







1.基本概念
元算法/集成算法:不同分类器(算法)组合起来的结果。
非均衡分类:样例数目不均衡的数据进行分类。
2.AdaBoost(adaptive boosting)-自适应boosting缩写
优点:泛化错误率低,易编码,可以应用在大多数分类器上,无参数调整。
缺点:对离群点敏感。
适用数据类型:数值型和标称型数据
3. Bagging和Boosting的定义
相同点:
Baggging 和Boosting都是模型融合的方法,可以将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好。
Bagging(Bootstrap aggregating,引导聚集算法/套袋法bagging-基于数据随机重抽样的分类器构建方法:
其算法过程如下:
给定一个大小为n的训练集D,Bagging算法从中均匀、有放回地(即使用自助抽样法)选出m个大小为n’的子集Di,作为新的训练集。在这m个训练集上使用分类、回归等算法**,则可得到m个模型,再通过取平均值、取多数票等方法,即可得到Bagging的结果。
(1)从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
(2)每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
(3)对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
Boosting:
AdaBoosting方式每次使用的是全部的样本,每轮训练改变样本的权重。下一轮训练的目标是找到一个函数f 来拟合上一轮的残差。当残差足够小或者达到设置的最大迭代次数则停止。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大)
梯度提升的Boosting方式是使用代价函数对上一轮训练出的模型函数f的偏导来拟合残差。
4.Bagging和Boosting的区别(4个)是什么?
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
5.AdaBoost运行过程
弱分类器:分类器的性能比随机猜测的要略好,但也不会好太多。
运行过程:


6.单层决策树
基本原理:
decision stump,决策树桩(我称它为一刀切),也称单层决策树(a one level decision tree),单层也就意味着尽可对每一列属性进行一次判断。如下图所示(仅对 petal length 进行了判断):
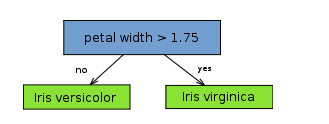
从树(数据结构)的观点来看,它由一个内部节点(internal node)也即根节点(root)与终端节点(terminal node)也即叶子节点(leaves)直接相连。用作分类器(classifier)的 decision stump 的叶子节点也就意味着最终的分类结果。
从实际意义来看,decision stump 根据一个属性的一个判断就决定了最终的分类结果,比如根据水果是否是圆形判断水果是否为苹果,这体现的是单一简单的规则(或叫特征)在起作用。
显然 decision stump 仅可作为一个 weak base learning algorithm(它会比瞎猜 12稍好一点点,但好的程度十分有限),常用作集成学习中的 base algorithm,而不会单独作为分类器。
既然 decision stump 仅可对一个属性进行一次判断获取最终的分类结果,显然我们寻找具有最低错误率的单层决策树。
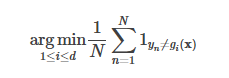
i 表示属性列,N 为样本集的大小,d 为属性列的个数。
转载自:添加链接描述
7.构建单层决策树(基于加权输入值进行决策的分类器)


8.完整Adaboost算法的实现
Adaboost算法输入参数:数据集、类别标签、迭代次数numIt(唯一需要用户指定的参数)
向量D:包含每个数据点的权重。是一个概率分布向量,所有元素之和为1.

9.测试算法,基于Adaboost算法的分类
将弱分类器的训练过程从程序中抽取出来,然后应用到某个具体的应用上。每个弱分类器的结果以及对应alpha作为权重。所有弱分类器加权求和得到最终的结果。
过拟合(过学习):测试错误率达到一个最小值后开始上升
10.非均衡分类问题
1.非均衡分类问题:误判、预测错误的情况如何处理
2.其他分类性度量指标:正确率、召回率、ROC曲线
混淆矩阵:
 正确率:预测为正例的样本中真正正例的比例,公式:TP/(TP+FP)
正确率:预测为正例的样本中真正正例的比例,公式:TP/(TP+FP)
召回率:预测为正例的真实正例占所有正例的比例,公式:TP/(TP+FN)。召回率很大的分类器,真正判错的实例不多。
ROC曲线:意味着接收者操作特征
 ROC曲线,有一条实线一条曲线。当阈值发生变化时假阳率和真阳率的变化情况。不仅可以用于比较分类器,还可以基于效益分析做决策。
ROC曲线,有一条实线一条曲线。当阈值发生变化时假阳率和真阳率的变化情况。不仅可以用于比较分类器,还可以基于效益分析做决策。
左下角的点是将所有样例判为反例的情况,右上角的点是将所有样例判为正例的情况。最佳的分类器应该尽可能地处于左上角。此时假阳率很低真阳率很高。
横轴是伪正例的比例(假阳率=FP/(FP+TN)),纵轴是真正例的比例(假阳率=TP/(TP+FN))。
比较不同ROC曲线–曲线下面积(area under the curve,AUC):AUC给出分类器的平均性能值,不能完全代替对整条曲线的观察。完美分类器AUC是1.0,而随机猜测的AUC是0.5.
**画ROC曲线:**必须提供每个样例被判为阳性或者阴性的可信程度值。
1.将分类样例按照其预测强度排序。先从排名最低的样例开始,所有排名更低的样例都被判为反例,而所有排名更高的样例都被判为正例。对应点(1.0,1.0)
2.将其移到排名次低的样例中去,如果该样例为正例,那就对真阳率进行修改;如果该样例为反例,那就对假阴率进行修改。
11.基于代价函数的分类器决策控制
处理非均匀分类代价问题:调节分类器的阈值,代价敏感学习(cost-sensitive learning)


12.处理非均匀问题的数据抽样方法
对分类器的训练数集进行改造,可通过欠抽样(删除样例)或过抽样(复制样例)来实现。


















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









