







一. 函数
1.cv2.dnn.readNetFromCaffe(prototxt, model)
用于进行SSD网络的caffe框架的加载,参数说明:prototxt表示caffe网络的结构文本,model表示已经训练好的参数结果。
2.t=delib.correlation_tracker()
使用delib生成单目标的追踪器
3.delib.rectangle(int(box[0]), int(box[1]), int(box[2]), int(box[3]))
用于生成追踪器所需要的矩形框[(startX, startY), (endX, endY)]
4.get()语法
dict.get(key, default=None)
参数
key -- 字典中要查找的键。
default -- 如果指定键的值不存在时,返回该默认值。
返回值
返回指定键的值,如果键不在字典中返回默认值 None 或者设置的默认值。
5. if name == ‘main’:
https://blog.csdn.net/weixin_44920757/article/details/116091745?spm=1001.2014.3001.5501
6. cv2.VideoWriter(filename, fourcc, fps, frameSize[, isColor])
将图片序列保存成视频文件,也可以修改视频的各种属性,还可以完成对视频类型的转换
cv2.VideoWriter(filename, fourcc, fps, frameSize[, isColor])
filename 是要保存的文件路径
fourcc 指定编码器
fps 要保存的视频的帧率
frameSize 要保存的文件的画面尺寸
isColor 指示是黑白画面还是彩色的画面
例子:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30, (frame.shape[1], frame.shape[0], True))
7. Python len() 方法返回对象(字符、列表、元组等)长度或项目个数。
8. v2.dnn.blobFromImage 和 cv2.dnn.blobFromImages
cv2.dnn.blobFromImage 和 cv2.dnn.blobFromImages功能差不多,
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size, mean, swapRB=True,crop=False,ddepth = CV_32F )
1.image,这是传入的,需要进行处理的图像。
2.scalefactor,执行完减均值后,需要缩放图像,默认是1,需要注意,
3.size,这是神经网络真正支持输入的值。也就是输出图像的空间尺寸,如size=(200,300)表示高h=300,宽w=200。
4.mean,这是我们要减去的均值,可以是R,G,B均值三元组,或者是一个值,每个通道都减这值。如果执行减均值,通道顺序是R、G、B。 如果,输入图像通道顺序是B、G、R,那么请确保swapRB = True,交换通道。
5.swapRB,OpenCV认为图像 通道顺序是B、G、R,而减均值时顺序是R、G、B,为了解决这个矛盾,设置swapRB=True即可。
6.crop,如果crop裁剪为真,则调整输入图像的大小,使调整大小后的一侧等于相应的尺寸,另一侧等于或大于。然后,从中心进行裁剪。如果“裁剪”为“假”,则直接调整大小而不进行裁剪并保留纵横比。
7.ddepth, 输出blob的深度,选则CV_32F or CV_8U。
- 返回值:
返回一个4通道的blob(blob可以简单理解为一个N维的数组,用于神经网络的输入)
在此案例中,均值均为127.5(255/2),所以减去均值后得到的所有像素值都位于-127.5到127.5之间,为了归一化,缩放比例应为1/127.5=0.007843。
cv2.dnn.blobFromImage函数返回的blob是我们输入图像进行随意从中心裁剪,减均值、缩放和通道交换的结果。cv2.dnn.blobFromImages和cv2.dnn.blobFromImage不同在于,前者接受多张图像,后者接受一张图像。多张图像使用cv2.dnn.blobFromImages有更少的函数调用开销,你将能够更快批处理图像或帧。
8. detections = net.forward()
理解:
对图片中的所有物体进行检测,得到的结果中包含三个信息:
- 这是什么物体。
- 是这个物体的可能性。
- 这个物体相对于整张图片的位置。
其返回值是一个四维数组,形式为(1, 1, n, 7)。
- n表示在这张图片中共检测到了n个物体。
- 最后一维有7列:
- 其中第一列都是0,没有什么意义,
- 第二列表示检测到的物体类别,
- 第三列表示检测到是该物体的可能性,
- 第四到七列表示包含该物体的方框相对于整张图片的位置(不是在图中的实际位置)
- 包含该物体的方框在图中的实际位置:
