双向的,因此中的每个时间步都包含它所属区块的全部信息,这使得块间RNN能够执行完全序列级建模。对于块间处理步骤也是一样,在K维度上进行处理。
3)Overlap-Add重叠相加模块

最后一个 DPRNN 块的输出表示为 ,应用重叠添加方法恢复成语音波形输出Q
。
4.DPCRN Model学习
DPRNN 中的块内操作也适用于频域,具有充分利用语音频谱结构的潜在好处。通过结合 DPRNN 和 CRN,可以获得 T-F 域中表现良好的模型。与原始 DPRNN 类似,我们的模型由编码器、双路径 RNN 模块和解码器组成,如下图(a) 所示。编码器和解码器的结构类似于CRN。我们将噪声信号的复杂频谱图的实部和虚部作为两个流发送到编码器。编码器使用二维卷积 (Conv-2D) 层从嘈杂的频谱图中提取局部模式并降低特征分辨率。解码器使用转置卷积层将低分辨率特征恢复到原始大小,与编码器形成对称结构。编码器和解码器之间存在跳过连接以传递详细信息。每个卷积层后跟一个批量归一化和一个 PReLU 函数。我们用 DPRNN 模块替换 CRN 的 RNN 部分,如下图(b) 所示。与原始的 DPRNN 不同,我们将 STFT 中的帧视为 DPRNN 处理的块。不是学习时域中的依赖性,而是应用块内 RNN 对单个帧中的光谱模式进行建模。我们认为,由于语音的谐波结构,对频率的依赖性进行建模有利于语音增强。 RNNs 可以克服 CNNs 有限感受野的缺点,捕捉长期的谐波相关性。至于interchunk RNNs,我们使用LSTM来模拟某个频率的时间依赖性,这样可以保证严格的因果关系。
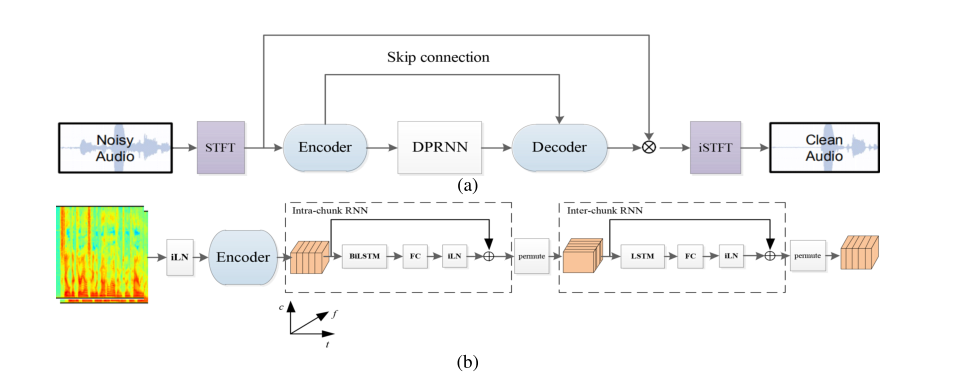
这些 LSTM 是并行计算的。 BiLSTM 用于块内建模,不会影响整个系统的因果关系。 LSTM 和 BiLSTM 之后是全连接层 (FC) 和层归一化 (LN)。然后在 RNN 的输入和 LN 的输出之间应用残差连接,以进一步缓解梯度消失问题。
我们在模型中使用即时层归一化 (iLN),而不是普通的 LN,其中所有帧在频率轴 f 和通道轴 c 上独立计算统计数据,并共享相同的可训练参数。将 表示为第 t 帧的特征矩阵,N 和 K 表示 f 和 c 的特征维度,
和
表示均值和方差算子,
和
可训练参数,
为正则化参数,那么在时间索引 t 处的特征的 iLN 定义为:
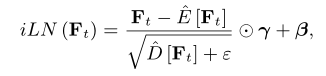
其中两个函数:
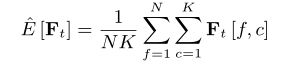
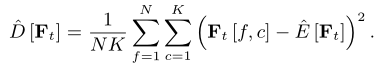
为了降低模型输出对输入信号能量的敏感性,我们还在输入频谱图上应用了 iLN。
5.Learning Target and Loss function
本文DPCRN 的学习目标是 CRM。 CRM 的实部和虚部作为两个流从解码器输出。在训练阶段,学习目标通过信号逼近(SA)进行优化。将噪声语音的频谱图 与估计的 mask掩蔽
相乘,然后我们可以得到增强后的频谱:
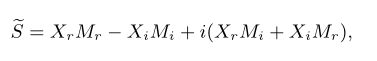
再使用逆 STFT (iSTFT) 将其转换回波形。
![]()
本文使用两个损失函数进行比较:
第一个损失函数 f 是负信噪比 (SNR),其定义为:
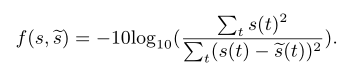
与常用的标度不变信噪比(SI-SNR)相比,它可以约束输出的幅度,避免输入和输出之间的电平偏移,这对实时处理很重要。考虑到频谱图质量,我们将频谱图的均方误差 (MSE) 添加到负 SNR 中,得到第二个损失函数,其定义为:
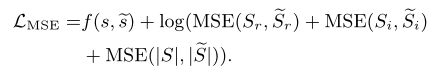
添加的MSE损失由三部分组成,分别衡量估计谱图与真实谱图之间的实部、虚部和幅度的差异。我们取 MSE 损失的对数以确保它与负 SNR 具有相同的数量级。
6.Conclusions
受 DPRNN 和 CRN 成功应用的启发,我们提出了一种基于深度学习的时频域语音增强模型,命名为 DPCRN。它结合了CNN的局部模式建模能力和DPRNN的长期建模能力。与 CRN 相比,DPCRN 展示了 RNN 在频谱建模方面的优势。只有 0.8M 参数,我们的模型在各种未知噪声数据集上取得了有竞争力的结果。未来,我们将尝试降低更宽频带频谱处理模型的计算复杂度。















 6033
6033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