- 左上角横坐标:第四列乘以整张图片的宽度,
- 左上角纵坐标:第五列乘以整张图片的高度,
- 右下角横坐标:第六列乘以整张图片的宽度,
- 右下角纵坐标:第七列乘以整张图片的高度。
详见:
https://blog.csdn.net/qq_36758914/article/details/104062419
https://blog.csdn.net/cvnlixiao/article/details/85163611
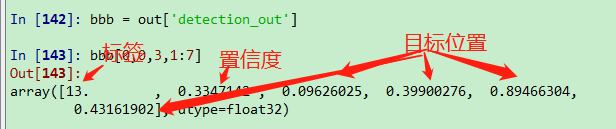
在最后一维,第二个开始依次是:标签、置信度、目标位置的4个坐标信息[xmin ymin xmax ymax]
倒数第二维是识别的标签的数量,图中选择显示第4个标签的信息
9. np.arange()
np.arange()
#一个参数 默认起点0,步长为1 输出:[0 1 2]
a = np.arange(3)
#两个参数 默认步长为1 输出[3 4 5 6 7 8]
a = np.arange(3,9)
#三个参数 起点为0,终点为3,步长为0.1 输出[ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9]
a = np.arange(0, 3, 0.1)
10. astype 修改数据类型
使用df.astype()强制类型转换,df[‘col’]=df[‘col’].astype(‘float’)
SSD是一种目标检测的算法,其使用多个卷积层进行预测,原理在后续的博客中进行补充
对于目标追踪的视频,我们先使用SSD找出图片中人物的位置,然后使用dlib中的跟踪器对物体进行跟踪
由于每一个人物框对应一个跟踪器,因此我们可以对每一个跟踪器起一个进程,使用输入和输出线程,用于构造多进程
使用的数据,需要一个训练好的SSD权重参数,还需要caffe关于SSD的prototxt文件
代码说明:
下面的代码可以近似认为是由两部分构成
第一部分:使用SSD网络进行预测,获得box的位置
第二部分:使用dlib构造tracker跟踪器,带入box构造带有矩形框的追踪器,然后使用dlib的追踪器对图像每一帧的位置进行追踪
代码:
第一步:构造进程函数,使用iq.get 和oq.put进行追踪器的位置更新
第二步:构造输入的参数, 使用cv2.dnn.readNetFromCaffe()构造SSD网络模型
第三步:使用cv2.Videocapture视频读入,fps=FPS().start() 用于计算FPS
第四步:进入循环,使用.read()读取图片
第五步:使用cv2.resize()对图片大小进行放缩变化,使用cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #将读入的BGR转换为RGB,用于模型的预测
第六步:如果需要进行输出,使用cv2.VideoWriter实例化视频存储器
第七步:如果还没有使用SSD获得矩形框,使用cv2.dnn.blobFromImage对图像进行归一化操作
第八步:使用net.setInput将图片传入,使用net.forward获得前向传播输出的结果
第九步:如果置信度大于给定的置信度,获得SSD的标签,以及前向传播的位置信息
第十步:使用multiprocessing.Queue构造线程iq和oq,将线程添加到列表中,使用multiprocessing.process构造多进程,用于分别建立单个跟踪器
第十一步:如果已经生成了通道,使用iq.put(rgb)传入图像,使用oq.get()获得追踪器更新的位置
第十二步:进行画图操作,如果存在writer就进行写入
第十三步:更新fps.update
第十四步:统计运行的时间和FPS,并对vs进行释放内存
from utils import FPS
import multiprocessing
import numpy as np
import argparse
import dlib
import cv2
#perfmon
def start_tracker(box, label, rgb, inputQueue, outputQueue):
t = dlib.correlation_tracker()
rect = dlib.rectangle(int(box[0]), int(box[1]), int(box[2]), int(box[3]))
t.start_track(rgb, rect)
while True:
# 获取下一帧
rgb = inputQueue.get()
# 非空就开始处理
if rgb is not None:
# 更新追踪器
t.update(rgb)
pos = t.get_position()
startX = int(pos.left())
startY  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3336
3336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









